







机器学习中的评价模型性能的指标
- 混淆矩阵
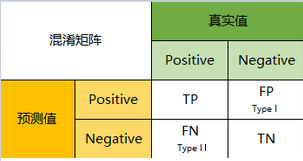
1)根据下面的混淆矩阵,我们可以得到下面几个指标,他们是一级指标:
真实值是positive,模型认为是positive的数量(True Positive=TP) 真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第二类错误(Type II Error)
真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第一类错误(Type I Error)
真实值是negative,模型认为是negative的数量(True Negative=TN)
2)混淆矩阵统计的是个数,对于大量的数据,个数很难衡量模型的优势,因此又延伸了四个二级指标:
A.准确率(Accuracy)—— 针对整个模型
B.精确率(Precision)
C.灵敏度(Sensitivity):就是召回率(Recall)
D.特异度(Specificity)

3)三级指标
这个指标叫做F1 Score。
他的计算公式是:
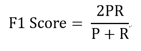
其中,P代表Precision,R代表Recall。
F1-Score指标综合了Precision与Recall的产出的结果。
F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。 - ROC曲线
横坐标为假阳性率(False positive rate,FPR),纵坐标为真阳性率(True positive rate,TPR)。
假阳性率 FPR = FP/N —N个负样本中被判断为正样本的个数占真实的负样本的个数
真阳性率 TPR = TP/P —P个正样本中被预测为正样本的个数占真实的正样本的个数
ROC曲线一定程度上可以反映分类器的分类效果,但是不够直观,为了更直观的显示其分类性能,就有了AUC面积。AUC实际上就是ROC曲线下的面积。AUC直观地反映了ROC曲线表达的分类能力。 - AUC面积
1)只能用于二分类;
2)AUC面积是ROC曲线下方与坐标轴围成的面积;
3)AUC的取值范围:
AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器;
0.5<AUC<1,优于随机猜测,这个分类器(模型)妥善设定阈值的话,能有预测价值;
AUC=0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值;
AUC<0.5,说明模型很差或者代码有问题。
4)由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值一般在0.5~1之间;
5)AUC越大,说明分类器越可能把真正的正样本排在前面,分类性能越好;
6)ROC能够尽量降低不同测试集带来的干扰,更加客观的衡量模型本身的性能。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









