





本文提出一种用于训练CLIP的简单而有效的方案FLIP(Fast Language-Image Pre-training, FLIP),它在训练过程中对图像块进行大比例的随机Mask移除。所提方案取得了更好的精度与训练时间均衡,相比无Mask基线方案,所提FLIP在精度与训练速度方面具有大幅改善(前期400M对image-text)。
paper:https://arxiv.org/abs/2212.00794
本文提出一种用于训练CLIP的简单而有效的方案FLIP(Fast Language-Image Pre-training, FLIP),它在训练过程中对图像块进行大比例的随机Mask移除。Mask机制使得我们可以在有限周期内学习到更多的image-text数据对,同时具有更少的内存占用。所提方案取得了更好的精度与训练时间均衡,相比无Mask基线方案,所提FLIP在精度与训练速度方面具有大幅改善(前期400M对image-text)。
受益于加速训练能力,我们对扩展模型尺寸、数据集大小、训练周期进行了探索,同时取得了喜人的结果。
方案
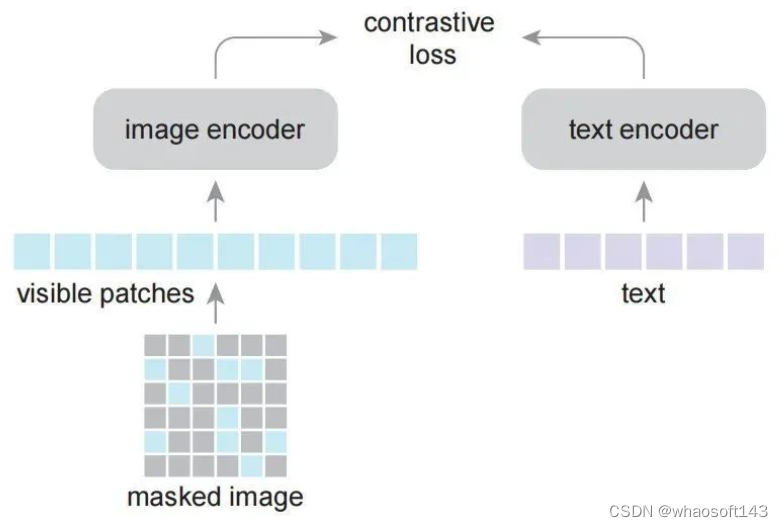
上图为所提FLIP方案示意图,它由两部分构成:
- Image Masking: 该采用ViT对图像进行编码,参考MAE对图像块进行大比例Mask丢弃(如50%、75%),这种处理方式还可以减少图像编码耗时与内存占用。
- Text Masking:与此同时,我们还可以对text执行类似Image的Mask处理(可选想发)。当执行Mask时,我们仅对可见token进行编码处理。这不同于BERT的处理机制:采用Learned Mask Token进行替换。这种稀疏计算同样可以一定程度减少文本编码耗时。不过,由于文本编码器比较小,这里的加速不会导致更好的均衡。
- Objective:Image/Text编码器采用对比损失进行训练优化。在这里,作者并未像MAE那样使用重建损失。丢弃解码器与重建损失取得了进一步的加速。
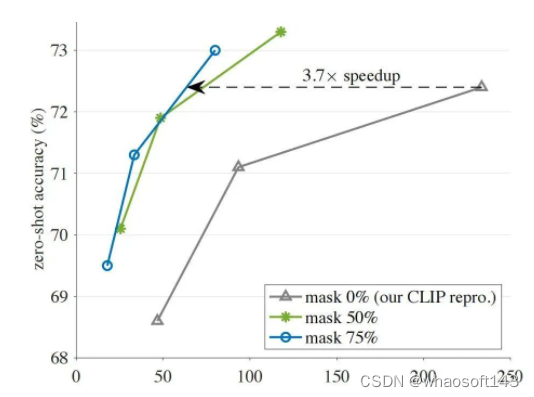
- Unmasking:尽管编码器是在Masked图像上进行的预训练,但它可以像MAE那样直接作用到无干扰的图像,此可作为对标的基线。为进一步减少因Mask导致的分布差异,作者将Mask比例设为0并进行少量的连续预训练。这种处理机制可以取得有利的精度/耗时均衡。
具体实现
在实现方面,作者参考CLIP与OpenCLIP并进行了以下几点改动:
- 图像编码器采用的是ViT,但在Patch Embedding后并未使用额外的LayerNorm,此外在图像编码尾部添加了GAP。图像输入尺寸为224.
- 本文编码器为Non-AutoRegressive Transformer,作者采用了WordPiece序列化方案。序列长度通过pad或cut固定为32。
- 图像编码器与文本编码器的输出投影到相同的嵌入空间,然后经LTP(Learnable Temperature Parameter)缩放后计算两者的Cosine相似性。
- 采用JAX实现,在TPUv3集成进行训练。
本文实验
消融实验结果对比如下:
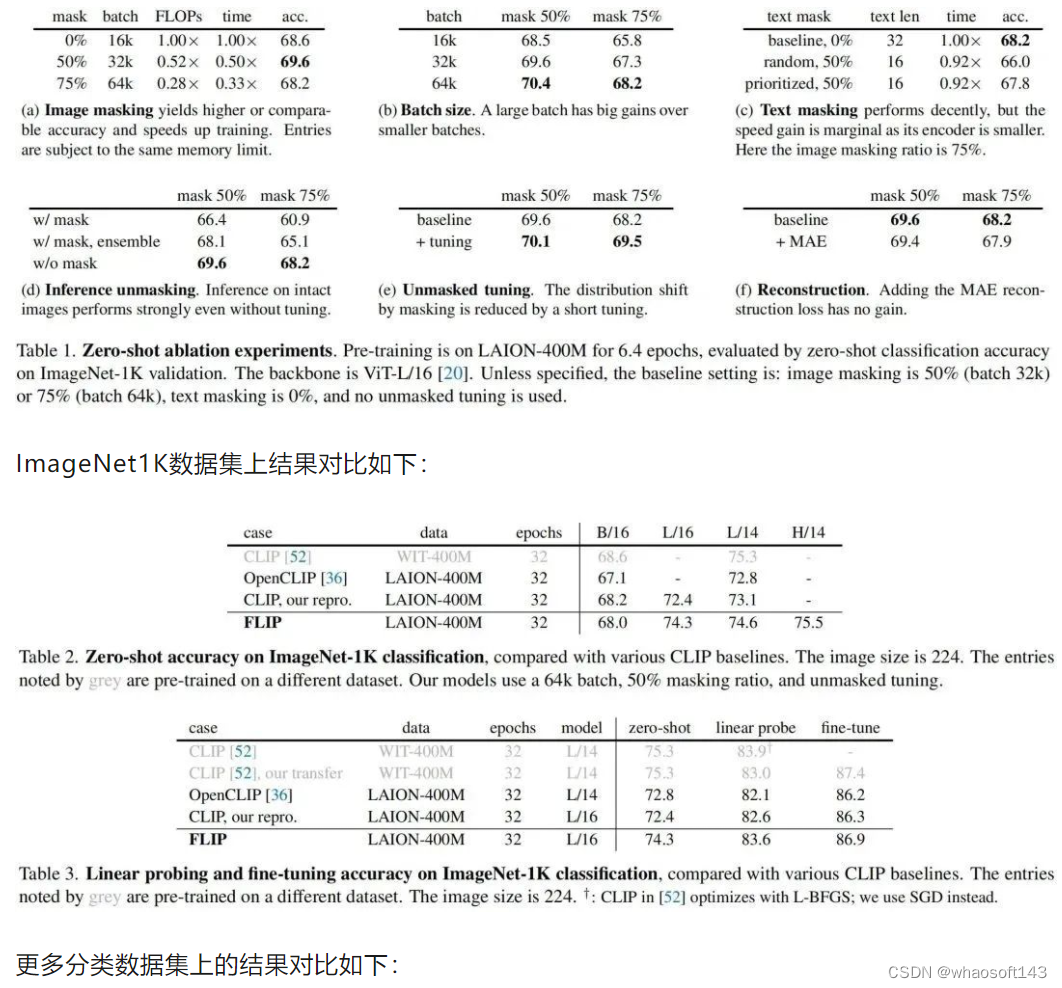
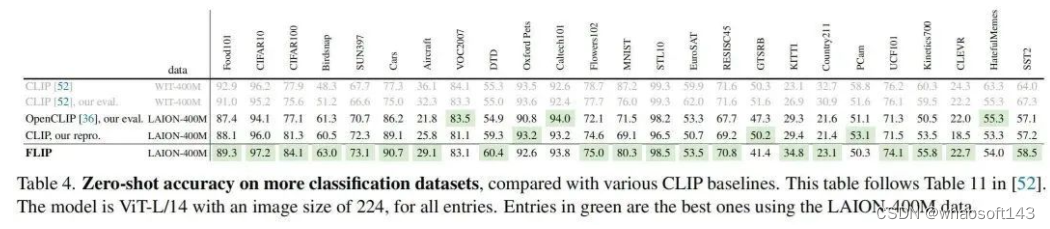
更多消融实验与实验结果请查看原文,为避免误导各位大佬,这里直接略过。















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









