






搬了这么个东东来~~ 不过他的名字有点容易叫大家混淆,所以没写标题上...
在训练阶段,只需少量的二维方框标注作为指导,本文的网络就可以从激光雷达方框中产生精确的具有三维属性的图像级长方体标注。
论文:https://arxiv.org/pdf/2211.09302.pdf
基于图像的三维目标检测任务要求预测的三维bounding box具有“紧密”投影(也称为长方体),在保持三维空间几何属性(如物理尺寸、两两正交等)的同时,很好地拟合图像上的目标轮廓,这些要求给标注带来了重大挑战。简单地将Lidar Labeled三维方框投影到图像上会导致严重的不对齐,而直接在图像上绘制长方体则无法获得原始的三维信息。
在这项工作中,作者提出了一种基于学习的三维框自适应方法,该方法自动调整360°激光雷达三维bounding box的最小参数,以完美地适应全景相机的图像外观。在训练阶段,只需少量的二维方框标注作为指导,本文的网络就可以从激光雷达方框中产生精确的具有三维属性的图像级长方体标注。
本文的方法叫做“你只标注一次”(you only label once),<看吧这个名字是不是好疼~~~>意思是在点云上标注一次,自动适应周围所有摄像头。据本文所知,本文是第一个专注于图像级的长方体细化,它很好地平衡了精度和效率,大大减少了精确的长方体标注的标注工作量。在Waymo和Nuscenes公共数据集上的大量实验表明,该方法可以在不需要人工调整的情况下对图像进行人眼级的长方体标注。
主要贡献:
- 引入碰撞关系解决基于激光雷达bounding box的3D-2D对齐问题,使长方体精化过程以端到端的方式运行。
- 提出了一种训练精化网络的半监督方法,以减少训练过程中对groud truth标注的要求。
- 本文的方法是第一个专注于图像级的长方体自适应。该精化结果可作为基于二维图像的单目三维检测等感知任务的groud truth。
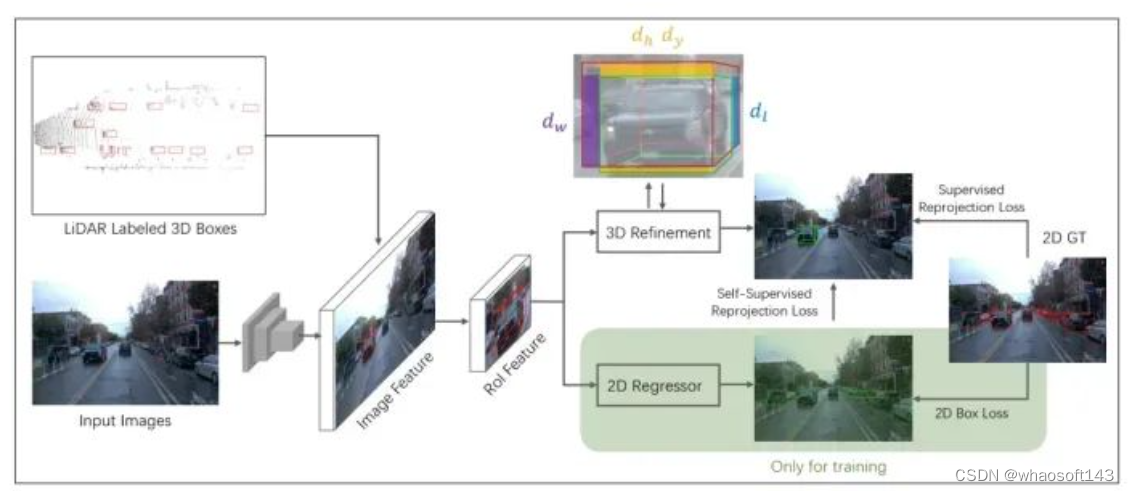
图3 本文网络的框架。
本文使用Faster-RCNN骨干(RESNET50)从输入的2D图像中提取金字塔特征图,并使用3D激光雷达标注作为剪裁相应特征的建议。然后,这些特征被馈送到两个独立的分支,用于精炼的2D boxes 和精炼的3D长方体。2D分支仅用于辅助训练,不会参与最终推断。
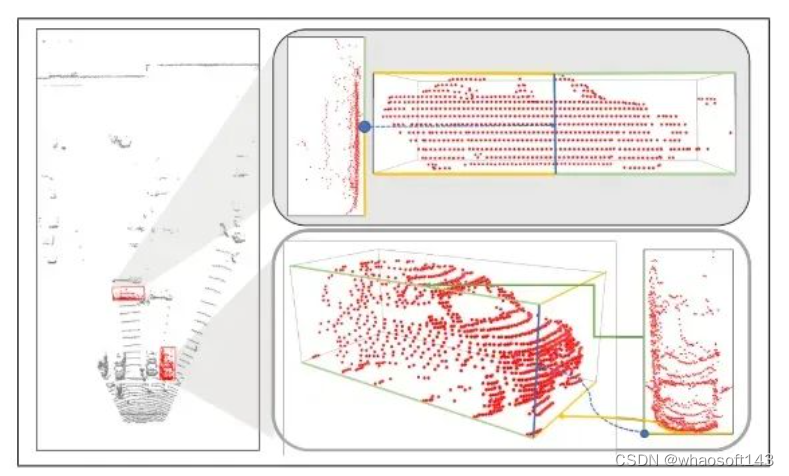
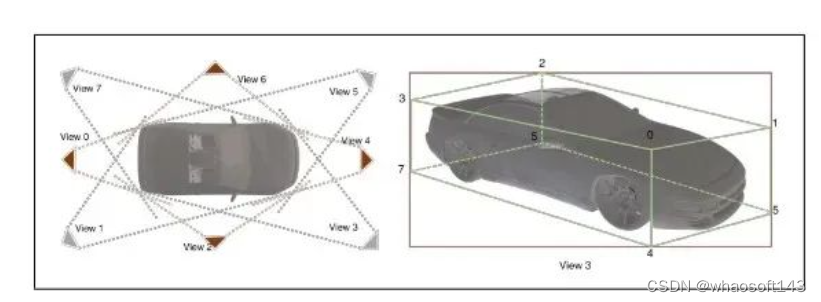
图5 左:本文将相机-目标关系划分为八个不同的视图,并通过投影的2D框计算视图。右:投影的2D框和3D视图3之间的对应关系。二维框的x坐标被三维角3、7和角1、5分割。
实验结果:
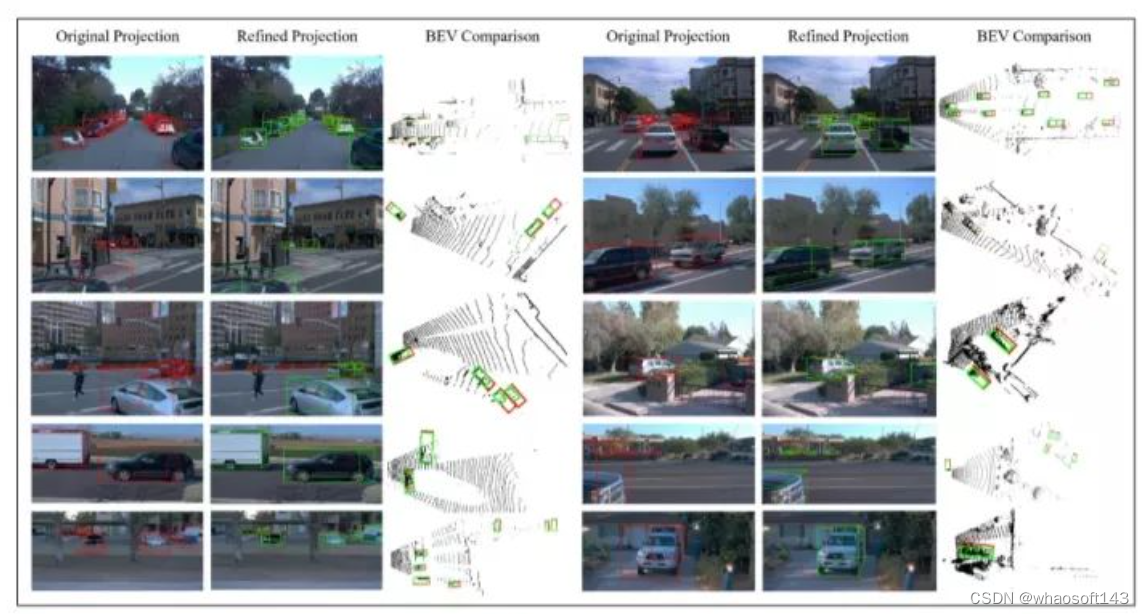
图6 Waymo数据集上的精化结果。
本文用红色标记细化前的3D边界框,用绿色显示优化后的结果。为了更好地显示精化前后的比较,本文在优化的三维长方体上额外绘制了原始的三维投影。
本文还在BEV视图中画出了结果,以表明本文改进的boxes在几何上仍然是合理的。从上到下,本文显示了来自前、左、右、左后和右后摄像头的结果。
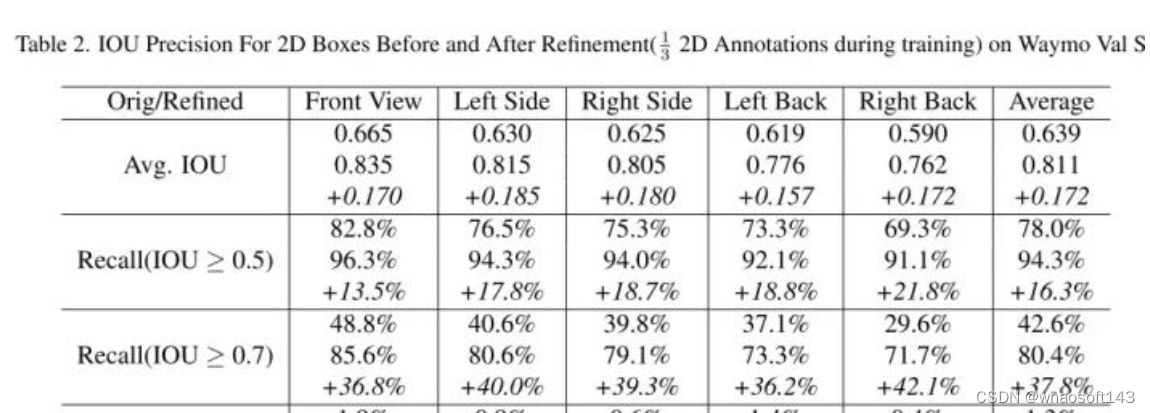
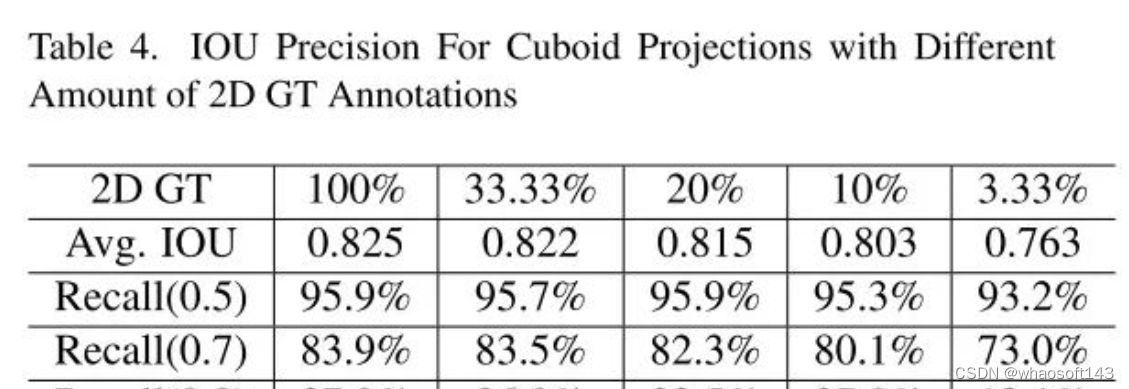
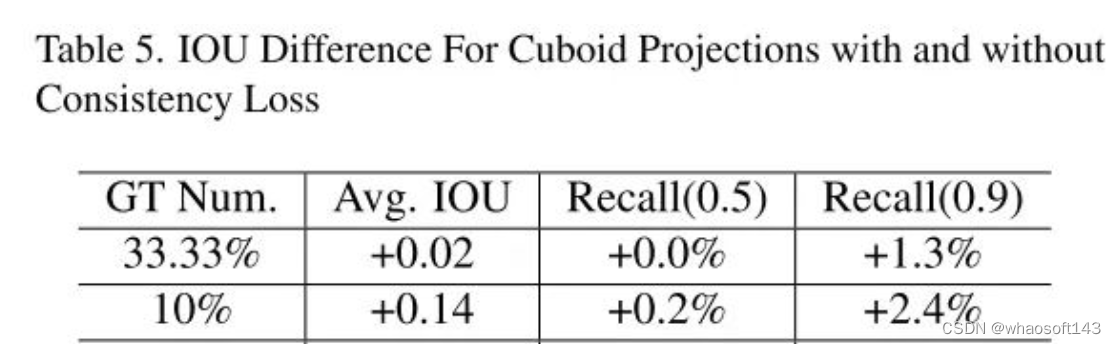
好短结束啊~~















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









