






上周一篇发布于arXiv的CVPR 2019 Oral论文引起了广泛的关注,来自香港中文大学与加州大学伯克利分校的研究学者重新思考了真实世界的视觉识别类别分布的本质,提出了一种全新的视觉识别新范式:开放世界下的大规模长尾识别,并提出了应对此问题的算法,取得了很不错的效果,并开源了代码。本文是论文原作者对该工作的介绍,欢迎大家Follow。
论文作者信息:

Ziwei Liu*, Zhongqi Miao*, Xiaohang Zhan, Jiayun Wang, Boqing Gong, Stella X. Yu, Large-Scale Long-Tailed Recognition in an Open World, CVPR 2019
Oral
. (CUHK & UC Berkeley)
感谢各位作者的优秀工作~
引言
我们所置身的视觉世界在本质上是
长尾(
long-tailed
)
且
开放(
open-ended
)
的:(1)我们日常生活中遇到的物体类别频率通常都符合长尾分布,包含一些经常出现的通用类别和更多较少出现的稀有类别。(2)在不断探索这个开放世界的过程中,我们还会一直遇到各种各样全新的视觉概念。
问题
尽管我们在真实自然场景下遇到的视觉数据分布是一个包含“头部类别”(head class,经常出现的通用类别),“尾部类别”(tail class,较少出现的稀有类别)和“开集类别”(open class,全新的视觉概念)的连续光谱,但是当今的计算机视觉领域仅仅关注于这个光谱中的一个方面,无法全面衡量一个视觉系统的真正性能。比如,大规模图像识别仅仅关注于“头部类别”,而小样本学习仅仅关注于“尾部类别”,如图1所示。
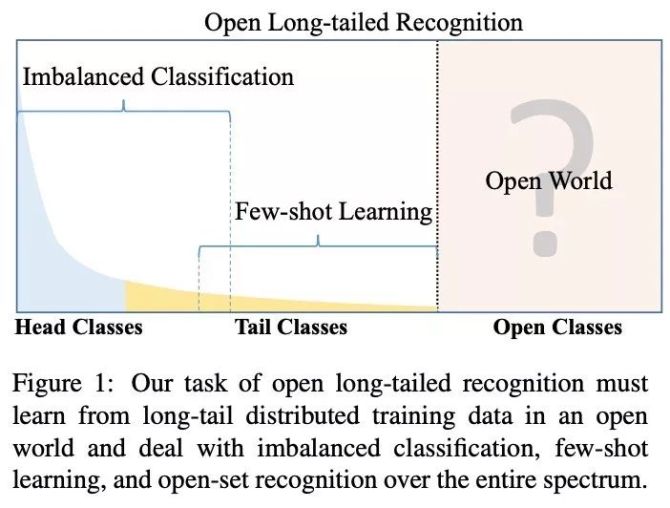
图1:在本文中,我们提出一个新的视觉识别范式——“开放长尾识别”(open long-tailed recognition, OLTR)。这个新的视觉识别范式融合了现有计算机视觉中的非平衡数据分类(imbalanced classification),小样本学习(few-shot learning)和开集识别等任务(open-set recognition)。
在本文中,我们提出一个新的视觉识别范式——“开放长尾识别”(open long-tailed recognition, OLTR)。这个视觉识别范式更符合我们在真实自然场景下遇到的数据分布。在此范式下,视觉识别系统需要面临以下挑战:(1)对于“尾部类别”的鲁棒性。因为“尾部类别”通常只包含1~20个训练样本,所以此时需要视觉系统能够迁移从“头部类别”学到的知识。(2)对于“开放类别”的敏感性。在训练观察不足的情况下,视觉系统需要有区分“尾部类别”和“开放类别”的能力。(3)对于所有类别的均衡处理。一个良好的视觉系统需要在所有类别上取得性能提升,而不能随着训练的进行而遗忘关于某一些类别的知识。
方法
为了解决这些挑战,我们提出一种融合了记忆模块的元学习网络——动态元嵌入(dynamic meta-embedding)。首先,我们通过卷积神经网络从输入图片中得到一个直接观察特征(direct feature)。然后,我们从学习得到的视觉记忆库(visual memory)中引入记忆联想特征(memory feature)。最后,我们通过比较元嵌入与视觉记忆之间的可达性(reachability calibration)来进行动态调整。
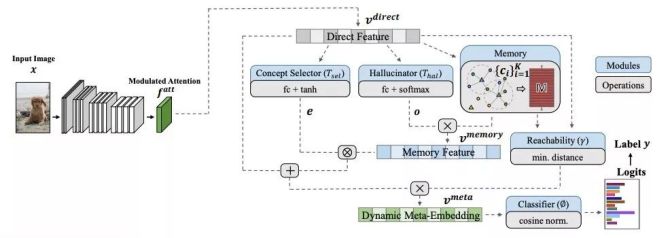
图2:动态元嵌入(dynamic meta-embedding)包含三个主要模块:直接观察特征(direct feature),记忆联想特征(memory feature)和可达性标定(reachability calibration)。
结果
我们提出的动态元嵌入(dynamic meta-embedding)方法在“头部类别”,“尾部类别”和“开集类别”都取得均衡的性能提升,如图3所示。
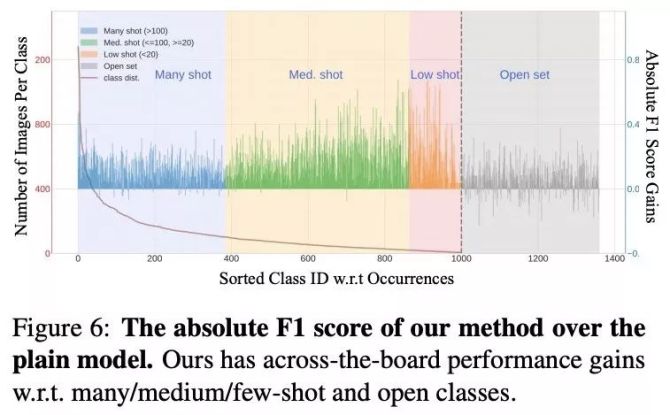
图3:我们提出的动态元嵌入(dynamic meta-embedding)在所有类别上都取得了均衡的性能提升 。
总结
在本文中,我们提出了一个面向真实自然场景下的全新视觉识别范式——“开放长尾识别”(open long-tailed recognition, OLTR)。这个新的视觉识别范式融合了现有计算机视觉中的非平衡数据分类(imbalanced classification),小样本学习(few-shot learning)和开集识别等任务(open-set recognition)。我们相信OLTR可以更全面客观地衡量视觉识别系统的发展,并为计算机视觉走向真实自然场景打下坚实基础。论文、数据集和代码均已开源如下,希望能够帮助各位研究者在这个方向上继续探索和拓展。
论文:
https://arxiv.org/abs/1904.05160
项目主页:
https://liuziwei7.github.io/projects/LongTail.html(欢迎给大佬Star!)
数据集:
https://drive.google.com/open?id=1j7Nkfe6ZhzKFXePHdsseeeGI877Xu1yf
代码:
https://github.com/zhmiao/OpenLongTailRecognition-OLTR















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









