







迭代
如果给定一个lisp或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历称为迭代(Iteration)。在Python中,迭代是通过for…… in……来完成的(而很多语言比如C语言,迭代list是通过下标完成的),for……in……不仅可以用在list或tuple上,还可以作用在其他可迭代对象上,只要是可迭代对象,无论有无下标,都可以迭代,例如dict虽然没有下标,也可以迭代。
字典dic可以迭代
【例】字典dic可以迭代
dic={'Name':'王海','Age':17,'Class':'计算机一班'}
for key in dic:#先获取key,然后获取value
print(key,dic.get(key))#写成print(key,dic[key])也可以

上面的程序可以利用items()改写成:
dic={'Name':'王海','Age':17,'Class':'计算机一班'}
for key,value in dic.items():#对字典items()方法返回的元组列表进行序列解包
print(key,value)#
运行结果相同。
使用for循环时,只要作用于一个可迭代对象,for循环就可以正常运行。
enumerate()函数
enumerate()函数将一个可遍历对象组合为一个索引序列,同时列出数据和数据下标(成为索引-元素对)
该函数语法如下:
enumerate(sequence,[start=0])
其中:
sequence -- 一个序列、迭代器或其他支持迭代对象。
start -- 下标起始位置。
函数返回enumerate(枚举) 对象
(enumerate可翻译为列举。而enum表示编程语言中的一种数据类型:枚举类型。)
【例】
names=['Michael',"Bob",'Tracy',"小明"]
for i,value in enumerate(names):#enumerate()函数将一个可遍历对象组合为一个索引序列,同时列出数据和数据下标
print(i,value)
【例】求列表元素的n*n值
li= [1,2,3,4,5,6,7,8,9]
for ind,val in enumerate(li):
li[ind] = val * val
print(li)

【例】
names=['Michael',"Bob",'Tracy',"小明"]
list1=list(enumerate(names))
print(list1)
print(f"names[0]={names[0]},names[1]={names[1]}")
list2=list(enumerate(names,start=1))#指定起始下标(只是修改起始下标,遍历到的元素相同
print(list2)
print(f"names[0]={names[0]},names[1]={names[1]}")


遍历迭代列表输出下标(索引)和值的几种for……in……写法
⑴【例】
fruits=["banana","apple","mango"]
for s in fruits:
print(f"下标:{fruits.index(s)},值:{s}")

⑵【例】
fruits=["banana","apple","mango"]
n=len(fruits)
for i in range(n):
print(f"下标:{i},值:{fruits[i]}")
运行结果同上。
⑶【例】利用enumerate()函数
fruits=["banana","apple","mango"]
for i,s in enumerate(fruits):
print(f"下标:{i},值:{s}")
运行结果同上。
附:
fruits=["banana","apple","mango"]
for i,s in enumerate(fruits,3):#只是改变了起始序号
print(f"序号:{i},值:{s}")

【例】已知列表namelist = ['王源','贾玲','沈腾','欧阳娜娜','邓超','陈赫','鹿晗','郑凯','王祖蓝','Angelababy','李晨'],删除列表removelist = ['王源','贾玲','沈腾','欧阳娜娜','宋小宝'],要求将removelist列表中的每个元素从namelist中移除(属于removelist,但不属于namelist的忽略即可)
程序一:
namelist = ['王源','贾玲','沈腾','欧阳娜娜','邓超','陈赫','鹿晗','郑凯','王祖蓝','Angelababy','李晨']
removelist = ['王源','贾玲','沈腾','欧阳娜娜','宋小宝']
for name1 in namelist:#
for name2 inremovelist:#
if name2 in namelist:
namelist.remove(name2)
print(namelist)

程序二:只用一个for……in……
namelist= ['王源','贾玲','沈腾','欧阳娜娜','邓超','陈赫','鹿晗','郑凯','王祖蓝','Angelababy','李晨']
removelist= ['王源','贾玲','沈腾','欧阳娜娜','宋小宝']
for name in removelist:
if name in namelist:
name list.remove(name)
print(namelist)
运行结果同上。
以下代码错误:
namelist= ['王源','贾玲','沈腾','欧阳娜娜','邓超','陈赫','鹿晗','郑凯','王祖蓝','Angelababy','李晨']
removelist= ['王源','贾玲','沈腾','欧阳娜娜','宋小宝']
for name in namelist:#
if name in removelist:
namelist.remove(name)
print(namelist)
运行结果:

错误原因:第一次匹配到'王源',从namelist中删除之,namelist变成['贾玲','沈腾','欧阳娜娜','邓超','陈赫','鹿晗','郑凯','王祖蓝','Angelababy','李晨'],但是序列在迭代,第二次执行__next__返回的是列表中的'沈腾','贾玲'被忽略了。……如此循环直到容器中没有更多元素。

迭代器
迭代器可以记住遍历的位置。
迭代器对象从第一个元素开始访问,直到所有的元素被访问结束。
迭代器只能往前不会后退。
也可以说:可以被next()函数调用并不断返回下一个值的对象称为迭代器(Iterator)
生成器都是Iterator对象。
list、dict、str虽然是可迭代对象Iterable,但不是迭代器,可以使用iter()把list、dict、str等可迭代对象Iterable变成迭代器Iterator。
迭代器有两个基本的方法:iter()和next()
列表、元组、字符串都可用于创建迭代器。

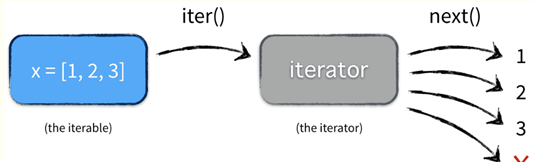
【例】
list1=[1,2,3,4]
it=iter(list1)#创建迭代器对象
print(f"第一次输出:{next(it)}")
print(f"第二次输出:{next(it)}")

以下程序错误:
list1=[1,2,3,4]
print(f"第一次输出:{next(list1)}")
print(f"第二次输出:{next(list1)}")
提示以下信息:列表不是迭代器

【例】迭代器对象可以使用常规for语句进行遍历
list=[1,2,3,4]
it=iter(list)#创建迭代器对象
for x in it:
print(x,end=' ')
运行结果:
1 2 3 4

生成器
生成器(generator)本质上也是迭代器,不过它比较特殊。
对于可以用某种算法推算得到的多个数据,生成器并不会一次性生成它们,而是什么时候需要,才什么时候生成。
前面学过列表生成式,通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器(generator)。
生成器是一个特殊的程序,可以被用作控制循环的迭代行为,python中生成器是迭代器的一种,使用yield返回值函数,每次调用yield会暂停,而可以使用next()函数和send()函数恢复生成器。
要创建一个generator,有很多种方法。
第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
L = [x * x for x in range(10)]#L是一个列表
g = (x * x for x in range(10))#g是一个迭代器generator
print(L)
print(g)
for n in g:
print(n,end=" ")

创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
我们创建了一个generator后,基本上不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
方法二:如果一个函数中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。调用函数就是创建了一个生成器(generator)对象。
【例】斐波拉契数列的推算规则是:第三项开始,每一项是前两项之和。
def fib(max):
n,a,b =0,0,1
while n max:
yield b
a,b =b,a+b#相当于t=a+b,a=b,b=t
n = n+1
return 'done'
for i in fib(10):
print(i)
运行结果:

上面的fib函数就是一个generator。
生成器的创建方式,大体分为以下 2 步:
①定义一个以yield关键字标识返回值的函数;
②调用刚刚创建的函数,即可创建一个生成器。
〖例题程序〗
def intNum():
print("开始执行")
for i in range(5):
yield i
print("继续执行")
num=intNum()
#以上创建了一个num生成器对象
print(next(num))#调用 next() 内置函数
print("标记1")
print(num.__next__())#调用 __next__() 方法
print('标记2')
for i in num:#通过for循环遍历生成器
print(i)

num=intNum()创建了一个 num 生成器对象。显然,和普通函数不同,intNum() 函数的返回值用的是 yield 关键字,而不是 return 关键字,此类函数又成为生成器函数。
和 return 相比,yield 除了可以返回相应的值,还有一个更重要的功能,即每当程序执行完该语句时,程序就会暂停执行。不仅如此,即便调用生成器函数,Python 解释器也不会执行函数中的代码,它只会返回一个生成器(对象)。
要想使生成器函数得以执行,或者想使执行完 yield 语句立即暂停的程序得以继续执行,有以下 2 种方式:
①通过生成器(上面程序中的 num)调用 next() 内置函数或者 __next__() 方法;
②通过 for 循环遍历生成器。
参见上面程序的8~12行。
分析一下程序的执行流程:
1) 首先,在创建有 num 生成器的前提下,通过其调用 next() 内置函数,会使 Python 解释器开始执行 intNum() 生成器函数中的代码,因此会输出“开始执行”,程序会一直执行到yield i,而此时的 i==0,因此Python 解释器输出“0”。由于受到 yield 的影响,程序会在此处暂停。
2) 然后,我们使用 num 生成器调用 __next__() 方法,该方法的作用和 next() 函数完全相同(事实上,next()函数的底层执行的也是 __next__() 方法),它会是程序继续执行,即输出“继续执行”,程序又会执行到yieldi,此时 i==1,因此输出“1”,然后程序暂停。
3) 最后,我们使用 for 循环遍历 num 生成器,之所以能这么做,是因为 for 循环底层会不断地调用 next() 函数,使暂停的程序继续执行,因此会输出后续的结果。

关于函数参见下一节
















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









