






本文粗略的介绍下JavaIO的整体框架,重在解释BufferReader/BufferWriter的演变过程和原理(对应的设计模式)
一.JavaIO的简介
流按操作数据分为两种:字节流与字符流.
流按流向分为:输入流(读),输出流(写)。
字符流由来就是:早期的字节流+编码表,为了更便于操作文字数据。
记住:只要是操作字符数据,应该优先使用字符流。
字节流的抽象基类:InputStream ,OutputStream。
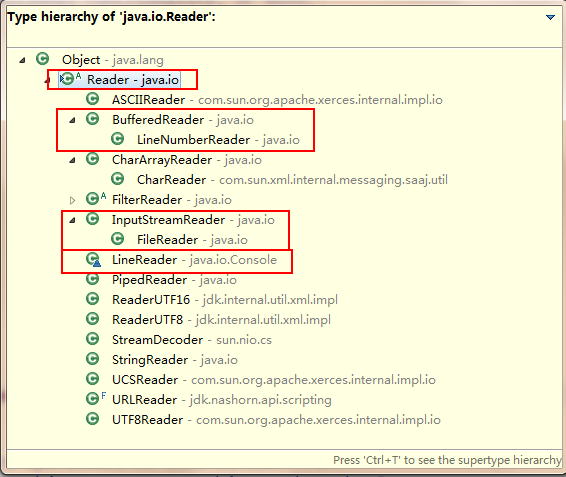
字符流的抽象基类:Reader ,Writer。
二.JavaIO中的流对象的继承和字节流,字符流的对应关系.
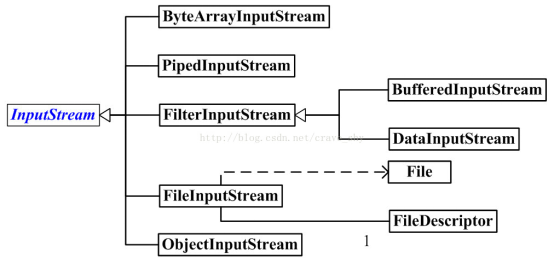
InputStream字节输入流:
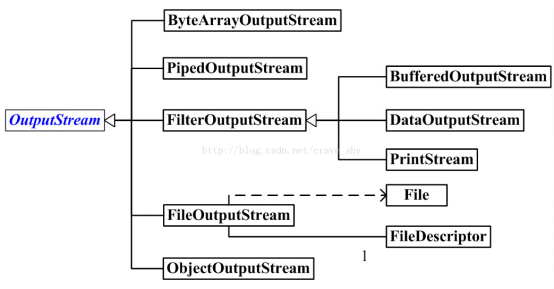
OutputStream:字节输出流:
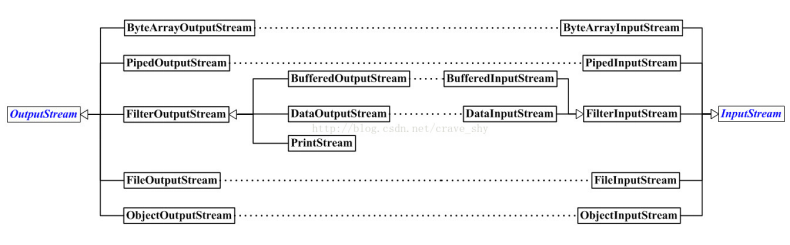
InputStream与OutputStream之间的对应关系:
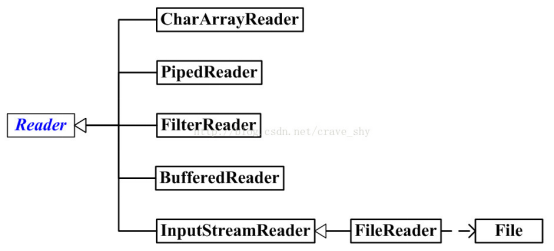
Reader :字符输入流
Writer :字符输出流
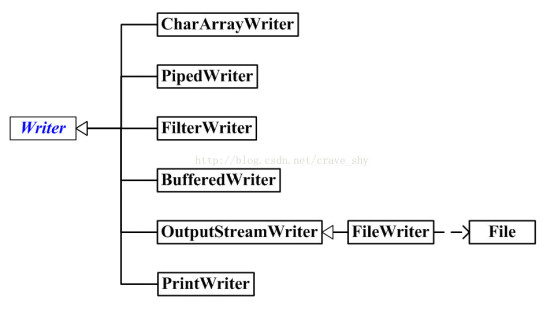
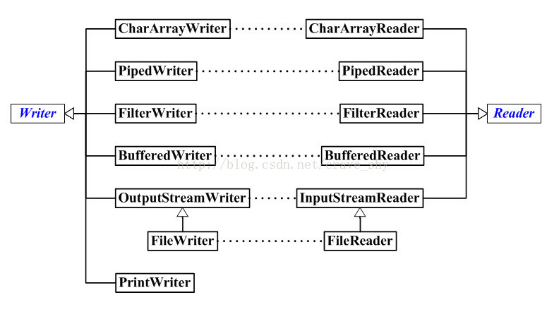
Reader与Writer之间的对应关系
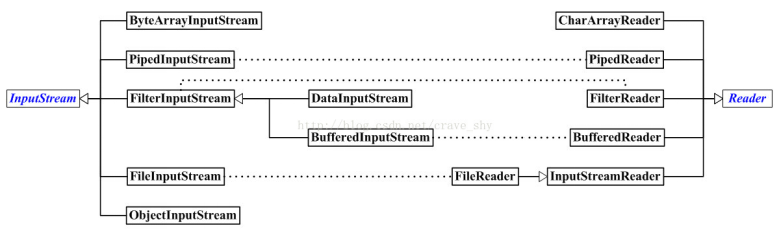
输入字节流、输入字符流之间对应关系
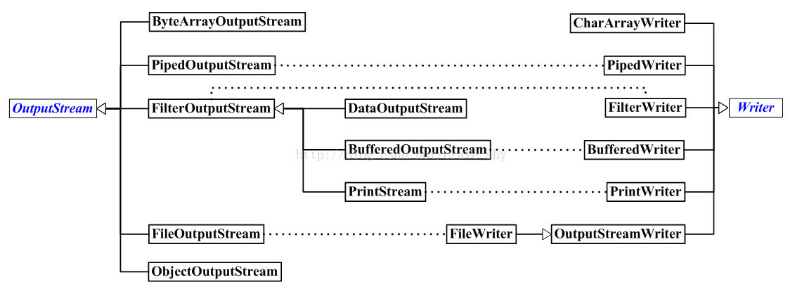
输出字节流、输出字符流之间对应关系
转换流 :InputStreamReader,OutputStreamWriter
转换流的由来:字符流与字节流之间的桥梁 ,方便了字符流与字节流之间的操作
转换流的应用:字节流中的数据都是字符时,转成字符流操作更高效。
标准输入输出流 :
System类中的字段:in,out。它们各代表了系统标准的输入和输出设备,默认输入设备是键盘,输出设备是显示器。
System.in的类型是InputStream.
System.out的类型是PrintStream是OutputStream的子类FilterOutputStream的子类.
举例引入:从原始IO----->用字符数组作为缓冲区---->用IO中的BufferReader/BufferWriter----->JavaIO中的设计模式(装饰设计模式)
①使用最原始的方式拷贝方式代码:
1 /*
2 * 需求:作业:将c盘的一个文本文件复制到d盘。3 *4 * 思路:5 * 1,需要读取源,6 * 2,将读到的源数据写入到目的地。7 * 3,既然是操作文本数据,使用字符流。8 *9 */
10 public classCopyTextTest {11 public static void main(String[] args) throwsIOException {12 //1,读取一个已有的文本文件,使用字符读取流和文件相关联。
13 FileReader fr = new FileReader("IO流_2.txt");14 //2,创建一个目的,用于存储读到数据。
15 FileWriter fw = new FileWriter("copytext_1.txt");16 //3,频繁的读写操作。
17 int ch = 0;18 while((ch=fr.read())!=-1){19 fw.write(ch);20 }21 //4,关闭流资源。
22 fw.close();23 fr.close();24 }25 }
②引入字符数组作为缓冲区:(循环次数小,效率高)
1 public classCopyTextTest_2 {2 private static final int BUFFER_SIZE = 1024;3 public static voidmain(String[] args) {4 FileReader fr = null;5 FileWriter fw = null;6 try{7 fr = new FileReader("IO流_2.txt");8 fw = new FileWriter("copytest_2.txt");9 //创建一个临时容器,用于缓存读取到的字符。
10 char[] buf = new char[BUFFER_SIZE];//这就是缓冲区。11 //定义一个变量记录读取到的字符数,(其实就是往数组里装的字符个数)
12 int len = 0;13 while((len=fr.read(buf))!=-1){14 fw.write(buf, 0, len);15 }16 } catch(Exception e) {17 //System.out.println("读写失败");
18 throw new RuntimeException("读写失败");19 }finally{20 if(fw!=null)21 try{22 fw.close();23 } catch(IOException e) {24
25 e.printStackTrace();26 }27 if(fr!=null)28 try{29 fr.close();30 } catch(IOException e) {31
32 e.printStackTrace();33 }34 }35 }36 }
原理图:
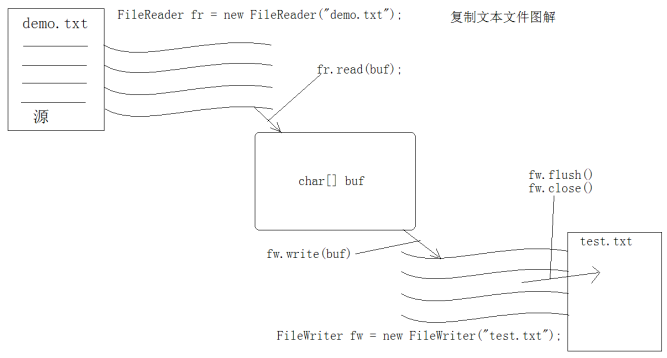
缓冲区的出现提高了文件的读写效率,有缓冲区可以提高效率,在Java中把缓冲区进行了封装,关闭缓冲区就是关闭的被缓冲的流对象!所以只需要关闭缓冲区就可以,不必要再关闭流了。
③引入BufferWriter(缓冲区的出现提高了对数据的读写效率,缓冲区要结合流才可以使用,在流的基础上对流的功能进行了增强)
1 public classCopyTextByBufTest {2 public static void main(String[] args) throwsIOException {3 FileReader fr = new FileReader("buf.txt");4 BufferedReader bufr = newBufferedReader(fr);5
6 FileWriter fw = new FileWriter("buf_copy.txt");7 BufferedWriter bufw = newBufferedWriter(fw);8
9 String line = null;10 while((line=bufr.readLine())!=null){11 bufw.write(line);12 bufw.newLine();13 bufw.flush();14 }15 /*
16 int ch = 0;17 while((ch=bufr.read())!=-1){18 bufw.write(ch);19 }20 */
21 bufw.close();22 bufr.close();23 }24 }
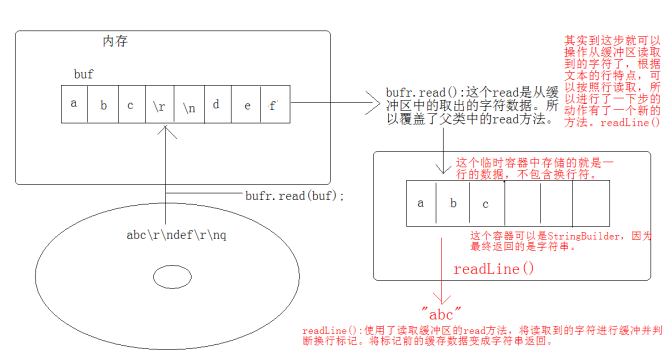
字符流缓冲区:
BufferedWriter:newLine();
BufferedReader: readLine();
Buffer***的原理图
④☆☆☆装饰设计模式
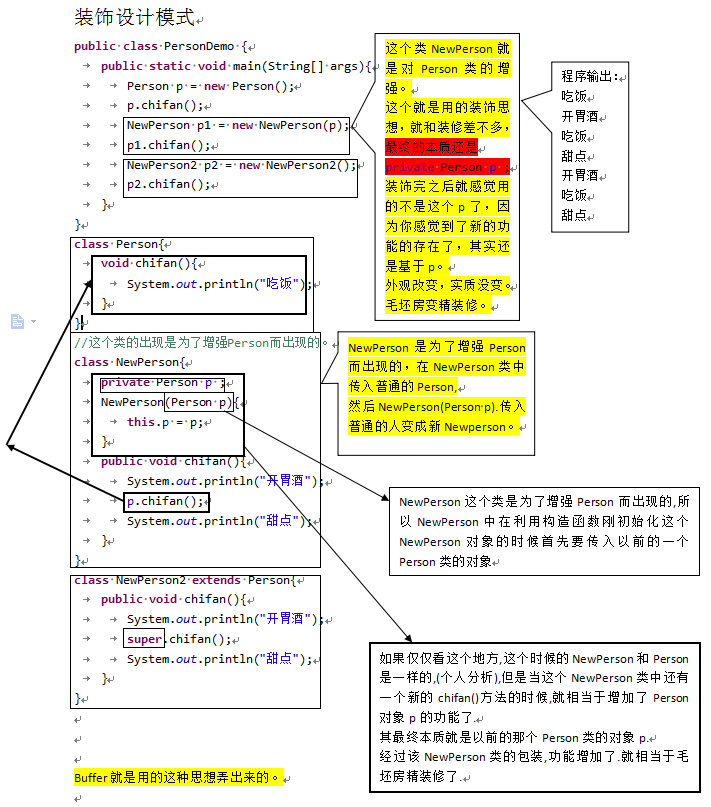
装饰设计模式的简易代码:
1 public classPersonDemo {2 public static voidmain(String[] args){3 Person p = newPerson();4 p.chifan();5 NewPerson p1 = newNewPerson(p);6 p1.chifan();7 NewPerson2 p2 = newNewPerson2();8 p2.chifan();9 }10 }11 classPerson{12 voidchifan(){13 System.out.println("吃饭");14 }15 }16 //这个类的出现是为了增强Person而出现的。
17 classNewPerson{18 privatePerson p ;19 NewPerson(Person p){20 this.p =p;21 }22 public voidchifan(){23 System.out.println("开胃酒");24 p.chifan();25 System.out.println("甜点");26 }27 }28 class NewPerson2 extendsPerson{29 public voidchifan(){30 System.out.println("开胃酒");31 super.chifan();32 System.out.println("甜点");33 }34 }
NewPerson是对Person采用了装饰设计模式对Person对象的功能,NewPerson2是继承了Person,对对象的功能进行增强。
装饰和继承都能实现一样的特点:进行功能的扩展增强,但是他们之前是有区别的,装饰更加灵活。
程序输出:
吃饭
开胃酒
吃饭
甜点
开胃酒
吃饭
甜点
对以上的代码的具体分析贴图:
装饰和继承都能实现一样的特点:对类对象的功能的扩展增强,区别有哪些?
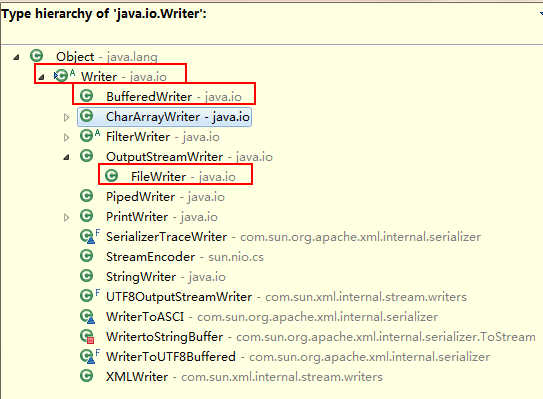
假设首先有一个继承体系如下:(TextWriter,MediaWriter并不存在)
Writer|--TextWriter:用于操作文本|--MediaWriter:用于操作媒体。
想要对操作的动作进行效率的提高。按照面向对象,可以通过继承对具体的进行功能的扩展,效率提高需要加入缓冲技术,上面的体系结构变成如下:
Writer|--TextWriter:用于操作文本|--BufferTextWriter:加入了缓冲技术的操作文本的对象。|--MediaWriter:用于操作媒体。|--BufferMediaWriter:
到这里就可以了,能达到对功能增强的目标,但是这样做好像并不理想。
如果这个体系进行功能扩展,又多了一些其他的流对象(****Writer,****Reader。。。。)
那么这个流要提高效率,是不是也要产生子类呢?
答案是:是。这时就会发现只为提高功能,进行的继承,导致继承体系越来越臃肿,不够灵活。
重新思考这个问题?
既然加入的都是同一种技术--缓冲。
前一种是让缓冲和具体的对象相结合。
可不可以将缓冲进行单独的封装,哪个对象需要缓冲就将哪个对象和缓冲关联。
通过上面的代码的分析,可以使用装饰设计模式的思想:
classBuffer{
Buffer(TextWriter w)
{
}
Buffer(MediaWirter w)
{
}
}
这样Buffer仅仅对传入的TextWriter和MediaWriter进行操作,下面传入一个Writer,就对Writer中的所有子类进行了操作。
//缓冲对象进行的也是写的操作,所以要继承Writer
class BufferWriter extendsWriter{
BufferWriter(Writer w)
{
}
}
这样Writer的体系结构变成如下:
Writer|--TextWriter:用于操作文本|--MediaWriter:用于操作媒体。|--BufferWriter:用于提高效率。
和上面最开始的通过继承增强功能的方式相比:
这两个体系相比,装饰比继承灵活,如果想对已有体系进行功能的扩展,首先要想到的就是装饰模式
装饰模式的特点:装饰类和被装饰类都必须所属同一个接口或者父类。
字节流和字符流的区别:
字节流能处理的数据单元不一样,数据的格式不一样,MP3,文本等。字符流只能操作文字。
字符流用的是缓冲区是字符数组。字节流用的缓冲区是字节数组。
字节流一次就不能读取出一个中文文字。字符流可以。
能用字符流进行媒体文件的操作吗?
字符流的特点在于,读取完字节之后并没有直接去往目的地里面去写而是去查表(查表有对应的数据,然后我们接着写不一样吗,是的,真的是这样的,但就是这个地方出了问题),万一读到的这个字节数据在表里查不到内容呢?文字有特定的编码格式,而这些媒体文件没有,他们都有其自身的编码方式,而且这些编码方式都是千变万化的,他拿到码表去查没有找到对应的,怎么办?码表会拿一些未知字符区的数据来表示这个没有对应的情况,就直接写到目的数据里面去了,这样元数据和目的数据就不一致了,这样就不能被图片编辑器所解析,解析不了。
不要尝试用字符流去操作媒体文件,你操作完之后有可能发现操作之后的数据大小和源数据的数据大小不一致。















 2651
2651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









