






单规则算法体系
算法体系由多个规则构成,规则之间相互独立,产出结果由规则独立判定。
这种算法体系的好处与应用范围:算法体系结构简单;方便算法改良,比如上新的算法,下线旧算法;可理解性强,所以可控性强。比如,在电商环境里,识别炒信刷单的商品或店铺就适合这样的体系。
数据说明
数据来源于某大型电商平台上的虚假交易用户的识别算法多年前的产出数据(数据已经脱敏)。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import json
from pandas.io.json import json_normalize
from collections import Counter
import pyecharts as pe
from pyecharts import options as opts导入数据:
r1 = pd.read_csv(r't1t1',names=['name','rule','date'],sep='t',parse_dates=[2])
r1.head()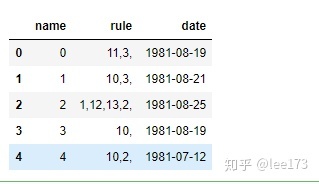
算法体系优化思路
目的找出问题规则进行调优。虚假交易用户由于不涉及到对用户的惩罚与反馈,无法通过电话反馈率来衡量算法效率,因此一直找不到好的方法来衡量算法的效率,规则多数都是基于业务线员工经验来定的。
单规则认定率¶
单规则认定率。一般认为一个真实的虚假交易用户通常在多方面有会具备可疑特征,因此越是被多的规则认定,那么这个用户应该越可能是真实的虚假交易用户,反过来,如果一个规则产出的用户多是由它一条规则认定,那么这个规则很可能就不够好。也就是说如果此规则的单独认定率越高则越有问题。
def c1(x): # 删除列表最后的空值
x.pop()
return x
z2 = r1.rule.str.split(',').apply(c1)
r1.rule = z2
r1.head()t1 = Counter(r1.rule.apply(len).values)
keys =[]
for i in t1.keys():
keys.append('rule'+str(i))
p0 = [i for i in zip(keys,list(t1.values()))]
def pie_base(data): #绘制饼状图
c = (
pe.charts.Pie()
.add("", data)
.set_global_opts(title_opts=opts.TitleOpts())
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
return c.render_notebook()
pie_base(p0)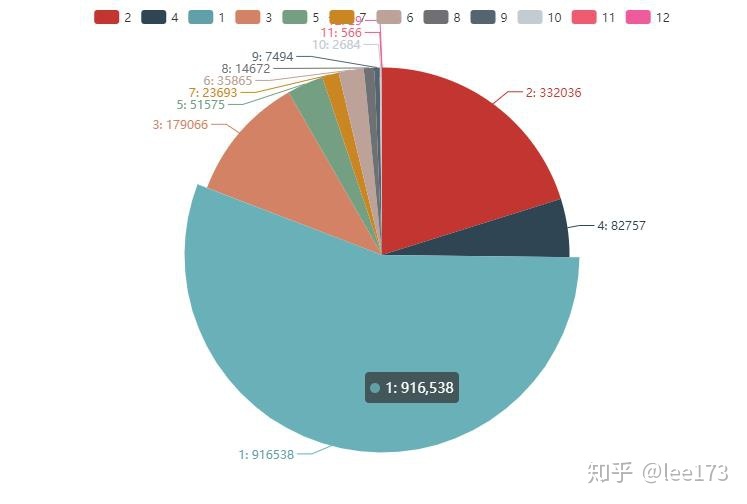
超过50%用户都是单规则认定。
统计各条规则认定数量
ru = {} # 所有规则认定数量
rud = {} # 单规则认定数量
for i in r1.rule.values:
for j in i:
ru[j] = ru.get(j,0)+1
if len(i)==1:
rud[j]=rud.get(j,0)+1
rule1=[]
num1=[]
num2=[]
d1 ={}
for i in range(1,14):
i = str(i)
rule1.append('规则'+i)
num1.append((ru[i]-rud[i])) # 多条规则认定的用户数量
num2.append(rud[i]) # 单条规则认定的用户数量
d1.update({i:round(rud[i]/ru[i],2)}) # 单规则认定率
def bar_different_series(): # 画图
c = (
pe.charts.Bar()
.add_xaxis(rule1)
.add_yaxis("多规则认定量", num1, gap="5%")
.add_yaxis("单规则认定量", num2, gap="5%")
.set_global_opts(
title_opts=opts.TitleOpts(),
)
)
return c.render_notebook()
bar_different_series()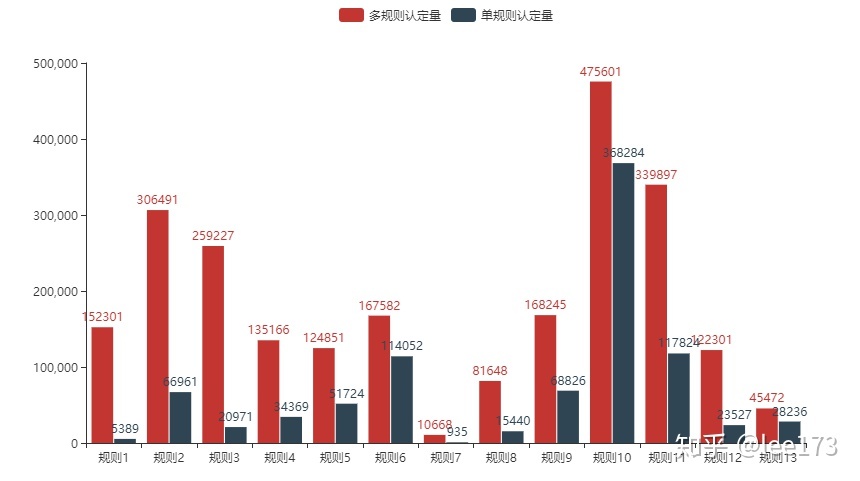
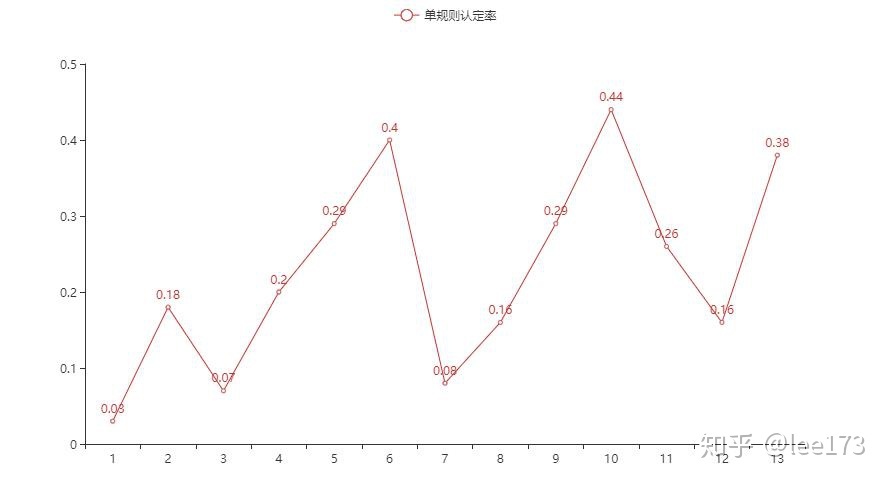
10号规则认定数量最高,单规则认定率也最高,6号规则单规则认定率次高。
1号规则 和 3号规则 认定数量不低,单规则认定率低。
7号规则 和13号规则规则产出数最低。
规则产出的时序分析
dd={}
for i,j in r1.groupby('date'):
z={}
z1={}
for k in j.rule.values:
for m in k:
z[m]=z.get(m,0)+1
if len(k)==1:
z1[m]=z1.get(m,0)+1
dd.update({i:[z,z1]})
dd1 ={}
rname = d1.keys()
for i in rname:
dd1.update({i:[[],[]]})
c=0
for i ,j in dd.items():
for i1 in rname:
try:
dd1[i1][0].append(j[0][i1])
except:
dd1[i1][0].append(0)
try:
dd1[i1][1].append(j[1][i1])
except:
dd1[i1][1].append(0)
line = pe.charts.Line()
line.add_xaxis(date1)
for i in rname:
line.add_yaxis(i, dd1[i][0], is_connect_nones=True)
for i in rname:
line.add_yaxis(i+'dan', dd1[i][1], is_connect_nones=True)
line.set_global_opts(title_opts=opts.TitleOpts(),)
line.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
line.render_notebook()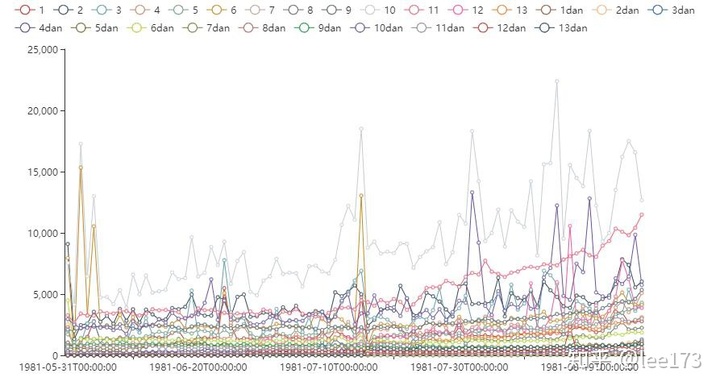
对比优质规则1,2与最差规则10,规则10单规则认定数波动大
6号规则平时效果不好,但是某些时候好
某些规则随时间突然增长可能是规则调节的结果,作弊人数增多也是不能排除的因素
关联规则分析
from pymining import itemmining, assocrules, perftesting,seqmining
def c1(x): # 对 rule 列进行处理
x.pop()
return x
z2 = r1.rule.str.split(',').apply(c1)
len(z2.values)
#1646975
relim_input = itemmining.get_relim_input(z2.values)
report = itemmining.relim(relim_input, min_support=2) # 统计出频繁项集
rules = assocrules.mine_assoc_rules(report, min_support=3000, min_confidence=0.5) # 频繁项集对应的规则
针对单规则集合进行分析:
ru = rules[-13:]
#由于单规则关联都在最后因此可以直接切片
#输出:
[(frozenset({'7'}), frozenset({'2'}), 8067, 0.6952512281306559),
(frozenset({'7'}), frozenset({'10'}), 9715, 0.8372834611738343),
(frozenset({'8'}), frozenset({'11'}), 63460, 0.6536338167435728),
(frozenset({'12'}), frozenset({'2'}), 73038, 0.5008503168115862),
(frozenset({'12'}), frozenset({'10'}), 82421, 0.5651932413528267),
(frozenset({'1'}), frozenset({'6'}), 81605, 0.5175026951613926),
(frozenset({'1'}), frozenset({'2'}), 117318, 0.7439786923711079),
(frozenset({'1'}), frozenset({'11'}), 94456, 0.5989980341175725),
(frozenset({'1'}), frozenset({'10'}), 83064, 0.5267550256833027),
(frozenset({'4'}), frozenset({'10'}), 103074, 0.6079806529625151),
(frozenset({'9'}), frozenset({'11'}), 143924, 0.607092390043489),
(frozenset({'3'}), frozenset({'10'}), 213916, 0.7634458490067738),
(frozenset({'2'}), frozenset({'10'}), 203395, 0.5446349196148367)]作网络图:
nodes = []
n=0
for i in ru.items():
nodes.append({"name":i[0],"symbolSize":ru[i[0]]/20000,"category":n})
n=n+1
links = []
for i in rules[-13:]:
links.append({'source':list(i[1])[0],'target':list(i[0])[0]})
def graph():
c = (
pe.charts.Graph()
.add("",
nodes,
links,
repulsion=1000,
)
.set_global_opts(
legend_opts=opts.LegendOpts(is_show=False),
title_opts=opts.TitleOpts(title=""),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
)
return c.render_notebook()
graph()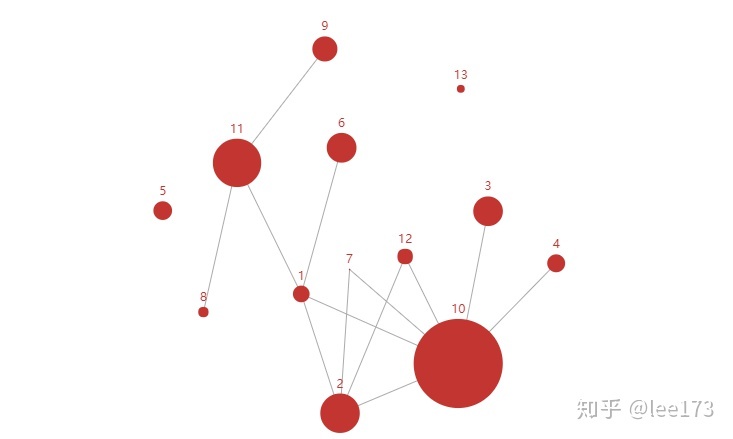
10,11,6号规则认定量大,只能印证其他规则,本身得不到任何规则的印证
13号规则孤立,并且不和任何规则发生关系
9号规则能被11号印证
5号孤立
1号优质规则被多条规则印证
2号规则本身质量可以,又能印证其他规则














 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









