







系列文章目录
C++高性能优化编程系列
深入理解软件架构设计系列
高级C++并发线程编程
C++技能系列
期待你的关注哦!!!

现在的一切都是为将来的梦想编织翅膀,让梦想在现实中展翅高飞。
Now everything is for the future of dream weaving wings, let the dream fly in reality.
如何实现线程池
一、要实现高效的线程池,可以考虑以下几点
-
控制线程数量: 线程池的大小应该根据系统资源状况和任务量来设置。 太少的线程会导致任务被阻塞,太多的线程则会消耗过多的系统资源。可以使用固定大小的线程池、可缓存的线程池或定时器线程池等方式来进行控制。
-
任务队列管理: 线程池应该有一个任务队列,用于存放等待执行的任务。 可以使用有界队列或无界队列来管理任务。有界队列可以控制任务的数量,而无界队列则可以接受任意数量的任务,但可能会导致内存溢出。
-
线程调度策略: 线程池应该有一个合适的线程调度策略,如先进先出、优先级等。可以使用线程池的预定义实现,或自定义实现。
-
线程错误处理: 线程池应该有一个错误处理机制,用于捕获线程执行过程中可能出现的异常,避免导致整个线程池崩溃。 可以使用try-catch语句或其他异常处理机制来处理异常。
-
监控和调优: 线程池应该有一个监控和调优机制,用于实时监控线程池的状态和性能,并进行相应的调整。 可以使用监控工具、性能分析工具等来进行监控和调优。
通过合理的设置线程池的大小、任务队列的管理、线程调度策略、错误处理机制和监控调优,可以实现高效的线程池,提高程序的并发性能和资源利用率。
二、实现线程池可以按照以下步骤进行
(1)确定线程池的基本参数: 包括线程池大小、任务队列大小、拒绝策略等。可以根据实际需求来设置这些参数。
(2)创建一个任务队列: 用于存放待执行的任务。可以使用队列数据结构,如ArrayBlockingQueue、LinkedBlockingQueue等。
(3)创建线程池类: 定义一个线程池类,包括线程池的初始化、提交任务、执行任务、关闭等方法。可以使用ThreadPoolExecutor类来实现线程池。
(4)初始化线程池: 在线程池类中,提供一个初始化方法,该方法会根据线程池大小创建固定数量的线程,并将它们放入空闲线程池中。
(5)提交任务: 线程池类提供一个提交任务的方法,用于向任务队列中添加待执行的任务。可以通过调用线程池类的execute方法来实现任务的提交。
(6)执行任务: 线程池会自动从任务队列中获取任务,并将其分配给空闲的线程来执行。任务执行完成后线程会返回到线程池中,等待下一个任务。
(7)关闭线程池: 线程池类提供一个关闭方法,用于停止线程池的运行。线程池在关闭时会等待所有任务执行完毕,然后终止所有线程。
(7)错误处理和监控: 可以在线程池中添加错误处理逻辑,捕获任务执行过程中的异常,避免线程池崩溃。同时,可以添加监控机制,实时监控线程池的状态和性能。
根据上述步骤,可以自定义一个线程池类,实现线程池的功能。在实际使用时,根据具体需求来设置线程池的参数和调优线程池的性能。
三、简单的C++线程池代码示例
该示例中的ThreadPool类实现了一个简单的线程池,包括线程的创建、任务的提交、执行和线程池的关闭等功能。在主函数中使用线程池提交了10个任务,每个任务输出自己的编号和执行它的线程ID。在执行完所有任务之后,程序等待2秒后退出。
请注意,该示例代码只是一个搞笑的演示,可能不具备线程安全和实际应用的一些重要细节,请勿用于实际生产环境。在实际使用线程池时,需要考虑更多的线程同步、任务拆分和异常处理等问题。
#include <iostream>
#include <thread>
#include <vector>
#include <queue>
#include <functional>
class ThreadPool {
public:
ThreadPool(int numThreads) : stop(false) {
for (int i = 0; i < numThreads; ++i) {
threads.emplace_back(std::thread([this](){
while (true) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(queueMutex);
condition.wait(lock, [this]{ return stop || !tasks.empty(); });
if (stop && tasks.empty()) {
return;
}
task = std::move(tasks.front());
tasks.pop();
}
task();
}
}));
}
}
~ThreadPool() {
{
std::unique_lock<std::mutex> lock(queueMutex);
stop = true;
}
condition.notify_all();
for (auto& thread : threads) {
thread.join();
}
}
template <typename FuncType>
void submit(FuncType f) {
{
std::unique_lock<std::mutex> lock(queueMutex);
tasks.emplace([f]() { f(); });
}
condition.notify_one();
}
private:
std::vector<std::thread> threads;
std::queue<std::function<void()>> tasks;
std::mutex queueMutex;
std::condition_variable condition;
bool stop;
};
int main() {
ThreadPool pool(4);
for (int i = 0; i < 10; ++i) {
pool.submit([i]() {
std::cout << "Task " << i << " executed by thread " << std::this_thread::get_id() << std::endl;
});
}
std::this_thread::sleep_for(std::chrono::seconds(2)); // 等待所有任务执行完
return 0;
}
-
使用std::thread::hardware_concurrency()来确定线程池中的线程数量,通常与处理器内核数相等,以充分利用系统资源。
-
使用std::function作为任务类型,可以接受任意可调用对象,使用Lambda表达式封装具体任务。
-
使用std::queue作为任务队列,通过std::mutex和std::condition_variable实现线程同步和互斥。
-
通过条件变量std::condition_variable的wait()和notify_one()来控制线程的挂起和唤醒。
四、 基于boost编写的源码库 - 线程池
4.1 基于boost编写的源码库地址
官网地址:http://threadpool.sourceforge.net
头文件目录:
4.2 boost线程池的先进先出、后进先出、优先级代码示例
#include <./boost/threadpool.hpp>
using namespace std;
using namespace boost::threadpool;
// Helpers
boost::mutex m_io_monitor;
void print(string text)
{
boost::mutex::scoped_lock lock(m_io_monitor);
cout << text;
}
template<typename T>
string to_string(T const & value)
{
ostringstream ost;
ost << value;
ost.flush();
return ost.str();
}
// An example task functions
void task_1()
{
Sleep(3000);
print(" task_1()\n");
}
void task_2()
{
Sleep(3000);
print(" task_2()\n");
//Sleep(10000);
}
void task_3()
{
print(" task_3()\n");
}
int task_4()
{
print(" task_4()\n");
return 4;
}
void task_with_parameter(int value)
{
Sleep(3000);
print(" task_with_parameter(" + to_string(value) + ")\n");
}
int loops = 0;
bool looped_task()
{
print(" looped_task()\n");
return ++loops < 5;
}
int task_int()
{
print(" task_int()\n");
return 23;
}
void fifo_pool_test()
{
pool tp;
tp.schedule(&task_1);
tp.schedule(boost::bind(task_with_parameter, 4));
if(!tp.empty())
{
tp.clear(); // remove all tasks -> no output in this test
}
size_t active_threads = tp.active();
size_t pending_threads = tp.pending();
size_t total_threads = tp.size();
size_t dummy = active_threads + pending_threads + total_threads;
dummy++;
tp.size_controller().resize(5);
tp.wait();
}
void lifo_pool_test()
{
lifo_pool tp;
tp.size_controller().resize(0);
schedule(tp, &task_1);
tp.size_controller().resize(10);
tp.wait();
}
void prio_pool_test()
{
prio_pool tp(2);
schedule(tp, prio_task_func(1, &task_1));
schedule(tp, prio_task_func(10,&task_2));
tp.schedule(prio_task_func(3000,boost::bind(task_with_parameter, 4)));
tp.schedule(prio_task_func(3500,boost::bind(task_with_parameter, 5)));
tp.schedule(prio_task_func(3600,boost::bind(task_with_parameter, 6)));
tp.schedule(prio_task_func(3900,boost::bind(task_with_parameter, 9)));
tp.schedule(prio_task_func(5000,boost::bind(task_with_parameter, 10)));
tp.schedule(prio_task_func(8000,boost::bind(task_with_parameter, 11)));
tp.schedule(prio_task_func(3000,boost::bind(task_with_parameter, 4)));
tp.schedule(prio_task_func(3500,boost::bind(task_with_parameter, 5)));
tp.schedule(prio_task_func(3600,boost::bind(task_with_parameter, 6)));
tp.schedule(prio_task_func(3900,boost::bind(task_with_parameter, 9)));
tp.schedule(prio_task_func(5000,boost::bind(task_with_parameter, 10)));
tp.schedule(prio_task_func(8000,boost::bind(task_with_parameter, 11)));
tp.schedule(prio_task_func(3000,boost::bind(task_with_parameter, 4)));
tp.schedule(prio_task_func(3500,boost::bind(task_with_parameter, 5)));
tp.schedule(prio_task_func(3600,boost::bind(task_with_parameter, 6)));
tp.schedule(prio_task_func(3900,boost::bind(task_with_parameter, 9)));
tp.schedule(prio_task_func(5000,boost::bind(task_with_parameter, 10)));
tp.schedule(prio_task_func(8000,boost::bind(task_with_parameter, 11)));
tp.schedule(prio_task_func(3000,boost::bind(task_with_parameter, 4)));
}
void future_test()
{
fifo_pool tp(5);
future<int> fut = schedule(tp, &task_4);
int res = fut();
}
int main (int , char * const [])
{
//fifo_pool_test();
//lifo_pool_test();
prio_pool_test();
//future_test();
system("pause");
return 0;
}
五、看看人家线程池怎么写的 - 要理解精髓
地址:https://github.com/xyygudu/ThreadPool
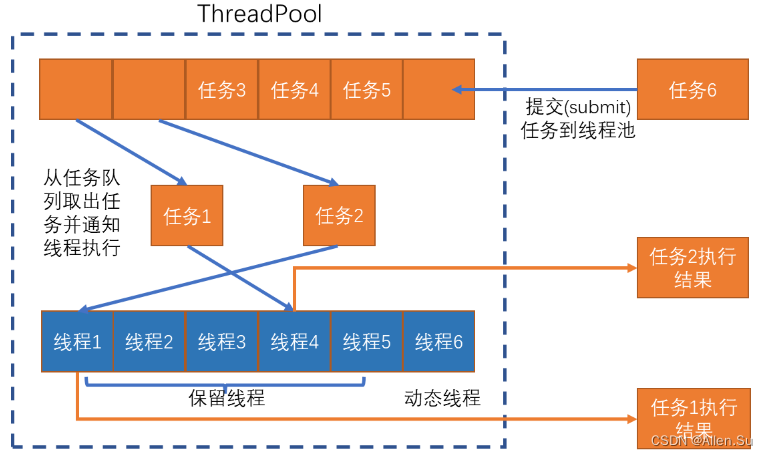
六、线程池应用场景与实践
6.1 服务器应用
线程池在服务器应用中具有广泛的应用场景。服务器通常需要处理大量客户端的请求。当客户端请求到达时,服务器可以使用线程池中的一个线程来处理请求,从而实现高效的任务调度和资源利用。
-
请求处理
将客户端请求分配到线程池中的线程进行处理,可以有效地实现负载均衡。服务器可以根据每个线程的负载情况,动态调整线程池中的线程数量。这有助于在高峰和低谷期间保持服务器的性能和响应能力。 -
建立连接
线程池用于建立新连接。当新客户端连接到达时,线程池中的一个线程可以进行握手和初始化操作。这样,在客户端连接请求较多时,线程池可以快速处理新连接,并避免创建大量短暂的线程。 -
数据读取/写入
线程池可用于处理与客户端的数据读取/写入操作。当读取/写入操作阻塞时,线程池中的其他线程仍然可以继续处理后续请求。 -
异步操作
线程池可用于实现异步操作。例如,服务器可能需要将客户端的操作结果写入日志或数据库。线程池中的一个线程可以执行这些操作,而不会影响其他正在处理请求的线程。 -
优势
采用线程池的服务器具有以下优势:
(1)提高响应速度。线程池中的线程可以立即开始执行新任务,而不需要等待操作系统创建新线程。
(2)提高资源利用率。通过复用线程,线程池可以减少创建和销毁线程的开销,节省资源。
(3)控制并发数量。线程池可以限制同时运行的线程数量,避免过多的线程竞争导致系统性能下降。
(4)提供可伸缩性。线程池可以根据系统负载动态调整线程数量,以适应不同的运行环境。
总之,在服务器应用中使用线程池有助于提高性能,降低资源消耗,并提供良好的可伸缩性。
6.2 数据处理与计算密集型任务
线程池在数据处理和计算密集型任务中表现出卓越的性能和易用性。大规模数据处理和计算密集型任务通常可以拆分成多个较小的子任务,这些子任务可以独立计算,并发执行。
-
数据处理任务
数据处理任务涉及对大量数据进行清洗、分类、检索等操作。将这些操作分配给线程池中的线程,可以加速数据处理过程。例如,在大规模数据集上执行全文搜索时,线程池可以将数据集分成多个子集,让每个线程在一个子集上搜索。这样数据处理过程可以并行执行,大大缩短任务的完成时间。 -
计算密集型任务
计算密集型任务需要进行大量的算术运算或逻辑运算,如图像处理、视频编解码和机器学习等。这些任务的特点是计算量大、执行时间长,通常需要高性能的计算资源。使用线程池可以充分利用多核处理器的计算能力,提高任务执行的效率。 -
数据并行与任务并行
在数据处理和计算密集型任务中,线程池可以采用数据并行和任务并行的策略。
(1)数据并行: 将数据集拆分成多个子集,各个线程对一个子集进行操作。数据并行适用于独立处理不同子集的任务。
(2)任务并行: 将任务拆分成多个子任务,各个线程执行一个子任务。任务并行适用于子任务之间存在依赖关系的场景。
根据任务特性及数据规模,可以选择合适的并行策略,并调整线程池中的线程数量以优化性能。 -
优势
在数据处理和计算密集型任务中使用线程池具有以下优势:
(1)提高执行速度。线程池可以充分利用多核处理器进行并发计算,缩短任务完成时间。
(2)降低资源消耗。通过复用线程,线程池减少了创建和销毁线程的开销。
(3)灵活调度。线程池可以根据任务的类型和数据规模动态调整线程数量,提供可伸缩性。
(4)简化编程模型。线程池封装了线程管理和任务调度,降低了编程难度和复杂性。
因此,在数据处理和计算密集型任务中使用线程池,可以提升任务执行效率,并简化并行计算的编程模型。
6.3 图形界面与事件驱动程序
线程池在图形界面和事件驱动程序中发挥重要作用。为了保持用户界面(UI)的流畅性,耗时的操作往往需要在线程池中的工作线程中执行,从而避免阻塞UI线程。
-
背景任务
在许多图形界面应用里,需要在后台执行一些耗时的任务,例如文件操作、网络请求、大量计算等。这些任务可以放入线程池中执行,以免阻塞UI线程。任务完成后,可以将结果通过回调函数或其他方式传递给UI线程进行显示。 -
异步事件处理
事件驱动程序需要对来自外部或内部的事件进行响应。这些事件可能有不确定的延迟。为了避免阻塞UI线程,可以将事件处理任务提交给线程池。这样,在处理多个事件时,UI线程能够在任何事件之间保持响应。 -
定时任务
一些图形界面应用需要在特定时间执行任务,例如动画、定时器等。将这些任务分配给线程池中的线程进行处理,可以确保计时器任务得到精确的触发时间,并且避免了UI线程的阻塞。 -
优势
在图形界面和事件驱动程序中使用线程池具有以下优势:
(1)保持UI流畅。线程池中的工作线程可以并发执行耗时任务,避免阻塞UI线程。
(2)优化资源利用。线程池管理工作线程,减少了创建和销毁线程的开销。
(3)异步事件处理。线程池提供了简单而高效的方式来处理来自内部或外部的事件,提高了程序的响应性。
(3)适应性调度。线程池可以根据任务负载动态调整线程数量,以适应程序运行时的变化。
通过线程池解决图形界面和事件驱动程序中的耗时任务和事件处理问题,有助于避免UI线程阻塞并提高程序响应性。同时,线程池优化了资源利用,适应程序运行时负载变化。
七、C++线程池高级应用与实际案例
7.1 基于负载均衡的任务分配策略
在处理多个并发任务时,负载均衡对线程池的性能和稳定性至关重要。以下策略有助于实现基于负载均衡的任务分配:
-
动态任务调度
动态任务调度意味着在线程池中实时监控各个线程的工作负载,以便在分配任务时考虑工作负载。当新任务进入线程池时,将其分配给当前工作负载最低的线程。任务执行的时间可能不一致,因此,选择负载最低的线程运行新任务有助于避免处理瓶颈。
实现动态任务调度,可以采用以下方法:
(1)轮询调度: 将每个新任务轮流分配到线程池中的线程。这种方法简单有效,但在某些情况下可能导致任务分布不均。
(2)最小负载优先: 按照线程的当前任务数量或已分配任务的大小来计算线程负载,将新任务分配给负载最低的线程。 -
线程负载监控
通过实时监控线程池中的各个线程,我们可以了解它们的负载状况,以便根据实际需求为其分配任务。可以使用以下指标来表示线程负载:
(1)当前任务数量
(2)等待处理的任务数量
(3)已完成任务数量
(4)线程的CPU使用率
将这些线程负载信息与任务调度相结合,可以使线程池更好地分配任务并适应负载变化。 -
求解最优分配
为实现最优的负载均衡,可以采用多种方法寻求最佳的任务分配方案。这里介绍两种可能的方法:
(1)贪心算法: 通过始终分配任务给当前负载最低的线程,使局部情况最优。这种方法的优点是简单易实现,但它可能无法找到全局最优解。
(2)模拟退火算法: 对于更复杂的负载均衡问题,可以使用模拟退火算法来求解全局最优解。虽然它可能找到接近全局最优的任务分配,但在某些情况下计算成本较高。
考虑到实现难度与运行效果,一般情况下,轮询调度和最小负载优先等简单方法已经能够有效地实现负载均衡。而在负载状况非常复杂的场景下,可以考虑使用模拟退火等优化算法寻求更好的解决方案。
7.2 线程池性能优化技巧
要提高线程池性能,需要关注以下几个方面:
-
适度并发
合适的并发级别不仅能充分利用系统资源,而且确保线程在有限的核心数量下高效运行。过低的并发级别会导致资源浪费,过高则可能导致线程竞争加剧,从而影响性能。可以根据以下经验值设置线程池中的并发级别:
(1)CPU绑定任务: 将并发级别设置为处理器核心数,这样可以确保在高计算密集型场景下充分利用CPU资源。
(2)I/O绑定任务: 在处理I/O密集型任务时,将并发级别设置为略高于处理器核心数,这样可以在等待I/O操作完成时允许其他线程继续执行,从而提高整体性能。 -
减少锁竞争
避免不必要的锁竞争对提高线程池性能非常重要。以下方法有助于减轻锁竞争的影响:
(1)无锁数据结构: 使用无锁(lock-free)数据结构,在多线程环境下能实现较好性能。
(2)细粒度锁: 将锁的范围限定在需要保护的资源或操作上,可减少冲突的可能性。
(3)读写锁: 如C++中的std::shared_mutex,在多读少写场景下,读写锁的性能要优于普通互斥锁(如std::mutex)。 -
编写高效代码
编写高效的线程任务代码对线程池的整体性能关键。以下原则有助于提高任务代码效率:
(1)避免重复计算和低效操作: 尽可能避免重复计算和低效操作,提高计算密集型任务的效率。
(2)充分利用C++容器和算法: 合理使用C++标准库中提供的容器和算法,以实现高性能且简洁的代码。
(3)掌握C++并发编程特性: 充分利用C++11/14/17/20中的并发和多线程支持工具,如std::thread, std::async, std::future, std::atomic等,避免低效、冗余的并发结构。
遵循这些原则并行动,可以显著提高线程池的性能和稳定性,确保在处理复杂多任务场景下具备良好的精度和效率。
八、实际案例分析与优秀实践
下面将通过几个实际案例分析线程池在各种场景下的应用,并探讨如何结合优秀实践提高任务处理效率。
8.1 案例一:并发网络服务
在处理并发网络服务时,线程池可以用来处理来自客户端的请求,例如建立连接、读写数据和处理任务等。通过将这些任务分配给线程池的线程处理,服务器可以获得更好的性能、响应能力和可扩展性。
(1)使用线程池处理连接、读写等网络任务,减小单线程服务器的压力。
(2)根据实际业务需求分配适当数量的线程来处理任务,以实现高性能和低延迟。
(3)合理采用负载均衡策略来分配任务,保证各个线程的工作负载接近平衡。
8.2 案例二:并行计算与数据处理
在处理并行计算和数据处理任务时,可以将这些任务划分为多个子任务,并将这些子任务分配给不同线程处理。线程池可以迅速实现高效率的并行计算,提高处理速度。
(1)将大型并行计算任务拆分为多个子任务,将子任务分配给线程池中的线程。
(2)根据任务不同特性和大小、数据规模定义不同的并行策略,如数据并行与任务并行。
(3)在处理复杂数值计算时,充分利用多核处理器的计算能力,优化并发级别。
8.3 案例三:高性能Web服务器
高性能Web服务器需要处理数以千计的并发请求。为了应对这种高压力场景,线程池是一种理想选择,可以将传入的请求处理和响应的任务分配到不同的线程。
(1)处理请求:将每个客户端连接的读/写请求分配给线程池中的线程进行处理。
(2)排队任务:为了避免长时间等待响应的请求阻塞其他任务,可以使用优先级队列或其他调度策略来安排任务的处理顺序。
(3)资源分离:将不同资源的处理任务分配给不同类型的线程池,以达到资源隔离和性能优化的目标。
通过将这些实际案例与优秀实践相结合,可以使线程池在各种不同场景下发挥出色的性能表现,从而提高我们的任务处理效率和稳定性。
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











