






网上介绍一致性hash的文章很多,但在应用方面,基本都是通过一些无状态的应用来介绍如何通过一致性哈希做动态均衡,动态伸缩。
本文通过一个分布式Actor的应用场景介绍一致性hash在有状态应用中需要注意的问题。
分布式Actor服务
在网游服务端中存在一个actor对象,这个actor对象作为玩家在服务端的代理,玩家发出的所有操作必须都经由这个actor对象来执行。actor对象通过唯一id标识(例如唯一的userid),必须确保任何时刻,相同id的actor对象最多只能存在一个,
我们从玩家的消息流开始分析:
- 玩家发出操作请求,请求被网关接收到。
- 网关接收到请求后,根据请求携带的唯一id,通过一致性hash确定一个服务节点,将请求发往服务节点。
- 节点接收到请求,查找actor对象,如果对象存在将请求交给actor处理,否则,创建actor对象,让后将请求交给actor对象处理。
接着看下当集群成员发生变更的时候会发生什么情况,假设是新增一个节点D2,如下图:
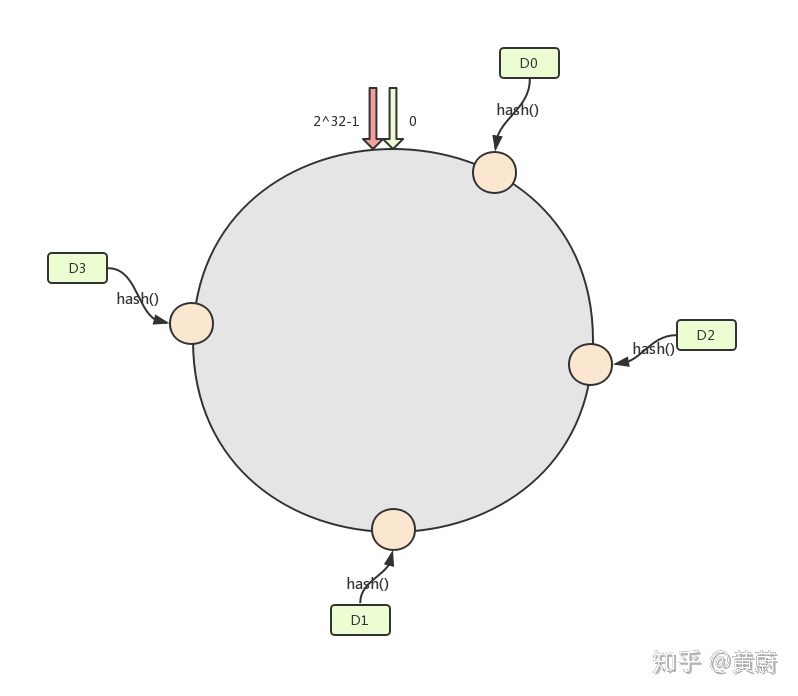
在D2加入集群前,D1服务的id范围是(D0,D1],因此D1会欣然接受userid满足(D0,D1]的玩家请求。假设此时,userid=D2的actor对象已经在节点D1上存在,然后D2加入集群,在D1和网关应用新配置前,网关将userid=D2的请求发往D1,因为D1尚未应用新配置,它会欣然接受操作请求。之后网关应用了新配置将userid=D2的请求发往D2,D2创建userid=D2的actor对象,并处理请求。在这个时间点上在D1和D2上同时存在userid=D2的Actor对象。
导致这个问题的原因是参与消息处理流的节点无法在同一时刻应用最新的成员配置信息。这个问题现有介绍一致性hash的文章基本没有提到过,因为它们都是用无状态服务举例的,请求交给任何一个节点处理都可以。
通过分布式锁解决
为了不违背user对象全局唯一的约束,可以通过提供分布式锁来实现。
节点在第一次接收到请求时创建user,通过setNx指令将userid和节点id写入分布式锁。如成功,创建userd对象。如果失败通告网关重试。通过分布式锁的get指令获取user对象所在节点。自己尝试更新最新视图,同时通告user对象所在节点发生冲突。user对象所在节点接收到冲突通告后尝试更新最新视图,并根据最新视图判断自己是否合法的user服务方,如果不是销毁user对象,释放锁。
如何让各节点对成员变更达成共识
前面介绍了使用分布式锁来避免避免actor重复创建的问题,但引起这个问题的根本原因还没有解决,问题的根本原因就是各节点无法对成员变更达成共识。
成员变更分两种情况:
- 新增一个节点:如新增加D2,D1中部分actor将要转移到D2上,因此,需要D1和D2对成员变更达成共识。
- 移除一个节点: 如移除D2,D2中的actor将要转移到D0和D1,因此,需要D0,D1,D2对成员变更达成共识。
分布式环境中存在的问题:
- 消息延迟及丢失
- 节点故障重启
- 节点永久故障
我们需要一套协议,在容忍以上故障的情况下使得参与成员变更的节点对变更配置达成共识。
算法
关键信息:
- 当前生效的配置,数据库中保存。
- 当前尚未完成的变更事务,数据库中保存。
- 当前事务编号,持久化到本地磁盘。
进程的启动
进程启动后首先从数据库拉取当前配置信息,如果发现自己在配置中,进入正常服务状态。 否则,尝试从磁盘读取事务编号,根据事务编号进入事务恢复流程,具体流程在下面介绍。
事务处理协议
事务参与方: 协调者,上下游节点、待新增/下线节点。
- 协调者递增事务号,将事务号写入磁盘,成功后向数据库写入事务状态,向参与者发出prepare请求,启动定时器,如果定时器到期未能收到所有参与者的应答,清理数据库事务状态, 向所有参与者发送cancel,终止事务。
- 参与者接收到prepare请求后,检查自身是否有actor需要迁移,且这些需要迁移的actor上是否有任务正在实行,如果没有发送prepare响应。如果有则等到所有这些actor的任务都处理完之后发送prepare响应。(接收到prepare后,对于新到的待迁移actor的请求都不再处理,在队列中hold住请求)
- 协调者在定时器到期前收到所有参与者的prepare应答,向数据库记录事务成功,写入新配置,向所有参与者发送commit.
- 如果参与者接收到cancel,终止变更流程,恢复正常服务状态(如果有hold住的请求,恢复执行)。
- 接到commit,应用新配置(如果有hold住的请求,把这些请求转发到迁移目标点)。
故障处理:
- commit/cancel丢失
commit/cancel丢包
参与者进入prepare状态后,设置定时器,定时向数据库拉取事务状态,根据事务状态commit/cancel事务(如发现事务commit,拉取最新配置并应用)。
参与者崩溃重启
通过磁盘读取事务号,如果发现事务号非0,则向数据库获取事务信息,并判断事务号是否一致。如果一致根据事务状态commit/cancel事务(如发现事务commit,拉取最新配置并应用),如此时事务尚未完成,启动与commit/cancel丢包一样的处理流程。
- 协调者在发出prepare之后崩溃重启
协调者重启后从数据库读取当前事务状态,如果发现事务尚未完成,重新发起事务。
- 协调者发出prepare之后永久故障
此时需要另外选出一个协调者,重新发起事务(可通过raft选主,由leader来执行)。
虚拟节点
如果启用了虚拟节点,一个物理节点关联的上/下游物理节点数量就可能非常多,配置变更事务涉及到的参与者变多,一方面使得协议的执行变慢,另一方面增大了失败的可能性,因此,如果启用虚拟节点,配置变更应该是针对虚拟节点的,即每次增加/删除一个虚拟节点,当物理节点上所有的虚拟节点都从配置中移除,物理节点才能安全下线。















 1375
1375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









