






unset前言unsetunset
对supabase进行深入的源码分析,以增加对项目的把控力。
需要了解的主要问题是:
多数NextJS项目中(包括Supabase官方的),在不同组件中,如果需要supabase,就会去实例化supabase对象,这会不会是多余的?是否每个supabase object都在与后端supabase维持长连接而消耗资源?是否创建一个全局的supabase就好了?
supabase在执行查询时,完整的流程是怎么样的?前端直接通过supabase object查询时,并发量大概是什么量级?
先看supabase github给出的整体结构图:

从图可知,一个supabase项目后面,其实是多个不同的服务。
unsetunset多supabase实例问题unsetunset
阅读多个supabase + nextjs项目,例如:https://github.com/vercel/nextjs-subscription-payments,都会发现项目中需要supabase时就直接调用createClient等方法创建supabase实例。
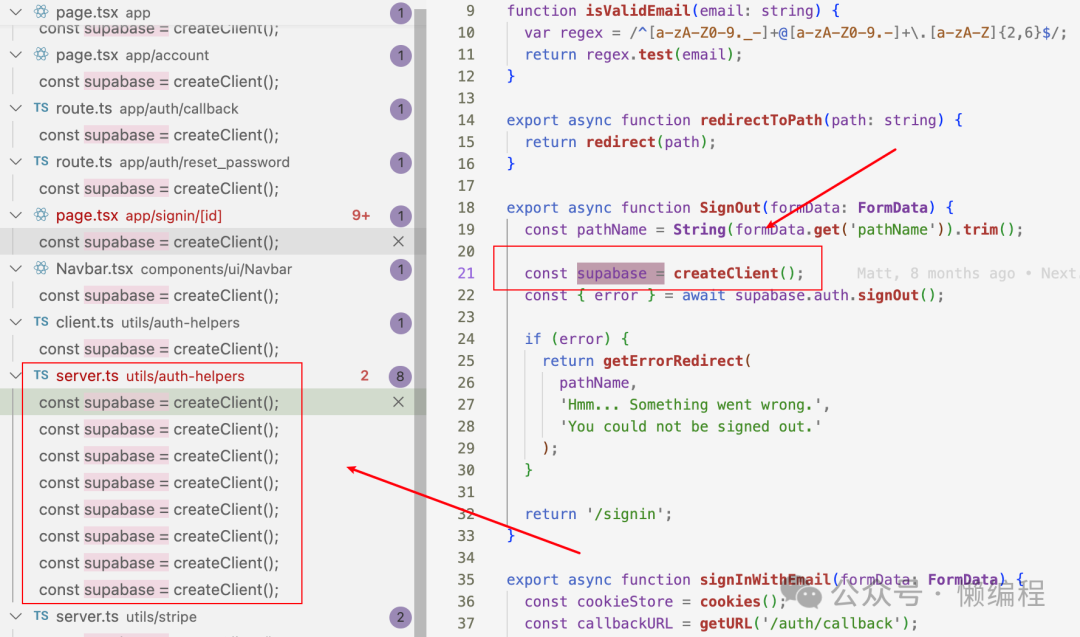
我个人习惯上,一般会将需要多次使用的实例放在全局,比如我们将MySQL链接实例弄一个连接池对象放在全局,供项目中其余部分使用,所以看见这种每次都实例化supabase的写法,有点虚。
喔~老伙计,不虚不虚,直接看看源码就好了,我们基于源码判断一下实例化supabase时,是不是构建了长连接,还是其他的实现方式。
我们直接将https://github.com/vercel/nextjs-subscription-payments代码拉到本地,然后初始化环境,可以发现createClient中,最终会使用supabase/ssr库来实例化,ssr库是supabase新推出的(https://supabase.com/docs/guides/auth/server-side),supabaes官方要弃用auth helpers包,然后推荐大家使用ssr。
我们看到ssr库中的实例化supabase的function:
declare function createServerClient<Database = any, SchemaName extends string & keyof Database = 'public' extends keyof Database ? 'public' : string & keyof Database, Schema extends GenericSchema = Database[SchemaName] extends GenericSchema ? Database[SchemaName] : any>(supabaseUrl: string, supabaseKey: string, options: SupabaseClientOptions<SchemaName> & {
cookies: CookieMethods;
cookieOptions?: CookieOptionsWithName;
}): _supabase_supabase_js.SupabaseClient<Database, SchemaName, Schema>;可以发现就是实例化了SupabaseClient类,其中与查询数据库相关的主要逻辑为:
创建了带认证的fetch方法,fetchWithAuth方法的逻辑就是判断headers中有没有apikey和Authorization,如果没有则自动设置上,这样就不需要再每次使用fetch时都手动设置。
this.fetch = fetchWithAuth(supabaseKey, this._getAccessToken.bind(this), settings.global.fetch)有了fetch后,则实例化出PostgrestClient对象,基于该对象来查询数据库中的数据。
this.rest = new PostgrestClient(`${_supabaseUrl}/rest/v1`, {
headers: this.headers,
schema: settings.db.schema,
fetch: this.fetch,
})进一步查看PostgrestClient时,会发现很多熟悉的方法,比如form方法:
from<
TableName extends string & keyof Schema['Tables'],
Table extends Schema['Tables'][TableName]
>(relation: TableName): PostgrestQueryBuilder<Schema, Table, TableName>
from<ViewName extends string & keyof Schema['Views'], View extends Schema['Views'][ViewName]>(
relation: ViewName
): PostgrestQueryBuilder<Schema, View, ViewName>
/**
* Perform a query on a table or a view.
*
* @param relation - The table or view name to query
*/
from(relation: string): PostgrestQueryBuilder<Schema, any, any> {
const url = new URL(`${this.url}/${relation}`)
return new PostgrestQueryBuilder(url, {
headers: { ...this.headers },
schema: this.schemaName,
fetch: this.fetch,
})
}上面的form方法利用TS重载特性定义了3个,分别用于处理Table、处理View和兜底都处理的,此外这种return PostgrestQueryBuilder实例的写法,可以实现复杂点的链式查询,比如这种形式:
const query = client
.from('users')
.select('name, email')
.eq('id', 1)到这里,我们还是没了解核心问题,具体是怎么与数据库操作的,我们需要进一步看PostgrestQueryBuilder类的代码,在这里会你发现select方法:
select<
Query extends string = '*',
ResultOne = GetResult<Schema, Relation['Row'], RelationName, Relationships, Query>
>(
columns?: Query,
{
head = false,
count,
}: {
head?: boolean
count?: 'exact' | 'planned' | 'estimated'
} = {}
): PostgrestFilterBuilder<Schema, Relation['Row'], ResultOne[], RelationName, Relationships> {
const method = head ? 'HEAD' : 'GET'
// 其他逻辑...
return new PostgrestFilterBuilder({
method,
url: this.url,
headers: this.headers,
schema: this.schema,
fetch: this.fetch,
allowEmpty: false,
} as unknown as PostgrestBuilder<ResultOne[]>)
}select方法会return PostgrestFilterBuilder实例,实例化PostgrestFilterBuilder时传入了:
url:存储PostgREST服务的URL
headers:请求postgRest的请求头
schema:数据库名称(默认就是public数据库)
fetch:带认证的fetch对象
阅读PostgrestFilterBuilder类的代码会发现他是PostgrestBuilder的子类,所以在实例化PostgrestFilterBuilder时,会调用PostgrestBuilder的构造函数。
我们知道在nextjs中使用supabase时,都是使用异步的形式的方式调用的,比如:
const result = await supabase.from('table1').select('*').eq('name', '二两')我们理一下逻辑,当你想上面这样使用supabase时,链式调用最终会发现一个 PostgrestFilterBuilder 实例,它继承自 PostgrestBuilder,而PostgrestBuilder 类实现了 PromiseLike 接口。
关于 PromiseLike
1. Promise 的概念:
首先,Promise 是 JavaScript 中处理异步操作的一种方式。它代表一个尚未完成,但预期在未来某个时间点会完成的操作。
2.PromiseLike 的定义:
"PromiseLike" 是一个更宽松的概念。它指的是任何具有 then 方法的对象。这个 then 方法的行为应该类似于 Promise 的 then 方法。
为什么需要PromiseLike?
它提供了更大的灵活性。
允许自定义对象以类似 Promise 的方式工作,而不必完全实现 Promise 的所有功能。
使得现有的类或对象可以轻松地与期望 Promise 的代码协同工作。
所以我们在使用await时,逻辑会走到PostgrestBuilder类的then方法中,而then方法中使用了带认证的fetch向postgRest发起了数据查询请求,then方法中的相关逻辑如下:
const _fetch = this.fetch
let res = _fetch(this.url.toString(), {
method: this.method,
headers: this.headers,
body: JSON.stringify(this.body),
signal: this.signal,
}).then(async (res) => {
let error = null
let data = null
let count: number | null = null
let status = res.status
let statusText = res.statusText
if (res.ok) {
if (this.method !== 'HEAD') {
const body = await res.text()
// ...剩余代码请在ssr库中查看。至此,我们可以回答多supabase实例的问题了:
创建多个supabase实例时,是不会与PostgreSQL数据库建立长连接的。SupabaseClient其实就是一个轻量的HTTP客户端封装,调用SupabaseClient的from、rpc方法时,其实都是用fetch创建一个新的HTTP请求,这个请求是无状态的,不会保持持久的链接,然后所有的HTTP请求是与PostgREST服务交互,而PostgREST服务才真正的与PostgreSQL链接。
所以,项目中多处创建supabase是没有任何问题的,不需要使用useContext这些将supabase object维护在全局。
unsetunsetsupabase查询的并发量级unsetunset
我们知道了,使用supabase/ssr库实现查询时,其实就是向PostgREST发送了一个HTTP请求,我们看supabase的架构图,所有的请求会先经过Kong。
Kong在2007年推出,现在是知名的API网关服务,提供开源版和企业版,可以使用docker部署。Kong基于OpenResty开发,而OpenResty基于Nginx,三者关系如下:
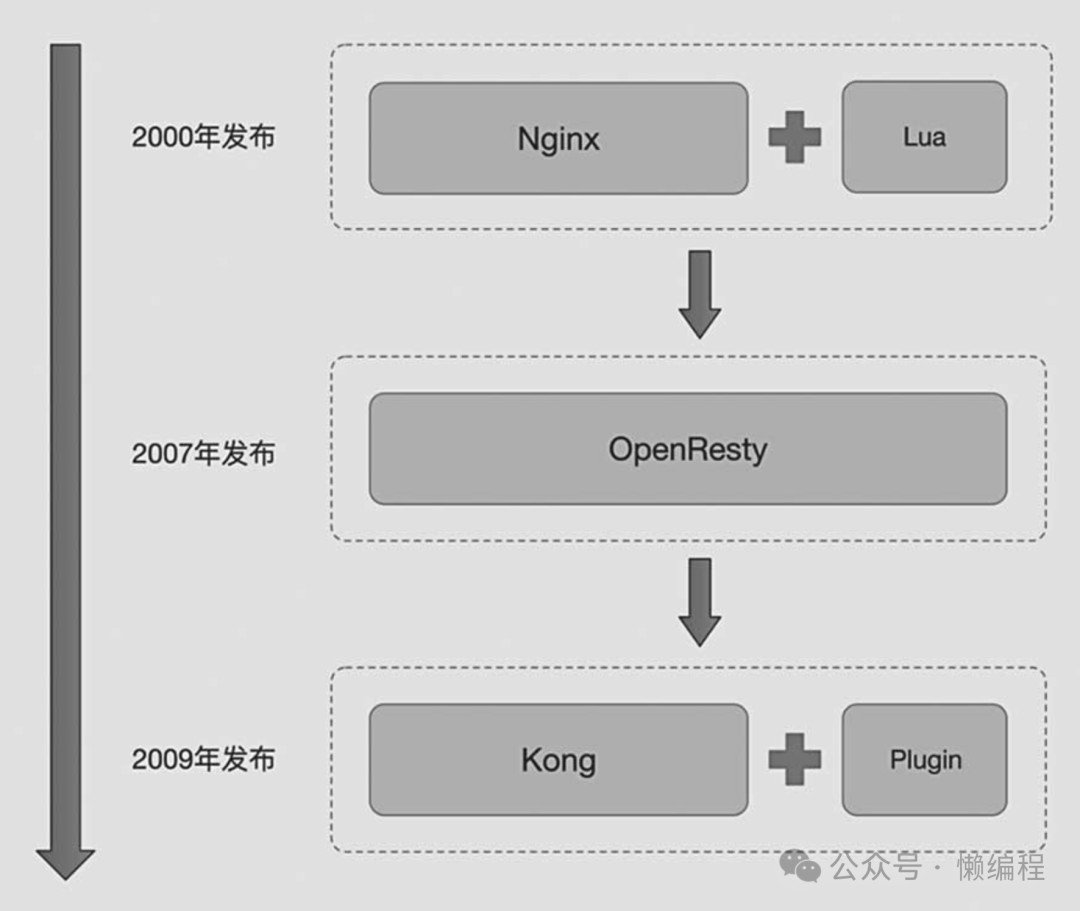 也就是说,Kong的高性能其实基于Nginx,所以并发能力和稳定性不需要太过操心,接着的一个问题是,相比于Nginx,Kong主要解决了什么问题?
简单捋捋。
也就是说,Kong的高性能其实基于Nginx,所以并发能力和稳定性不需要太过操心,接着的一个问题是,相比于Nginx,Kong主要解决了什么问题?
简单捋捋。
随着业务复杂,我们为了提高服务稳定性,一般会开始使用微服务架构,将应用程序划分为多个低耦合的服务,每个服务负责特定的功能,然后就可以交给不同的团队维护开发。微服务虽然好处多,但也有一个直观的问题,就是抽成了不同服务,就出现了各种接口,接口繁杂就导致客户端难以快速安全的访问到所需要的信息。
为了解决这个问题,就提出了API网关的概念。API网关作为这些微服务的中央入口,客户端统一发请求到API网关层,然后再由网关进行路由转发,从而降低客户端访问接口的复杂度。
Kong其实就解决这个问题,所有的流量都走Kong,那么Kong就可以做路由转发,将客户端不同的需求转发给不同的服务,此外什么负载均衡、访问控制、缓存、服务代理这些Kong都能做。
为了查看supabase使用Kong的具体细节,我们可以self-host一下supabase,我们才有docker的形式self-host,具体看文档:https://supabase.com/docs/guides/self-hosting/docker
正常启动后,你将会有下面这些docker服务,其实就是微服务模块。
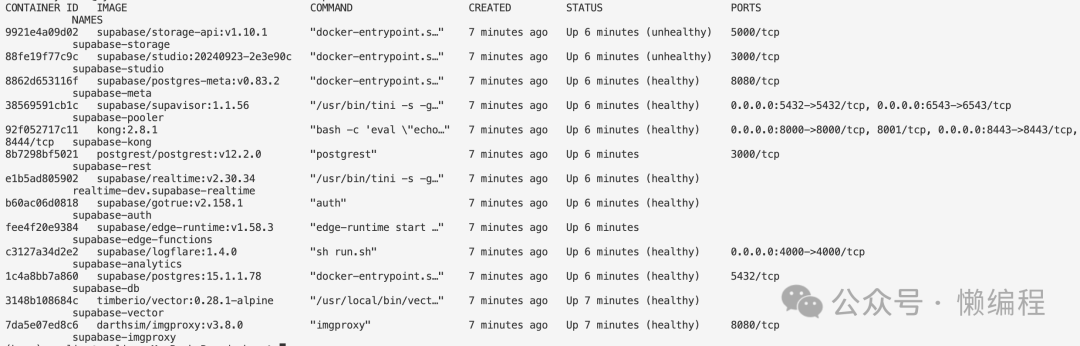
我发现了supavisor服务(号称可以将Postgres扩展到100w个连接:https://supabase.com/blog/supavisor-1-million),这个服务在旧的supabase self-host中是没有的,supabase更新速度真的非常快,快到我害怕,如果对supabase把握不深入,出问题就很难定位与解决。
回到Kong的视角,我们打开查看docker-compose.yml,看到Kong容器构建的片段,我在关键的部分都添加了注释
kong:
container_name: supabase-kong
image: kong:2.8.1
# 设置容器退出时自动重启
restart: unless-stopped
# Kong容器启动时会执行的命令(重要)
entrypoint: bash -c 'eval "echo \"$$(cat ~/temp.yml)\"" > ~/kong.yml && /docker-entrypoint.sh kong docker-start'
ports:
- ${KONG_HTTP_PORT}:8000/tcp
- ${KONG_HTTPS_PORT}:8443/tcp
depends_on:
analytics:
condition: service_healthy
environment:
# 关闭数据库模式,即配置不从数据库读,不做动态配置(速度会快一点,毕竟没有数据库了)
KONG_DATABASE: "off"
# 使用的配置文件
KONG_DECLARATIVE_CONFIG: /home/kong/kong.yml
# https://github.com/supabase/cli/issues/14
# DNS解析顺序
KONG_DNS_ORDER: LAST,A,CNAME
# Kong会使用的插件
KONG_PLUGINS: request-transformer,cors,key-auth,acl,basic-auth
# 设置Nginx代理缓冲区大小(用来处理大请求的,跟并发量关系不大)
KONG_NGINX_PROXY_PROXY_BUFFER_SIZE: 160k
KONG_NGINX_PROXY_PROXY_BUFFERS: 64 160k
SUPABASE_ANON_KEY: ${ANON_KEY}
SUPABASE_SERVICE_KEY: ${SERVICE_ROLE_KEY}
DASHBOARD_USERNAME: ${DASHBOARD_USERNAME}
DASHBOARD_PASSWORD: ${DASHBOARD_PASSWORD}
volumes:
# https://github.com/supabase/supabase/issues/12661
- ./volumes/api/kong.yml:/home/kong/temp.yml:ro从Kong的docker-compose.yml中可以看出,会使用./volumes/api/kong.yml作为配置文件,我们可以进入Kong启动的容器确认配置,以及看一下kong:2.8.1使用nginx时,nginx的配置是怎么样的。
docker exec -u root -it <容器名称或ID> /bin/bash进入后,使用nginx -t,可以查到nginx的配置,然后/home/kong目录下,可以看见kong.yml。
未来如果我们感觉Kong性能不足了,可以尝试调整nginx默认配置。
现在我们来看kong.yml,在yml文件一开始,就订阅了consumers(Kong消费者,其实就是用户):
consumers:
- username: DASHBOARD
- username: anon
keyauth_credentials:
- key: $SUPABASE_ANON_KEY
- username: service_role
keyauth_credentials:
- key: $SUPABASE_SERVICE_KEY其中anon用户有一个API密钥,密钥的值在环境变量SUPABASE_ANON_KEY中,service_role用户也类似。
接着对这些用户定义了Access Control List(访问控制列表)
acls:
- consumer: anon
group: anon
- consumer: service_role
group: adminanon用户被分配到anon组。
service_role用户被分配到admin组。
这些组可以用于控制对特定API或路由的访问。
然后我们看到rest-v1部分:
## Secure REST routes
- name: rest-v1
_comment: 'PostgREST: /rest/v1/* -> http://rest:3000/*'
url: http://rest:3000/
routes:
- name: rest-v1-all
# 为true意味着在转发请求时会去掉匹配的路径前缀)
strip_path: true
paths:
- /rest/v1/
# 插件配置
plugins:
# 使用cors插件,允许跨域
- name: cors
# 要请求成功需要做密钥认证
- name: key-auth
config:
# 代理到上游服务时隐藏凭证
hide_credentials: true
- name: acl
config:
# 隐藏组信息头
hide_groups_header: true
# 只允许admin和anon两个组的用户才能访问
allow:
- admin
- anon当用户请求/rest/v1路由时,Kong会将请求转发到PostgREST服务中,我们看回docker-compose.yml中的rest:
rest:
container_name: supabase-rest
image: postgrest/postgrest:v12.2.0
depends_on:
db:
# Disable this if you are using an external Postgres database
condition: service_healthy
analytics:
condition: service_healthy
restart: unless-stopped
environment:
PGRST_DB_URI: postgres://authenticator:${POSTGRES_PASSWORD}@${POSTGRES_HOST}:${POSTGRES_PORT}/${POSTGRES_DB}
PGRST_DB_SCHEMAS: ${PGRST_DB_SCHEMAS}
PGRST_DB_ANON_ROLE: anon
PGRST_JWT_SECRET: ${JWT_SECRET}
PGRST_DB_USE_LEGACY_GUCS: "false"
PGRST_APP_SETTINGS_JWT_SECRET: ${JWT_SECRET}
PGRST_APP_SETTINGS_JWT_EXP: ${JWT_EXPIRY}
command: "postgrest"会发现,启动的PostgREST其实就是用PostgREST官方的镜像启动容器,然后设置上环境变量:
PGRST_DB_URI:Postgres数据库的URI
PGRST_DB_SCHEMAS:允许访问的数据库名称
PGRST_DB_ANON_ROLE:设置匿名用户的数据库角色为anon
PGRST_JWT_SECRET和PGRST_APP_SETTINGS_JWT_SECRET都是为了设置JWT密钥(设置2次可能是未来兼容)
PGRST_APP_SETTINGS_JWT_EXP:设置JWT令牌过期时间
PGRST_DB_USE_LEGACY_GUCS:设置为false表示不使用旧版的全局用户配置
至此,我们知道了self-host的supabase其中的kong和PostgREST都是直接使用官方镜像构建的,supabase官方没有二次魔改开发,所以查询数据时,性能如果有瓶颈也不需要搜索supabase相关的,而是需要去了解Kong和PostgREST。
多次阅读Supabase Database相关文档会了解到,supabase提供了多种链接数据库的方式(https://supabase.com/docs/guides/database/connecting-to-postgres#how-connection-pooling-works),而我们使用supabase-js或supabase-py时,其实使用的是REST API形式(从一开始的源码分析就知道了)。
我们可以阅读Supabase REST API相关的文档:https://supabase.com/docs/guides/api,可以发现如下描述。

上面有2个性能相关的信息:
在Supabase的基准测试下,PostgREST的查询速度比Firebase快300%
REST API可以同时支持上千个的并发查询
至此第二个问题也有了答案。
PostgREST使用了Hasql作为数据库的连接池,通过连接池来解决并发查询数据库的问题,如果没有连接池,直连Postgres,那么就很容易出现性能问题,从Postgres核心开发之一Bruce Momjian的博客中可以了解到这一点(https://momjian.us/main/blogs/pgblog/2020.html#April_22_2020)。
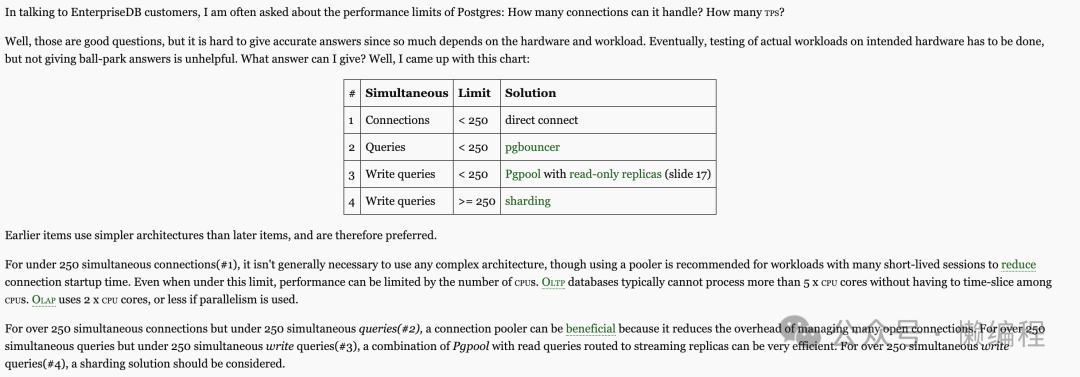
也就是直连,Limit是250个,非常少。
unsetunset结尾unsetunset
下个周末,我有时间,再研究一下supabase的auth。
我是二两,下篇文章见。


















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











