






BAIDU_AIAdversialAttack
AI安全对抗赛第二名方案 --本项目基于飞桨PaddlePaddle实现
队伍:我不和你们玩了
赛题背景
目前人工智能和机器学习技术被广泛应用在人机交互、推荐系统、安全防护等各个领域,其受攻击的可能性以及是否具备强抗打击能力备受业界关注。具体场景包括语音,图像识别,信用评估,防止欺诈,过滤恶意邮件,抵抗恶意代码攻击,网络攻击等等。攻击者也试图通过各种手段绕过,或直接对AI模型进行攻击达到对抗目的。在人机交互这一环节,随着移动设备的普及,语音、图像作为新兴的人机输入手段,其便捷和实用性被大众所欢迎。因此图像识别的准确性对人工智能产业至关重要。这一环节也是最容易被攻击者利用,通过对数据源的细微修改,在用户感知不到的情况下,使机器做出了错误的操作。这种方法会导致AI系统被入侵、错误命令被执行,执行后的连锁反应会造成的严重后果。
本次竞赛的题目和数据由百度安全部、百度大数据研究院提供,竞赛平台AI Studio由百度AI技术生态部提供。期待参赛者们能够以此为契机,学习对抗样本理论知识并提升深度学习工程实践能力。欢迎全球范围开发者积极参与,鼓励高校教师积极参与指导。
赛题描述
- 初赛:初赛中,选手通过对 指定图像 添加扰动,使目标模型(Target Model)(一个为ResNeXt50模型并公开模型结构与参数(白盒);一个为MobileNetV2模型并公开模型结构与参数(白盒);一个不公开模型结构与参数(黑盒)。)分类错误,例如对于一张分类为A的图片,目标模型只要判别扰动后的样本不为A,即可判定成功。同时以生成扰动量越小越优。
- 复赛:复赛选手的目标与初赛相同: 利用给定,将指定的120张图片样本生成为攻击样本,主办方根据选手提供的攻击样本在后台使用上述5个Target Model(一个是与初赛相同的ResNeXt50白盒模型(白盒),一个是人工加固的模型(灰盒),另外三个均为黑盒模型,其中包括由AutoDL技术训练的模型。)进行评估,只要使Target Model分类结果与Label不一致,则判定为攻击成功。样本攻击成功数越多、扰动越小,得分越高。
方案
攻击所用算法主体为MomentumIteratorAttack,代码实现参照了advbox。在此基础之上,尝试了不同的目标函数,集成了不同的模型,添加了多样的越过局部最优的策略。
模型集成
集成模型选取思路为多元,尽可能多的不同模型,才可能逼近赛题背后的黑盒模型。
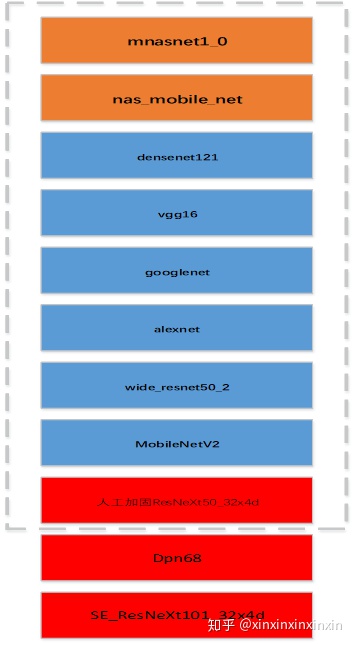
- 橙色和蓝色框中模型均采用pytorch进行迁移训练,训练集测试集为原始Stanford Dogs数据集划分,迭代次数均为25,学习率均为0.001。随后将pytorch转换为oxnn模型,再用x2paddle转换为paddle模型。
- 红色框中模型为直接用paddlepaddle训练而来,迭代次数为20,其余参数与前述相同。
- 人工加固ResNeXt50_32x4d模型
决赛中的灰盒模型为人工加固的模型,结构为ResNeXt50。为了攻击黑盒模型,我在本地训练了一个加固模型,作为灰盒模型的逼近。训练加固模型涉及到训练集的选取和训练方法的选取。 训练集的构成主要有两部分,第一部分我采用不同的方法攻击初赛的白盒模型(此白盒模型与灰盒模型具有相同的网络结构),将生成的n个样本集作为训练集的一部分,思路如图3.2所示。这样基于的假设是,不同的攻击方法生成的对抗样本在真实的灰盒模型表现上会有差异,有些图片依然能被灰盒模型正确识别。将n个样本集集合,就可以构建出完全将灰盒攻击成功的图片集。

第二部分为Stanford Dogs数据集中随机选取的8000张图片和原始的120张图片,这些图片的选取是为了保持模型的泛化能力。
随机梯度反向
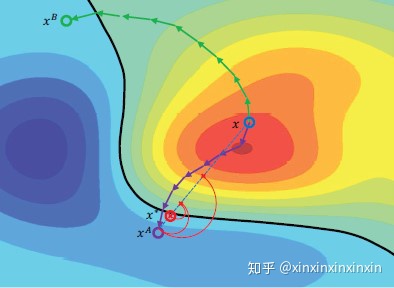
- 大粒度 此方法受启发于[2],论文中采取双路寻优,一路采用常规方法梯度上升,如图中绿线所示。另一路先采取梯度下降到达这一分类局部最优再进行梯度上升,以期找到更快的上升路径,如图3.3中蓝线所示。 而本人在实现过程中,对其进行简化,仅在迭代的第一步进行梯度下降。
- 小粒度 随机选取梯度中5%进行取反,可视为像素粒度的梯度反向,反转比例为一超参数。
添加高斯噪声
此方法受启发于[6],论文作者认为攻击模型的梯度具有噪声,损害了迁移能力。论文作者用一组原始图片加噪声后的梯度的平均代替原来的梯度,效果得到提升。
限定可变化的像素范围
将图片变动的像素点限定在梯度最大的5%。
三通道梯度平均
该方法受启发于[3],文中,作者随机在图像中选择max_pixels个点 在多个信道中同时进行修改。因此我尝试了两种方法,一是只计算R或G或B通道的梯度,三个通道减去相同的梯度。二是将三通道的梯度进行平均。从结果来看,后者更有效,提分明显。
攻击后进行目标攻击
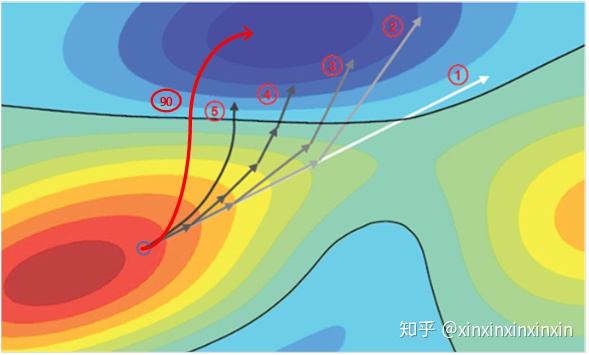
此方法受启发于[2],作者在成功越过分界线后进行消除无用噪声操作,作者认为此举可以加强对抗样本的迁移能力。 我的做法与此不同,我认为不仅要越过边界,还要走向这个错误分类的低谷。此举依据的假设是:尽管不同模型的分界线存在差异,模型学到的特征应是相似的。思路如图3.4中红色箭头所示,带有圆圈的数字表示迭代步数。 因此,在成功攻击之后,我又添加了两步定向攻击,目标为攻击成功时被错分的类别。在集成攻击时,目标为被错分类别的众数。
小扰动截断
使用上述方法后,我的结果在95-96分之间波动,为进一步提升成绩,我选用最高分96.53分图片进行后处理。后处理方法为:将攻击后的图片与原图片进行对比,对一定阈值以下的扰动进行截断。 经过不断上探阈值,发现阈值为17(图片的像素范围为0-255)的时候效果最好。此方法提分0.3左右。
参考文献
[1] Liu Y , Chen X , Liu C , et al. Delving into Transferable Adversarial Examples and Black-box Attacks[J]. 2016.
[2] Shi Y , Wang S , Han Y . Curls & Whey: Boosting Black-Box Adversarial Attacks[J]. 2019.
[3] Narodytska N , Kasiviswanathan S P . Simple Black-Box Adversarial Perturbations for Deep Networks[J]. 2016.
[4] Huang Q , Katsman I , He H , et al. Enhancing Adversarial Example Transferability with an Intermediate Level Attack[J]. 2019.
[5] https://www.cs.cmu.edu/~sbhagava/papers/face-rec-ccs16.pdf
[6] Understanding and Enhancing the Transferability of Adversarial Examples
代码使用说明
代码开源在https://github.com/sleepingxin/BAIDU_AIAdversialAttack
- python3
- paddle
- numpy
在本目录下输入
python 9model_ensemble_attack.py
python pert_drop.py结果保存在posopt_output_image














 972
972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









