






paper: 《IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models》
看了有一阵子发现有些忘记了,还是记在这里。
了解IRGAN首先要了解GAN:Generative Adverserial Net。原来的模型一般分为生成模型和判别模型。
生成模型:学习联合概率密度分布P(X,Y),生成模型可以学习X,Y的联合分布,也可以通过贝叶斯公式推导出P(Y|X)。
生成模型求解思路:联合分布->求解类别先验概率和类别条件概率
常见的生成模型像朴素贝叶斯,HMM,LDA
判别模型:直接学习决策函数或者条件概率分布P(Y|X)的模型称之为判别模型,判别模型不关心整体的分布只关心各组X之间Y的差异。
判别模型求解思路:条件分布->模型参数后验概率最大->(似然函数参数先验)最大->最大似然
常见的判别模型像决策树,SVM,CRF
参考博客:https://blog.csdn.net/zouxy09/article/details/8195017
GAN巧妙的同时使用了这两种模型,生成模型用来刻画数据的分布,判别模型用来判别一个sample是生成模型生成的还是来自原数据。生成模型的目标函数是最大话判别模型犯错的概率,而判别模型的目标函数是最大化判别模型的正确率。就像一场警察和小偷的游戏。最终判别模型的结果会无限接近于1/2.
G(z; θ):假设z是噪声变量,生成模型需要一个先验概率P(z). G是由θ参数的可微函数。训练目标是最小化log(1-D(G(z)))
D(x; θ): x是真实数据,D代表x是真实数据的概率。我们训练D来最大化正确label的概率
总的公式是:
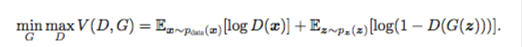
当然每次G迭代后D都迭代性能开销不行。所以k步优化D然后再一步优化G。当然假如G变化比较慢的话每一次D都能达到较优解。
论文上有一个小例子解释训练的过程:
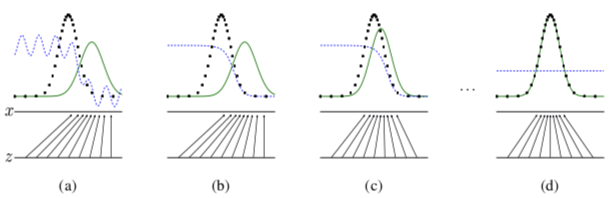
其中绿色实线是生成模型生成数据分布,蓝色虚线是判别的决策面,黑色虚线是真实数据的分布。最下面的横线是z抽样的domain,中间的横线是部分真实数据的domain。黑色向上的箭头表示z的抽样到真实数据的投射,而生成模型会根据这个这个投射学习到x的分布。图(a)中考虑到生成分布的影响,D的决策面部分是不准的。图(b)判别模型学习到了两者分布之间的diff(收敛到了D*(x)=pdata(x)/(pdata(x)+pg(x)))图(c)更新过G后,继续做判别。图(d) 最终G的分布和真实分布重合,然后判别的最后结果是1/2.
论文后有对收敛结果的论证。这边就不赘述了。
GAN的结果是作用在图片上的。IRGAN借用了GAN的思想。
生成模型:负责从候选池中选择相关的文档














 1961
1961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









