







 本文打算讨论在深度学习中常用的十余种损失函数(含变种),结合PyTorch和TensorFlow2对其概念、公式及用途进行阐述,希望能达到看过的伙伴对各种损失函数有个大致的了解以及使用。本文对原理只是浅尝辄止,不进行深挖,感兴趣的伙伴可以针对每个部分深入翻阅资料。 使用版本:
本文打算讨论在深度学习中常用的十余种损失函数(含变种),结合PyTorch和TensorFlow2对其概念、公式及用途进行阐述,希望能达到看过的伙伴对各种损失函数有个大致的了解以及使用。本文对原理只是浅尝辄止,不进行深挖,感兴趣的伙伴可以针对每个部分深入翻阅资料。 使用版本:
- TensorFlow2.3
- PyTorch1.7.0
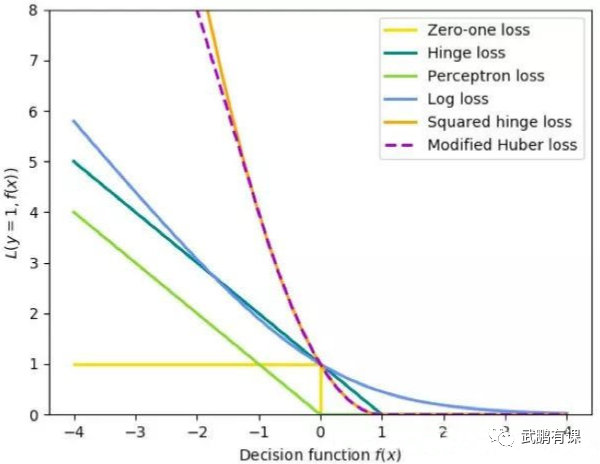
01 交叉熵损失(CrossEntropyLoss)
对于单事件的信息量而言,当事件发生的概率越大时,信息量越小,需要明确的是,信息量是对于单个事件来说的,实际事件存在很多种可能,所以这个时候熵就派上用场了,熵是表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。交叉熵用来描述两个分布之间的差距,交叉熵越小,假设分布离真实分布越近,模型越好。 在分类问题模型中(不一定是二分类),如逻辑回归、神经网络等,在这些模型的最后通常会经过一个sigmoid函数(softmax函数),输出一个概率值(一组概率值),这个概率值反映了预测为正类的可能性(一组概率值反应了所有分类的可能性)。而对于预测的概率分布和真实的概率分布之间,使用交叉熵来计算他们之间的差距,换句不严谨的话来说,交叉熵损失函数的输入,是softmax或者sigmoid函数的输出。交叉熵损失可以从理论公式推导出几个结论(优点),具体公式推导不在这里详细讲解,如下:预测的值跟目标值越远时,参数调整就越快,收敛就越快;
不会陷入局部最优解
 其中,
其中,
 表示样本
表示样本
 的标签,正类为1,负类为0,
的标签,正类为1,负类为0,
 表示样本
预测为正的概率。 多分类交叉熵损失如下:
表示样本
预测为正的概率。 多分类交叉熵损失如下:
 其中,
其中,
 表示类别的数量,
表示类别的数量,
 表示变量(0或1),如果该类别和样本
的类别相同就是1,否则是0,
表示变量(0或1),如果该类别和样本
的类别相同就是1,否则是0,
 表示对于观测样本
属于类别
表示对于观测样本
属于类别
 的预测概率。 Tensorflow:
的预测概率。 Tensorflow:
- BinaryCrossentropy[1]:二分类,经常搭配Sigmoid使用
tf.keras.losses.BinaryCrossentropy(from_logits=False, label_smoothing=0, reduction=losses_utils.ReductionV2.AUTO, name='binary_crossentropy')参数: from_logits:默认False。为True,表示接收到了原始的logits,为False表示输出层经过了概率处理(softmax) label_smoothing:[0,1]之间浮点值,加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。 reduction:传入tf.keras.losses.Reduction类型值,默认AUTO,定义对损失的计算方式。- binary_crossentropy[2]
tf.keras.losses.binary_crossentropy(y_true, y_pred, from_logits=False, label_smoothing=0)参数: from_logits:默认False。为True,表示接收到了原始的logits,为False表示输出层经过了概率处理(softmax) label_smoothing:[0,1]之间浮点值,加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。- CategoricalCrossentropy[3]:多分类,经常搭配Softmax使用
tf.keras.losses.CategoricalCrossentropy(from_logits=False, label_smoothing=0, reduction=losses_utils.ReductionV2.AUTO, name='categorical_crossentropy')参数: from_logits:默认False。为True,表示接收到了原始的logits,为False表示输出层经过了概率处理(softmax) label_smoothing:[0,1]之间浮点值,加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。 reduction:传入tf.keras.losses.Reduction类型值,默认AUTO,定义对损失的计算方式。- categorical_crossentropy[4]
tf.keras.losses.categorical_crossentropy(y_true, y_pred, from_logits=False, label_smoothing=0)参数: from_logits:默认False。为True,表示接收到了原始的logits,为False表示输出层经过了概率处理(softmax) label_smoothing:[0,1]之间浮点值,加入噪声ÿ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









