







 本文详细介绍了如何使用Python实现k近邻(kNN)算法,包括算法原理、环境配置、数据处理和可视化。通过机器学习实战这本书,演示了kNN在约会网站配对和手写识别系统的应用,展示了算法的实现过程和测试结果。
本文详细介绍了如何使用Python实现k近邻(kNN)算法,包括算法原理、环境配置、数据处理和可视化。通过机器学习实战这本书,演示了kNN在约会网站配对和手写识别系统的应用,展示了算法的实现过程和测试结果。
机器学习实战这本书是基于python的,如果我们想要完成python开发,那么python的开发环境必不可少:
(1)python3.52,64位,这是我用的python版本
(2)numpy 1.11.3,64位,这是python的科学计算包,是python的一个矩阵类型,包含数组和矩阵,提供了大量的矩阵处理函数,使运算更加容易,执行更加迅速。
(3)matplotlib 1.5.3,64位,在下载该工具时,一定要对应好python的版本,处理器版本,matplotlib可以认为是python的一个可视化工具
好了,如果你已经完成了上述的环境配置,下面就可以开始完成真正的算法实战了。
一,k近邻算法的工作原理:
存在一个样本数据集,也称作训练数据集,并且样本集中每个数据都存在标签,即我们知道样本集中每个数据与所属分类的对应关系。当输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似的数据的分类标签。一般来水,我们只选择样本数据集中最相似的k个数据(通常k不大于20),再根据多数表决原则,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
k近邻算法的一般流程:
(1)收集数据:可以采用公开的数据源
(2)准备数据:计算距离所需要的数值
(3)分析数据:剔除垃圾信息
(4)测试算法:计算错误率
(5)使用算法:运用在实际中,对实际情况进行预测
二,算法具体实施过程
(1)使用python导入数据,代码解析如下:
#-------------------------1 准备数据-------------------------------#可以采用公开的数据集,也可以利用网络爬虫从网站上抽取数据,方式不限#-------------------------2 准备数据-------------------------------#确保数据格式符合要求#导入科学计算包(数组和矩阵)
from numpy import *
from os importlistdir#导入运算符模块
importoperator#创建符合python格式的数据集
defcreateDataSet():#数据集 list(列表形式)
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])#标签
labels=['A','A','B','B']return group, labels
(2)我们可以使用matplotlib 对数据进行分析
在python命令环境中,输入如下命令:
当输入如下命令时:
#导入制图工具
importmatplotlibimportmatplotlib.pyplot as plt
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2])
plt.show()
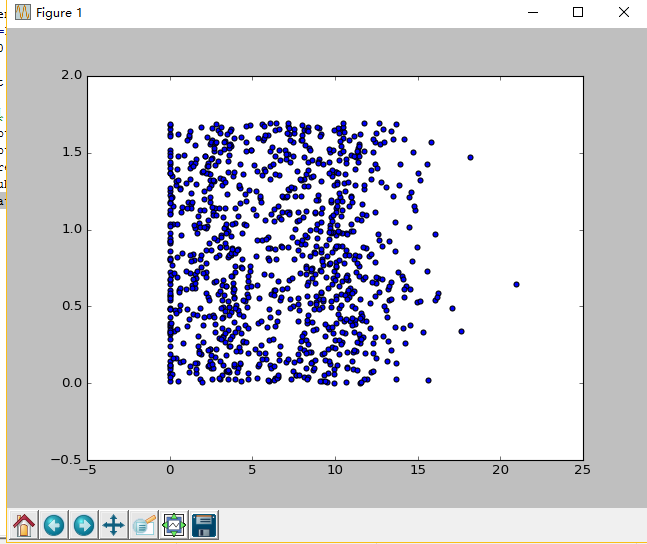
从上面可以看到,由于没有使用样本分类的特征值,我们很难看到比较有用的数据模式信息
一般而言,我们会采用色彩或其他几号来标记不同样本的分类,以便更好的理解数据,重新输入命令:
#导入制图工具
importmatplotlibimportmatplotlib.pyplot as plt
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









