






复制的发展与瓶颈基本原理
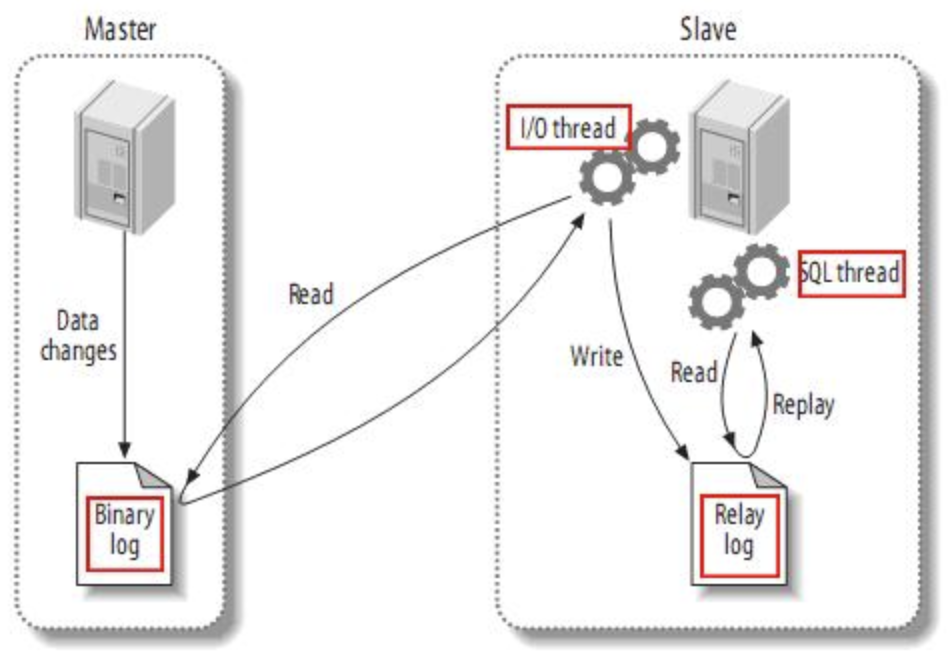 复制原理
复制原理
MySQL 复制的基本原理是比较简单和清晰的:Slave 节点中的 IO Thread 从 Master 的 binlog dump 新的内容到 Slave 本地的 relaylog,然后 SQL Thread 从 relaylog 中读取数据,在 Slave 上重放这些数据变更。
MySQL 5.5 与以前
在这个阶段,MySQL 复制的实现和原理基本是一致的,只有一个 SQL 线程在回放这些数据变更,这就导致了主库上并行执行的很多操作,在 Slave 上变成了串行,严重的限制了复制的效率,导致同步延迟的问题出现的比较多。
MySQL 5.6
为了解决这个问题,MySQL 5.6 提出了并行复制的技术,简单的原理图参考下图:
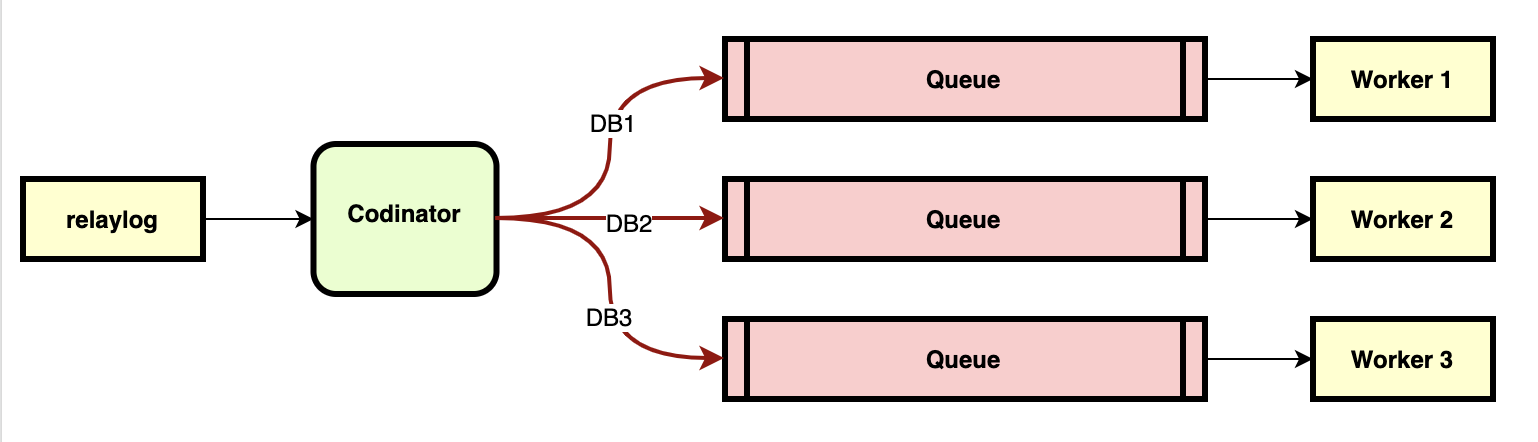 MySQL 5.6
MySQL 5.6
这个并行复制并不是通常意义上的并行复制,实际上是以 DB 为维度的并行复制,同一个 DB 内的操作实际上还是串行的,但是这个消费者生产者的原模型一直被并行复制所沿用。
MySQL 5.7.21 之前
在 5.6 的基础上,MySQL 5.7 去掉了表或者库的限制,基于 Group Commit 实现了完整的并行复制,同一个恶 Group 内的事务是互不冲突的,在 Slave 上可以并行回放。
具体的设计思路可以参考官方的文档:WL#6314,以及优化过后的方案(WL#7165),这里只是简单介绍一下 5.7 是如何判断事务冲突的。
5.7 原生的方案,参考如下图:
Trx1 ------------P----------C-------------------------------->
|
Trx2 ----------------P------+---C---------------------------->
| |
Trx3 -------------------P---+---+-----C---------------------->
| | |
Trx4 -----------------------+-P-+-----+----C----------------->
| | | |
Trx5 -----------------------+---+-P---+----+---C------------->
| | | | |
Trx6 -----------------------+---+---P-+----+---+---C---------->
| | | | | |
Trx7 -----------------------+---+-----+----+---+-P-+--C------->
| | | | | | |
^ ^ ^ ^ ^
c1 c2 c3 c4 c5
横向表示时间线,纵向表示不同的事务,P 和 C 可以粗略的理解为事务执行的不同阶段。简单的看,原生的方案中,以 C 的逻辑时间点为分界线,为每个 Trx 标记了一个逻辑的序号,P 阶段会获取这个逻辑序号,同样序号的事务可以在 Slave 并行回放。因此上图中会生成如下的 4 个事务组:
,,,
从实际的情况来看,Trx4 这个事务有很多部分是和 Trx5,Trx6 重合的,这几个事务之间其实可能并不存在锁冲突,因此官方又对这个所冲突检测的方式做了优化:
- 持有锁的生命周期有重叠,说明不存在锁争用,可以并行回放:
Trx1 -----L---------C------------>
Trx2 ----------L---------C------->
- 持有锁的生命周期没有重叠部分,无法判断是否有锁争用,不可以并行回放:
Trx1 -----L----C----------------->
Trx2 ---------------L----C------->
因为检测锁的消耗会比较大,因此官方根据事务各个阶段的特点,直接划定了事务的锁生命周期,绕开了锁争用的检测,“预测”了事务之间的锁争用。
以上图为例,L 与 C 代表锁生命周期的起点,如果两个事物在这个周期内存在重叠,那么就判断为可以并行回放,如果这两个周期没有重叠,就判断为无法并行回放。参考前面 Trx1 ~ Trx7 的示例,以这种策略来判断的话,事务组会合并成 3 个,并行复制的事务吞吐量会得到提升。
,,
但是这种策略会有一个问题:当主库的并发度不高(比如少量的长连接),或者是 IO 设备的性能足够好的时候,L 与 C 重叠的事务会比较少,每一个 Group 的事务数偏低,实际并行复制的效率依旧会有问题,严重的时候,比如单线程操作 DML(脚本批量操作数据)的时候,会发现所有的 DML 都不存在重叠的部分,5.7 的并行复制就会退化为单线程串行复制(传统艺能:一核有难,多核围观)。
WriteSet 复制,8.0 及 5.7.21 之后
WriteSet 实际上是事务冲突检测机制的称呼,通过对事务中受影响的行进行 Hash,然后和 History 中的 WriteSet result 进行对比,如果不存在冲突则合并到一个事务组,否则就把这个事务加到下一个事务组中。
由于采用了实际的数据内容检测,所以相比较于 5.7 的预测,WriteSet 能更准确的判断事务之间的冲突,既避免了 5.7 退化的问题,又避免了锁争用检测的消耗。
仍旧以图例来简要说明 WriteSet 的原理:
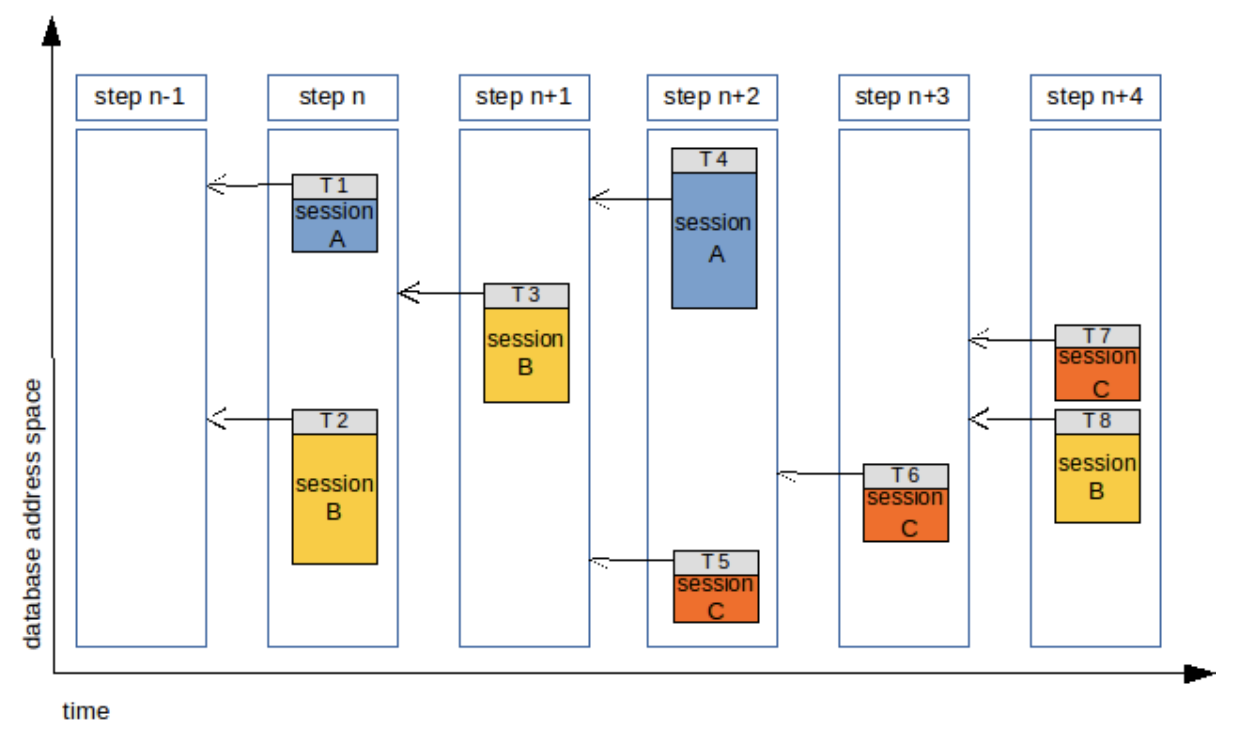 WriteSet 复制
WriteSet 复制
每一个方块代表这个事务内受影响行的范围,T1~T8 代表事务执行的顺序,从方块代表的范围来看,可以看到 T4 和 T3 存在重叠,意味着这两个事务的 Hash 计算结果中会发现冲突,因此会从 T4 开始,开启一个新的事务组。T8 和 T6 之间存在重叠部分,因此与 T4 的行为类似,最终会产生如下图所示的效果:
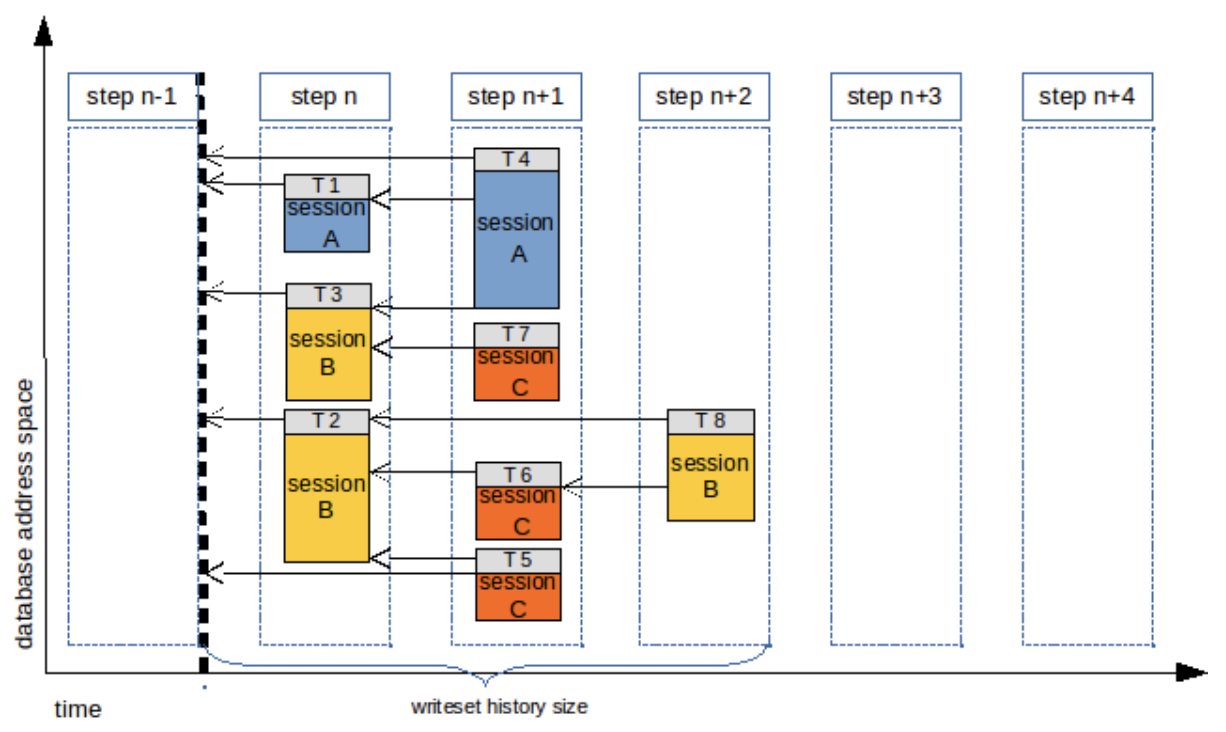 WriteSet 复制
WriteSet 复制
总共会有三个事务组:
,,
测试一下
针对 5.7 单线程 DML 退化的场景和常规场景,都和 WriteSet 做一下对比,看看实际的效果。测试使用的数据集由 sysbench 1.0.20 生成,具体信息如下:
测试数据:5 张表,每张表 100 万行数据,物理大小约 900MB。
MySQL 版本:Oracle 官方版本,5.7.31,6 GB 的 Buffer Pool。
事务提交策略:innodb_flush_log_at_trx_commit=2,sync_binlogsync_binlog=0
从库并行复制的并发度为 8
数据已经预热,全部加载到内存
测试项目:
主库 32 线程并发,回放 500 万条单行操作的 DML 语句,分别使用 WriteSet 和普通并行复制。
主库 1 线程并发,回放 500 万条当行操作的 DML 语句,分别使用 WriteSet 和普通并行复制。
测试结果参考下图:
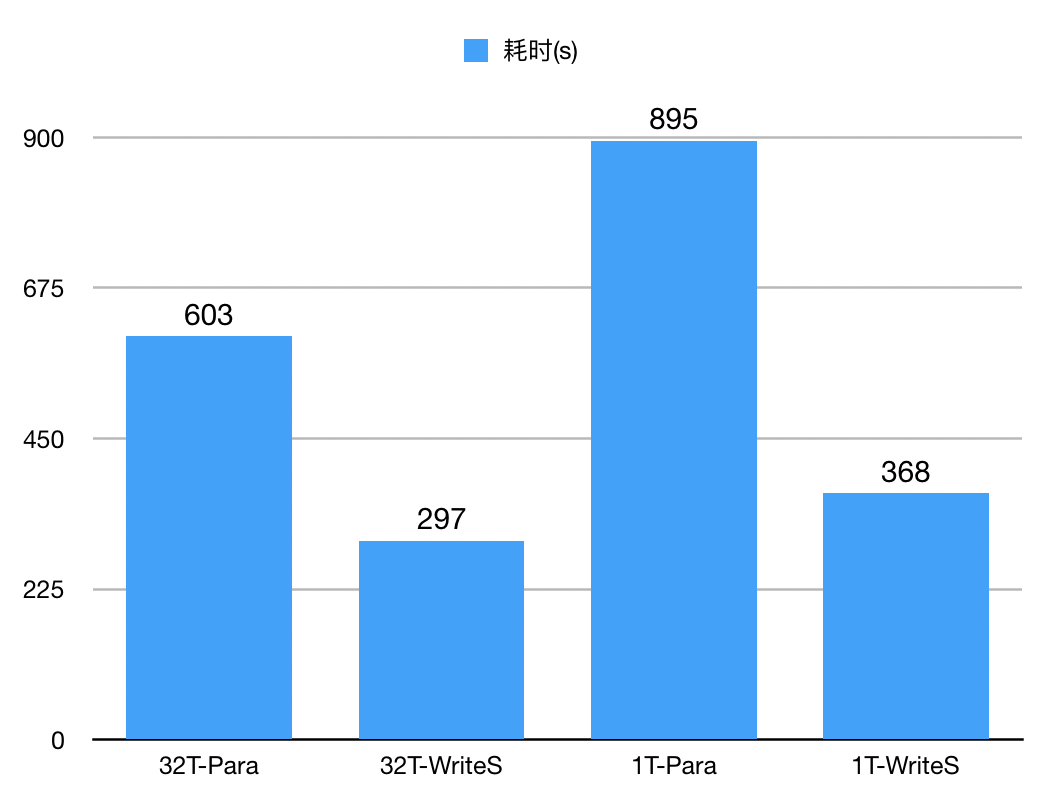 测试结果
测试结果
图例的纵坐标为追同步的耗时,越少越好,横坐标为各个测试用例:
1T-Para:主库 1 线程并发,使用 5.7 的并行复制
1T-WriteS:主库 1 线程并发,使用 WriteSet 复制
32T-Para:主库 32 线程并发,使用 5.7 的并行复制
32T-WriteS:主库 32 线程并发,使用 WriteSet 复制
可以看到 WriteSet 复制比 5.7 的并行复制快了至少 1 倍,在主库单线程的场景下,WriteSet 耗时仅并行复制的 40% 左右,同步复制的事务吞吐量提升了非常多。
总结一下
新技术的不断出现,让 MySQL 的“短板”逐渐被补齐,是时候更新数据库的版本,迎接更好的使用体验了~














 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









