






如果你身在一线开发,你应该能感觉到NoSQL在实际应用当中占据的位置越来越重要,这其中一个非常重要的原因在于,互联网用户的剧增,传统关系型数据库已经不能应付动辄百万、千万甚至亿级用户量的系统了,越来越多的系统开始使用NoSQL。其中,我相信你一定听说过Redis,Redis之所以如此高效,除了因为它使用了内存作为存储介质,还因为他使用了很多非常高效的数据结构,比如SDS、压缩表、跳表、Hash表等,其中Hash表就是我们今天要讲的内容。很多人一提到Redis第一个想到的就是跳表,但是我觉得,Redis的灵魂应该是Hash表,能够在纳秒级从上亿个key里面找到对应数据,这本身已经很厉害了,更别说Hash表还是Redis的Hash数据结构的底层实现。Hash表的重要性,不言而喻。
什么是散列表
我们平时听到的"Hash表"或者"Hash Table"说的就是散列表,下面我们统一都叫做散列表。我们在前面 数组真的很简单吗?那篇文章里有提到,数组的随机访问时间复杂度是O(1),可能大家也都知道,散列表的随机访问时间复杂度也是O(1)。这是因为散列表这种数据结构的底层结构使用的还是数组,讲到这里可能有点晕,既然底层用的还是数组,那散列表存在的意义是什么呢?下面我举个例子你就明白了。
很多人大学可能都做过万年不变的学生管理系统,假设一个班级里学生的姓名都是唯一的,我们要实现一个根据学生姓名查询学生的成绩信息,应该怎么做呢?我们看使用数组怎么实现,由于数组的下标是从小到大的数字,我们可以使用一个二维数组来保存学生成绩信息,如下:
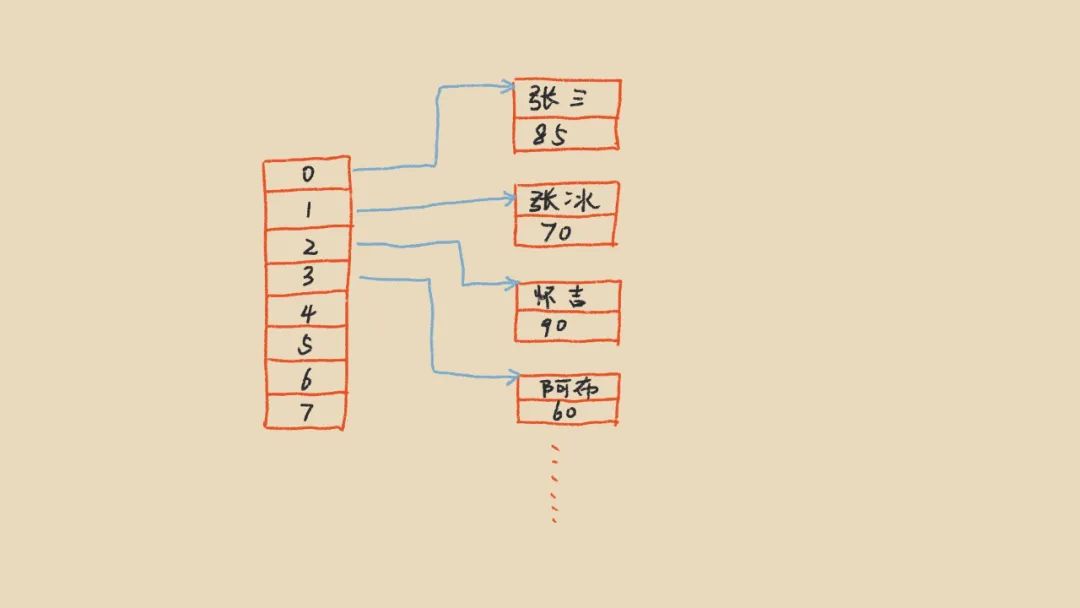
当我们通过学生姓名查询成绩的时候,我们遍历一遍数组,拿姓名和第二维数组里的姓名去比对,如果一样就说明找到了,直接返回。这样通过姓名查询一个学生成绩的时间复杂度就是O(N)。当然,对于一个班级来讲,以目前计算机的性能也能很快的查询到对应的信息。但是,对于一些数据量巨大的场景,比如redis,动辄上百万,甚至上亿的Key,显然遍历一遍有1亿个元素的数组在实际业务场景中是不能被接受的。
我们来看一下如何用散列表解决上面的问题,我们可以将学生姓名转化成数字,这样我们就得到一个合法的数组下标了,通过下标我们就能高效的随机访问数据了。将姓名转成数字的这个过程叫做求数据的散列值,使用的是hash算法,这也是为什么有时我们叫hash表,hash算法可以保证同样的数据算出来的hash值是一样的,hash算法是整个散列表的关键。如图:
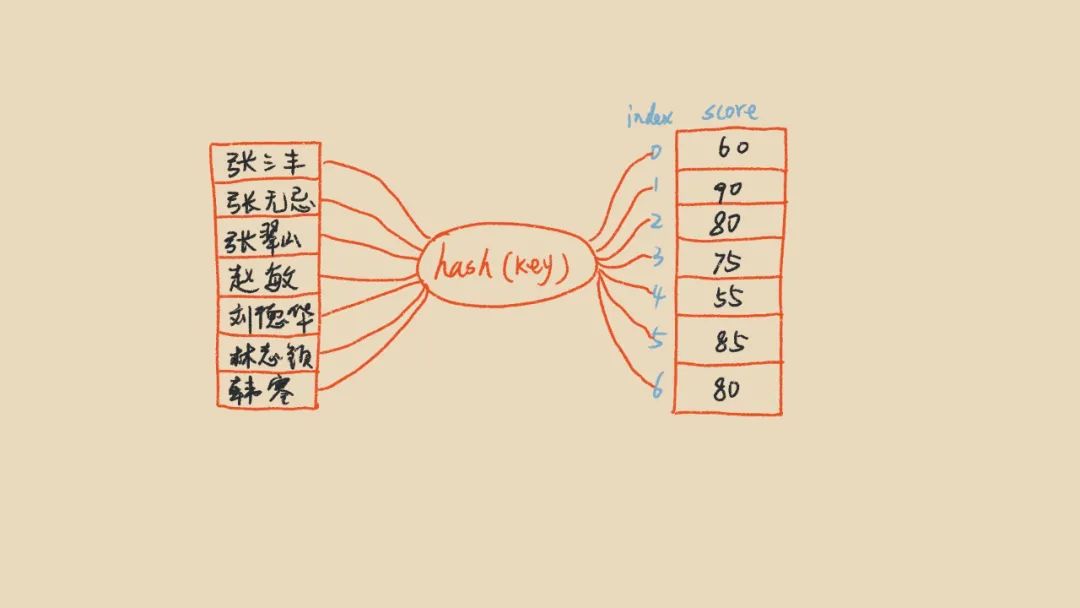
以上将数据转成Hash值映射成数据的下标,通过下标去操作数组元素的这个过程我们就叫做散列表。
这里说一个结论,不同的数据的hash值是有可能一样的,这就是hash冲突。
如何解决散列冲突
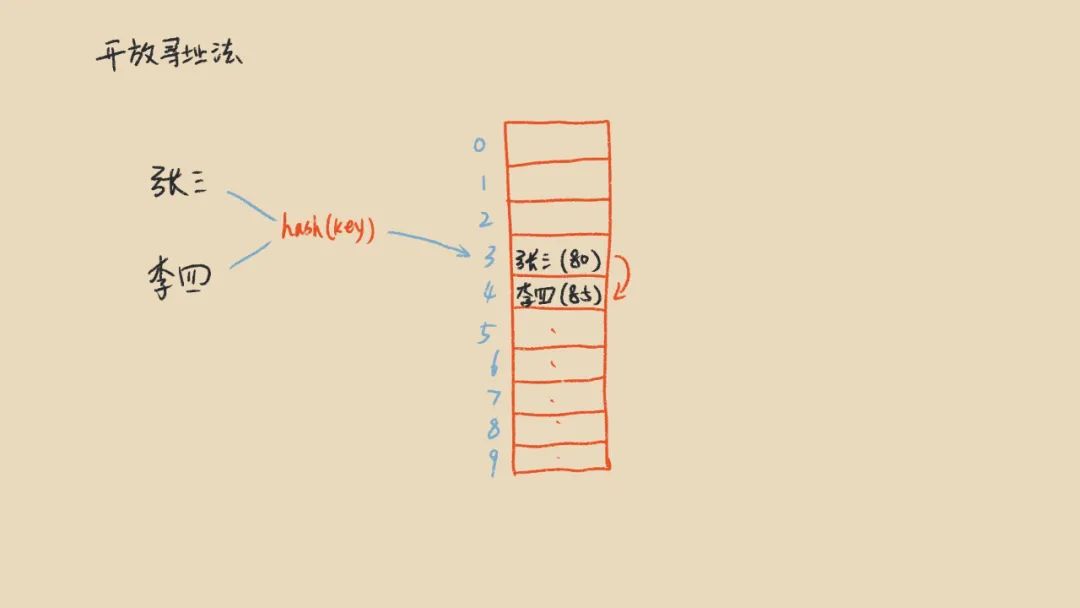
出现散列冲突一般有两种解决方案,一种是在原数组上进行操作,叫做开放寻址法。另一种是Hash值相同的数据使用一个链表来存储,叫链表法。
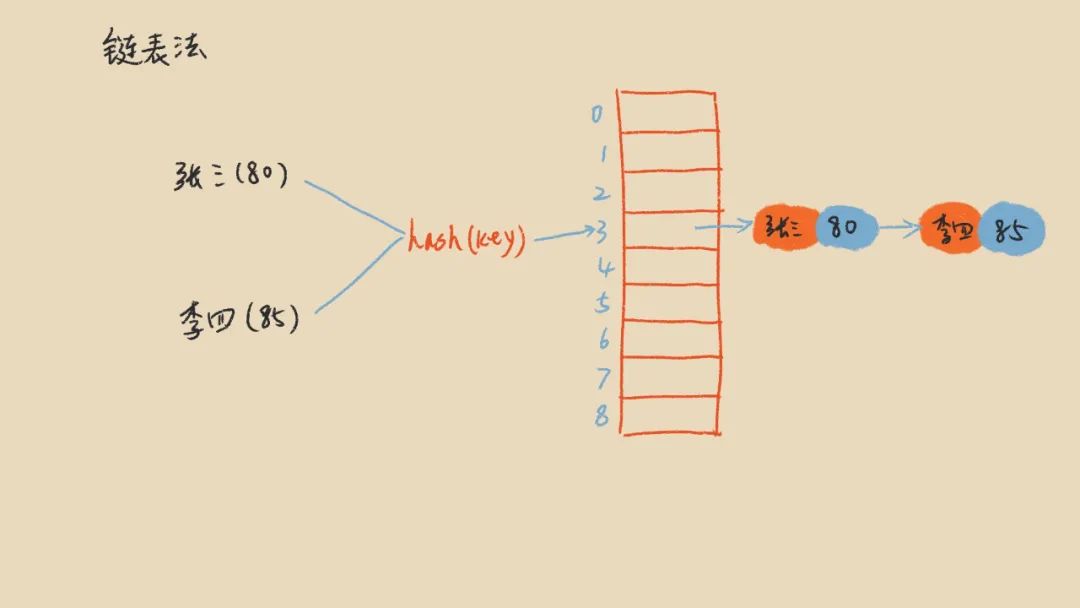
我们先来看开放寻址法,开放寻址法就是出现冲突之后,从当前hash值对应的主键往后找一个空位置保存数据,查找数据的时候也是先算出hash值,从当前hash值的位置往后遍历,直到找到对应的数据为止。开放寻址法虽然实现起来简单,但是也有缺点,比如我们查询数据的时候,由于要考虑hash冲突,我们就得去遍历数组,在一些极端情况下,会跨多个hash值,效率就不高了。所以,散列表更为经典的实现方法是链表法。
链表法的实现相对复杂一点,就是当出现hash冲突的时候,使用链表保存数据,这样hash值下标的位置保存的就是一个链表,查询的时候我们只需要遍历对应的链表就可以了,在遍历的过程中我们将原数据和链表节点里的数据进行比较,如果相同就说明找到了,如下图:
实现一个散列表
下面我们就来实现一个散列表,为了尽量全的展示实现的过程,这里我们在Hash冲突的时候使用编程语言内置的map来实现一个最简化版的散列表,如果理解了这个简化版的散列表,再去使用开放寻址法和链表法实现散列表也是很简单的。我们使用go语言实现,对应的java版本我会把我的github链表放在下面,你可以点进去查看。
首先,我们声明一个hashData的结构体:
type hashData struct { // 散列表容量 size int // 散列表 hashTable map[int]map[string]interface{} // 动态扩缩容的容量capacity对应的索引 M int}初始化hashData对象
func Hash() *hashData { hash := &hashData{ size: 0, // 初始化0个元素 M: capacity[capacityIndex], // 初始化容量 hashTable: map[int]map[string]interface{}{}, // 散列表 } for i := 0; i < capacity[0]; i++ { hash.hashTable[i] = map[string]interface{}{} } return hash}添加一个元素,这里我们将添加和修改元素分成了两个方法,当然你也可以将这两个方法合并成一个方法,具体处理比较简单,这里就不再赘述了。添加一个元素分几步。第一,找到hash值对应的map,第二,以当前值为key设置对应的值,如果使用的是链表法,这里就要对链表进行遍历了,第三,将散列表的长度加1,最后,对hash表进行扩缩容,下面有几个陌生的变量先不管,我们后面详细说。
func (h *hashData) Add(key string, value interface{}) { m := h.hashTable[h.hashCode(key)] m[key] = value h.size++ if h.size >= upperTol * h.M && capacityIndex+1 < len(capacity) { capacityIndex++ h.resize(capacity[capacityIndex]) }}设置/修改元素
func (h *hashData) Set(key string, value interface{}) { tmpM := h.hashTable[h.hashCode(key)] if _, ok := tmpM[key]; !ok { panic("The item " + key + " is not found.") } tmpM[key] = value}获取元素
func (h *hashData) Get(key string) interface{} { tmpM := h.hashTable[h.hashCode(key)] if _, ok := tmpM[key]; !ok { return nil } return tmpM[key]}删除元素
func (h *hashData) Remove(key string) interface{} { tmpM := h.hashTable[h.hashCode(key)] if _, ok := tmpM[key]; !ok { return nil } h.size-- if h.size < lowerTol * h.M && capacityIndex - 1 >= 0 { capacityIndex-- h.resize(capacity[capacityIndex]) } return tmpM[key]}我们重点看一下hashCode()这个函数
func (h *hashData) hashCode(data string) int { v := int(crc32.ChecksumIEEE([]byte(data))) if v < 0 { v = -v } return (v & 0x7fffffff) % h.M}在hashCode中,我们先对key计算hash值,然后对hash值进行取模,这里表示,我们的hash表最多只有h.M这么大的容量,要注意这里的容量指的是散列表底层的数据的容量。这个值我们使用了一组素数来进行设置,我们前面在讲数组的时候,有讲到动态数组我们要考虑扩容的问题。同样,对于hash表我们也需要考虑动态扩容的问题,前面我们在讲数组的时候有讲到我们可以在数组满了的时候再创建一个两倍大小的数组,但是当数组容量达到几千几万的时候如果再创建一个两倍大小的数组,很可能后面的空间我们永远都用不到,造成了浪费,那怎么办呢?我们前面有提到过根据一定的比例来进行扩容,当然我们也可以事先进行定义,比如使用一组从小到大的素数,如下:
capacity []int = []int{53, 97, 193, 389, 769, 1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433, 1572869, 3145739, 6291469,12582917, 25165843, 50331653, 100663319, 201326611, 402653189, 805306457, 1610612741}capacityIndex = 0我们在初始化一个hashData对象的时候,将h.M初始化成了capacity[capacityIndex],这时h.M==53,当53容量不够的时候,我们再扩到97,依此类推,下面是关于扩缩容的代码:
func (h *hashData) resize(capacityNum int) { newHashTable := map[int]map[string]interface{}{} for i := 0; i < capacityNum; i++ { newHashTable[i] = map[string]interface{}{} } oldM := h.M h.M = capacityNum for i := 0; i < oldM; i++ { tmpM := h.hashTable[i] for k, v := range tmpM { newHashTable[h.hashCode(k)][k] = v } } h.hashTable = newHashTable}使用素数进行扩缩容的最佳实践可以参考下面的地址:
https://planetmath.org/goodhashtableprimes
你也可以把使用素数扩缩容的方法用到前面的动态数组的实现上。好了,以上就是我们实现的一个简化版的散列表,对应的代码可以去我的github上查看,里面包含了java和go两个版本,后期也会陆续加入其它语言的实现。
https://github.com/seepre/data-structure/blob/master/DOCS/line-hash.md
实现一个基于内存的键值数据库
接下来我们实现一个带有网络功能的基于内存的键值数据库,整个项目我们分为了网络服务、命令解析器、和命令执行器三层,网络服务主要负责和客户端建立连接并进行通信,命令解析器负责命令的解析并转发到命令执行层,在命令执行层支持SET、GET、DEL命令,分别对应添加/修改、获取和删除数据。数据的存储部分我们使用上面实现的散列表来管理。
下面是项目的架构图。当客户端通过网络服务和我们的数据库建立连接之后就可以发送命令,然后由命令解析器解析命令,最终将数据存储到hashData,这里的HashData就是我们上面实现的散列表里的那个HashData。
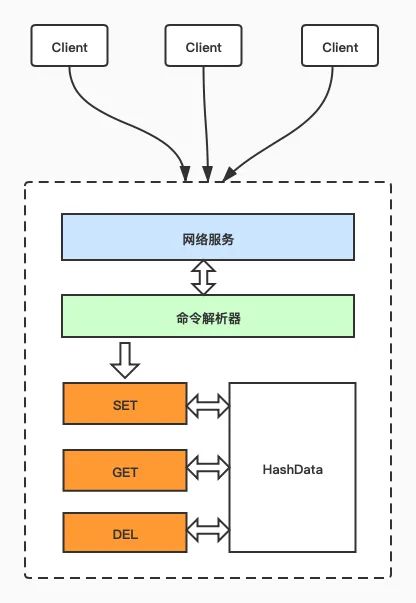
具体的代码可以去我的github上查看
https://github.com/seepre/M-DB
总结一下:
今天我们讲了散列表这种数据结构,在很大型项目中你都能看到它的身影。由于它随机访问O(1)的时间复杂度简直就是计算中的效率扛把子。但是,散列表虽然可以得到一个非常不错的性能,但是它没法解决数据的有序性,所以对于一些对顺序有要求的场景来说,并不适合。所以,这也是为什么会有我们后面会介绍到的各种树形数据结构。这也是为什么很多优秀的软件都不仅仅限于使用一种数据结构,大都是结合了多种数据结构的优点,来达到最好的性能。
下一节,我们来聊一下集合与映射















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









