






目录
前言
记录学习KNN算法
一、KNN算法介绍
KNN(K-Nearest Neighbor,k近邻)算法是一种基本的分类与回归方法,它的基本思想是:在特征空间中,如果一个样本的k个最近邻居大多数属于某一类别,则该样本也属于这一类别。
在KNN算法中,首先需要度量样本之间的距离,通常采用欧氏距离或曼哈顿距离。然后,选择一个合适的k值(一般通过交叉验证选取),对于每个待分类的测试样本,在训练数据集中找到其k个最近邻居,根据它们所属的类别进行投票,得票最多的类别即为该测试样本的分类结果。
KNN算法简单易实现,但是在处理大规模数据时计算量较大,因此需要考虑优化计算效率,如通过树形结构(KD树)等方式加速搜索最近邻居的过程。
二、KNN算法原理
1.原理
KNN算法的原理就是新来的样本距离该样本最近的K个样本为他们自己所在的类型投票,票数最多的类型作为新来的样本的类型
例: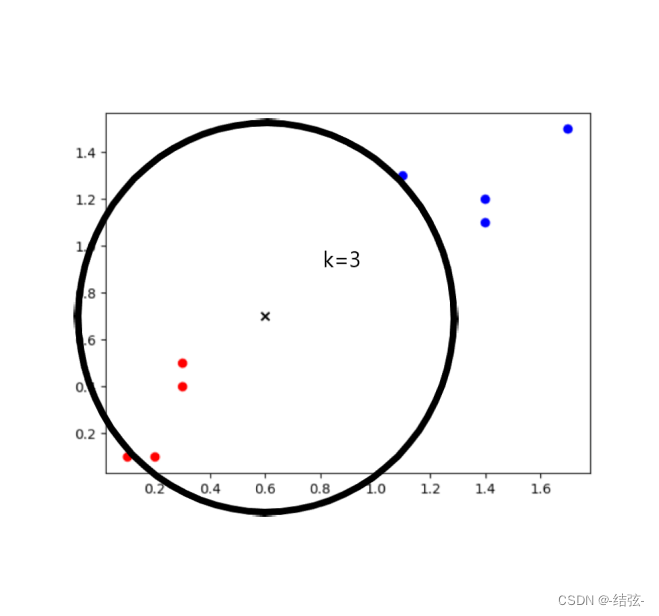
当k为3的时候距离×(新来的样本)最近的三个样本都为🔴,因此将×(新来的样本)归类为🔴

当k为3的时候距离×(新来的样本)最近的五个样本种有四个为🔴,一个为🔵,多数为🔴,因此将×(新来的样本)归类为🔴
2.欧氏距离
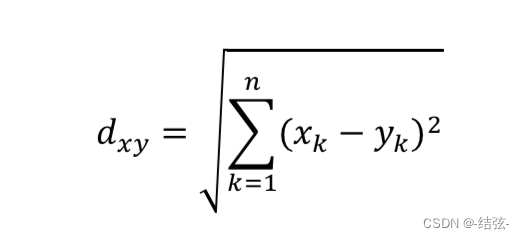
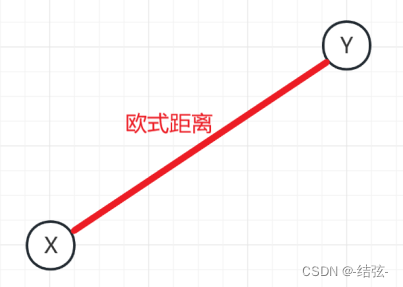
欧式距离就是两点之间连线的距离
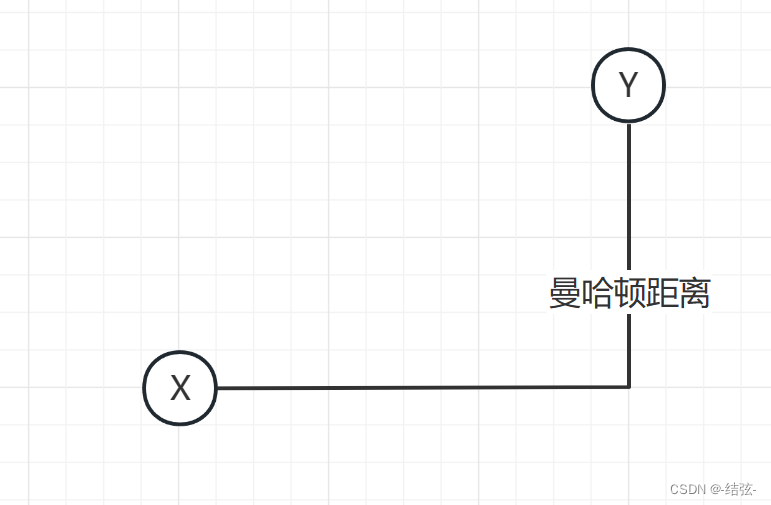
3.曼哈顿距离

曼哈顿距离是两点之间在每个轴上相差的绝对值的和
三、KNN算法实例
1.代码
#导包
import numpy as np
import matplotlib.pyplot as plt#KNN算法
def knn(newInput, dataSet, labels, k):
# 计算欧氏距离
distances = np.sqrt(np.sum((dataSet - newInput) ** 2, axis=1))
#将距离进行排序
sortedDistancesIndices = distances.argsort()
#创建空数组
k_labels = []
#循环取出前k个样本,并将样本的类型存入 k_labels数组
for i in range(k):
k_labels.append(labels[sortedDistancesIndices[i]])
# 对k个样本的类型进行比较,返回最多的类别作为新样本的类别
return max(k_labels, key=k_labels.count)# 测试代码
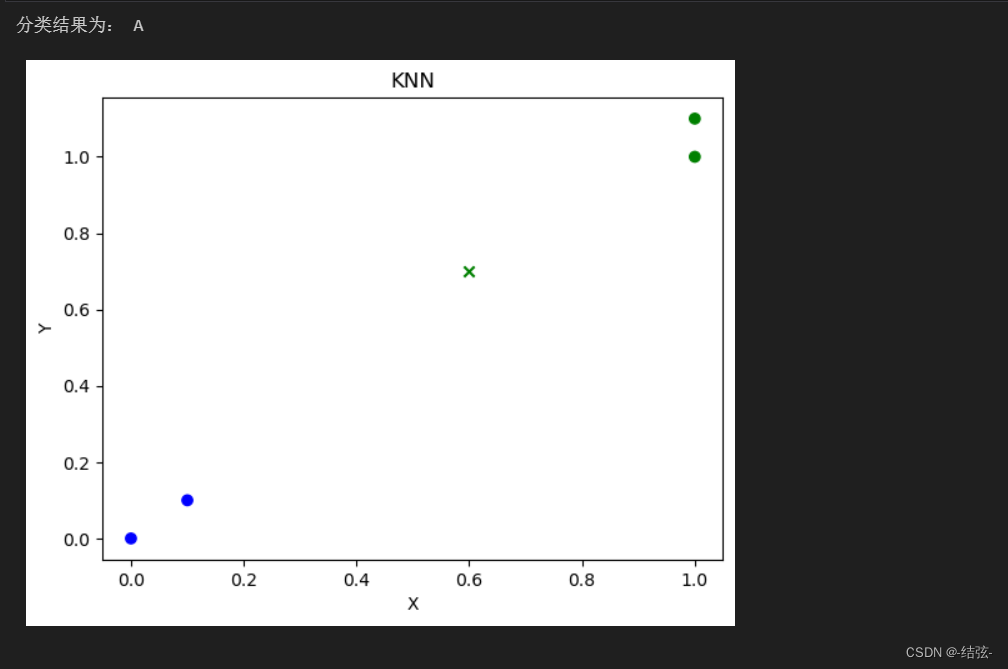
dataSet = np.array([[1.0, 1.1],
[1.0, 1.0],
[0.0, 0.0],
[0.1, 0.1]])
labels = ['A', 'A', 'B', 'B']
newInput = np.array([0.6, 0.7])
k = 3
result = knn(newInput, dataSet, labels, k)
print("分类结果为:", result)# 绘制散点图
#创建散点图窗口和坐标绘制
fig, ax = plt.subplots()
#将dateSet中的第一列和第二列分别作为X轴和Y轴并把A类点用绿色,B类点用蓝色
ax.scatter(dataSet[:,0], dataSet[:,1], c=[{'A': 'g', 'B': 'b'}[label] for label in labels])
#将newInput中的第一位和第二位分别作为X轴和Y轴并根据分类A类点用绿色,B类点用蓝色绘制×在散点图上
ax.scatter(newInput[0], newInput[1], c=[{'A': 'g', 'B': 'b'}[result]], marker='x')
#设置X轴和Y轴的名称
ax.set_xlabel('X')
ax.set_ylabel('Y')
#设置图像标题
ax.set_title('KNN')
#绘制图像
plt.show()
2.结果
总结
KNN算法简单而直观,容易理解和实现。但在实际应用中需要注意参数K的选择,距离公式的选择等















 1275
1275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









