







1 solr概述
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。它通过使用类似REST的HTTP API,这就确保你能从几乎任何编程语言来使用solr。
2 solr安装
- 下载安装jdk,需要1.8及以上版本,并设置JAVA_HOME
- 下载solr安装包:https://lucene.apache.org/solr/到官网点击Download下载
- 下载完成后会得到一个压缩包,解压后会获得一个solr文件夹
- 进入bin目录下,执行solr start 此命令会启动solr应用服务器默认端口为8983,如果想指定端口号启动可以加参数–p例 如:solr start –p 8983
- 接下来在浏览器输入http://localhost:8983/solr可以进入Admin UI界面验证是否启动成功
- solr stop –p 端口号关闭solr服务,solr restart –p 端口号 重启solr服务
3 创建和配置core实例
在Solr中,每一个Core代表一个索引库,里面包含索引数据及其配置信息,solr中可以拥有多个Core,就像mysql中可以有多个数据库一样。
即需要通过solr查询出什么信息,就要事先定义好对应的索引,索引和数据库字段形成映射关系。
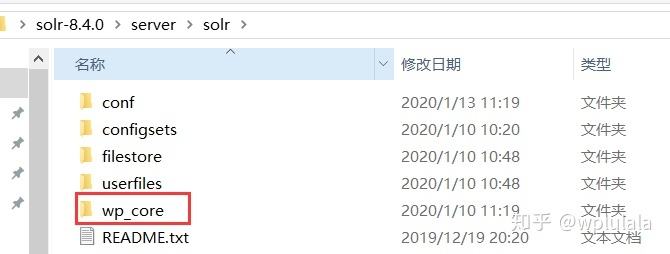
1) 创建core
在bin目录下执行solr create –c 名称,创建一个core,创建后的文件位于根目录下的server/solr目录下。(也可以在AdminUI页面,在core admin模块创建core)
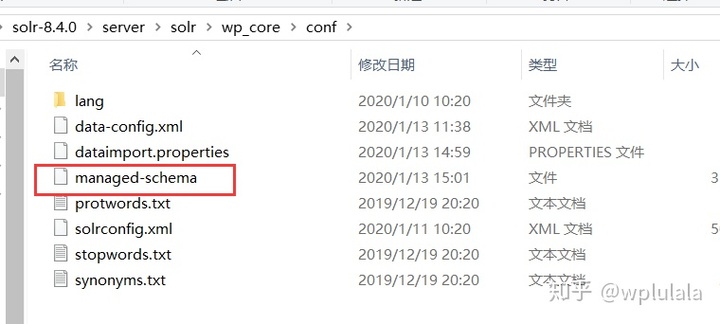
2) 配置schema
配置schema,schema是用来告诉solr如何建立索引的,他的配置围绕着一个schema配置文件,这个配置文件决定着solr如何建立索引,每个字段的数据类型,分词方式等,老版本的schema配置文件的名字叫做schema.xml他的配置方式就是手工编辑,但是现在新版本的schema配置文件的名字叫做managed-schema,他的配置方式不再是用手工编辑而是使用schemaAPI来配置,官方给出的解释是使用schemaAPI修改managed-schema内容后不需要重新加载core或者重启solr更适合在生产环境下维护。
3) Schema API
Schema API其实就是用post请求向solr服务器发送携带json参数的http请求,所有操作内容都封装在json中,如果是linux系统直接使用curl工具,如果是windows系统可以使用Postman。
curl -X POST -H 'Content-type:application/json' --data-binary '{
"add-field":{
"name":"sell_by",
"type":"pdate",
"stored":true }
}' http://localhost:8983/solr/gettingstarted/schema4)Admin UI界面操作schema API
索引类型,常见的string,pint,plong,pdate,boolean,一下是创建好索引的schema文件示例
<field name="materialName" type="text_ik" indexed="true" stored="true"/>
<field name="mediaType" type="pint" indexed="true" stored="true"/>
<field name="fileSize" type="plong" indexed="true" stored="true"/>
<field name="preimage" type="string" indexed="true" stored="true"/>
<field name="updateTime" type="pdate" indexed="true" stored="true"/>
<field name="isDelete" type="boolean" indexed="true" stored="true"/>
4 DIH导入索引数据
DIH全称是Data Import Handler 数据导入处理器,顾名思义这是向solr中导入数据的,我们的solr目的就是为了能让我们的应用程序更快的查询出用户想要的数据,而数据常存储在应用中的关系数据库中,那么solr首先就要能够获取这些数据并在这些数据中建立索引来达成快速搜索的目的。
- 复制dist目录下的solr-dataimporthandler-xxx.jar和solr-dataimporthandler-extras-xxx.jar到server/solr-webapp/webapp/WEB-INF/lib目录下,并复制mysql驱动jar包到server/solr-webapp/webapp/WEB-INF/lib目录下。
- 拷贝exampleexample-DIHsolrdbconf目录下的db-data-config.xml到core的conf目录下,然后文件名可以自定义,例如MyDataConfig.xml。然后配置文件内容,主要是数据库表字段名和solr索引名的映射。
注意这里容易与schema中的配置混淆,我的理解是schema中配置的是创建索引的配置,而索引的创建需要有数据基础,而现在讲的数据导入文件就是建立索引的数据基础,他是创建索引的元数据。现在配置文件完成后可以用DIH命令执行了。
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver" type="JdbcDataSource"
url="jdbc:mysql://119.23.39.192:3816/baby20191120" user="root" password="hwzl1qaz@WSX"/>
<document>
<entity name="annoucement_info" query="select * from annoucement_info"
deltaQuery="select ID from annoucement_info where UPDATE_TIME > '${dataimporter.last_index_time}'"
deltaImportQuery="select * from annoucement_info where ID = '${dih.delta.ID}'">
<field column="ID" name="id" />
<field column="TITLE" name="title" />
<field column="STATE" name="state" />
<field column="UPDATE_TIME" name="updateTime" />
</entity>
</document>
</dataConfig>
- 在core的conf目录下找到solrconfig.xml文件,需要在此文件中配置数据导入文件的映射位置。
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">MyDataConfig.xml</str>
</lst>
</requestHandler>
</config>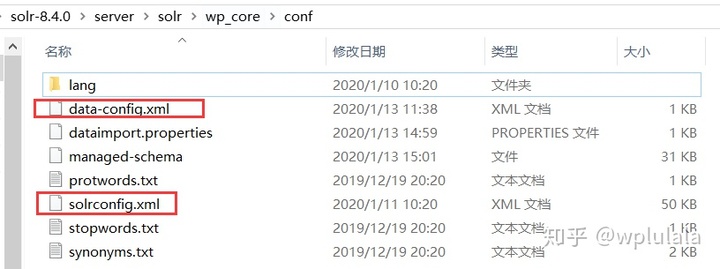
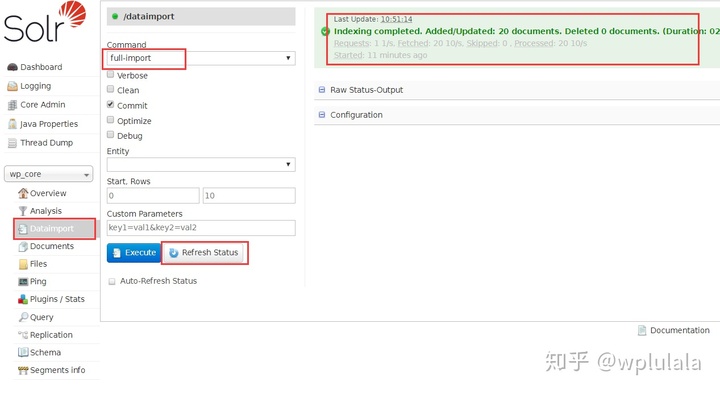
- 导入数据,分为全量导入和增量导入,增量导入由配置文件中的deltaQuery决定。
- 查询数据,可以写符合solr语法的查询语句
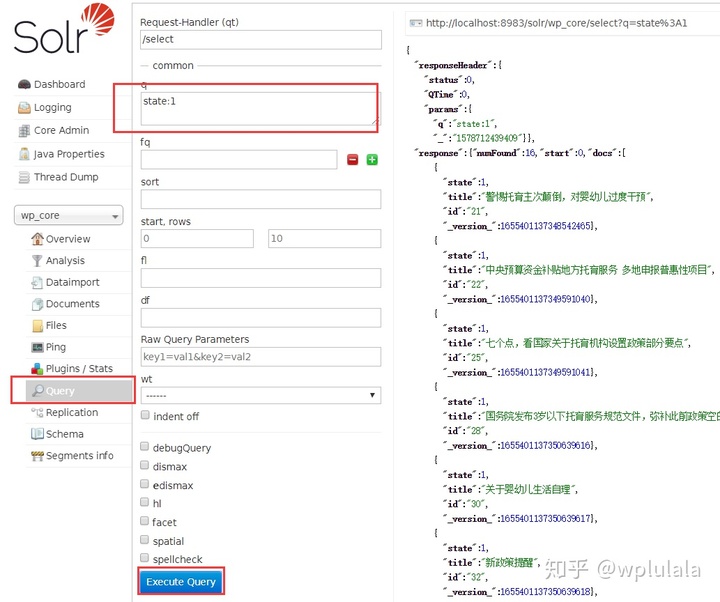
5 配置定时增量更新
通常业务系统中的数据库数据会不断增加和更新,且数据量会比较庞大,这里进行定时增量更新的策略。
- 下载apache-solr-dataimportscheduler.jar放到solr_homeserversolr-webappwebappWEB-INFlib目录下。
- 修改solr中olr_homeserversolr-webappwebappWEB-INFweb.xml, 在servlet节点前面增加
<listener>
<listener-class>
org.apache.solr.handler.dataimport.scheduler.ApplicationListener
</listener-class>
</listener> - 在solr_homeserversolr下新建conf文件夹,放入下载的dataimport.properties,根据自己的实际需求做相应修改
#core示例名称,多个用英文逗号分隔
syncCores=wp_core
#定时时间间隔,默认分钟
interval=2- 重启solr服务器。运行几分钟后,打开logs文件夹查看日志;如果出现下图中信息说明定时任务配置成功
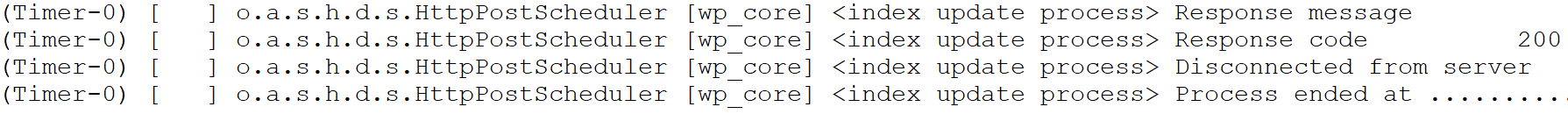
6 配置中文分词器
- 这里使用IKAnalyzer,这是第三方的一个分词器可以很好的扩展中文词库。
- 增加ik分词器jar包到solr_homeserversolr-webappwebappWEB-INFlib中。

- 进入solr_homeserversolr-webappwebappWEB-INFclasses;如果没有classes文件夹则创建一个,然后加入ik分词器配置文件。
- 打开core实例的managed-schema文件,增加分词器配置信息,并配置对应索引字段的分词属性。
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
- 重启solr服务,测试分词。
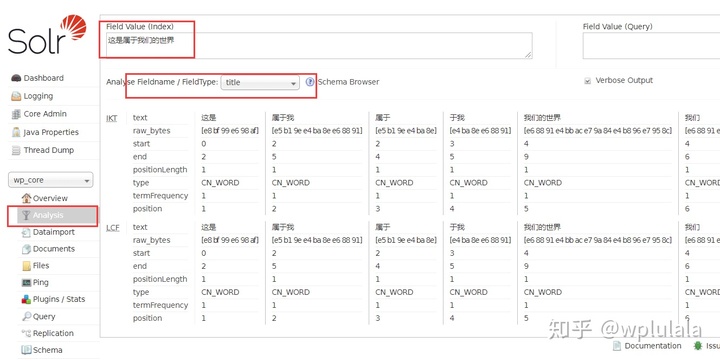
7 windows配置solr服务
- 借助NSSM这个工具,工具的地址是http://www.nssm.cc/download
- 下载下来解压文件夹,把NSSM.exe复制到solr的bin目录下。然在cmd中至该文件路径下执行nssm install solr,然后在弹出的窗口中进行如下配置
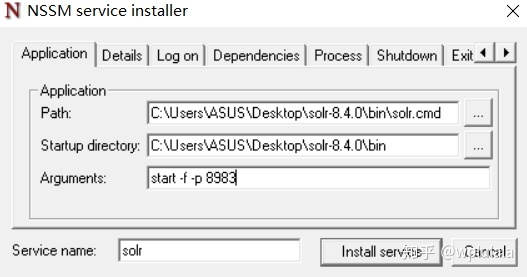
- 在windows服务中可搜索solr服务,设为自动启动。删除服务可使用命令sc delete <服务名>。
8 其他事项
- 报错日志查看
在serverlogs目录下,可查看solr.log文件。如果启动和运行过程中,出现异常会直接报java类的异常。
- 更新时间时区异常
修改bin/solr.cmd文件,找到set SOLR_TIMEZONE=UTC改为SOLR_TIMEZONE=UTC+8,这个一般会修复last_index_time,但是索引数据中时间类的数据会减少8小时需要注意。
- 数据库字段的大小写一定要注意,可能会出现不能自动识别的情况















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









