






贝叶斯在1763年,《机会学说中一个问题的解》中提出了贝叶斯定理。
生活中不乏分类,比如我们经常通过一些人的衣着,来下意识的区别某些人是杀马特亦或是文艺青年。我们是如何做出这些判断或者说是分类的呢?这些判断大多来自我们的“经验之谈”,即,我们首先脑海中会先存有“某类人通常会如何着装打扮”的概念,然后当遇到这类显著特征之后,便会下意识的对其进行分类。
那么如何让机器进行这种类似的判断区分呢?
朴素贝叶斯分类法是一种相对简单易理解的机器分类方法。它的思想是首先对一些已知分类的样本进行采样(机器学习),比如已知某个人是非洲人,他的特征是肤色黑,于是我们相对的会提高非洲人肤色黑的概率(即P[肤色黑|是非洲人]),当然为了提高分类的成功度,同时还要收集其他特征。那么当学习结束,进行应用的时候,倘若对一个黑色皮肤的人进行分类,虽然我们不能确定他一定是某类人,但仅由当前已知特性进行判断,是非洲人的概率相对高,于是我们将其归类为非洲人。
从数学计算上:
1.我们假设将某种待区分事物x = {a1, a2, a3, ...., am},其中xi代表A的第i种特征属性(类似上述的"肤色")。
2.类别集合B = {y1, y2, y3, ....},其中yi代表第i类(类似上述"非洲人")。
3.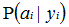
4.由贝叶斯公式:
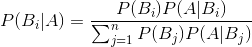
其中分母我们设为P(x)

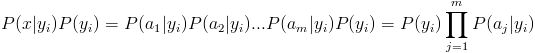
至此,我们通过了“以往经验”得到了具体推算某事物x属于yi类的概率P(yi|x)的方法。
显然对于所有的P(yi|x),值最大的,即为x最有可能属于的那一类。
总结一下,朴素贝叶斯进行分类总共分为三步:确定特征属性,通过样本数据进行计算,以及应用判断。
接下来举个简单的例子,顺带附上一份粗糙而又简陋的代码。
对于目前的博客网站,很多人可能同时拥有不止一个博客,然而网站管理员需要知道当前有多少账号是用户主用的账号或者是活跃用户,哪些是偶尔使用或者废弃的账号。
首先我们需要确定区分【用户主用账号】和【用户辅助账号】这两者的特征属性,并加以分类:
1.发表博文数量/ID注册天数(三类<0.1, 0.1~0.2, >0.2)
2.互加好友数量/ID注册天数(三类<0.1, 0.1~0.8, >0.8)
3.是否上传真实头像(两类0否, 1是)
对于某个账户,可以很容易地从后台得到如上我们需要的数据。
以下是代码,学习部分暂时用Virtual_Learned()函数代表虚拟结果。
#include <vector>
#define MAX_Class 2
#define MAX_Character 3
// 类别:用户主用账号, 用户辅助账号(0, 1)
// 特征属性:1.发表博文数量/ID注册天数(<0.1, 0.1~0.2, >0.2)
// 2.互加好友数量/ID注册天数(<0.1, 0.1~0.8, >0.8)
// 3.是否上传真实头像(0.0否, 1.0是)
double P_C[MAX_Class];
// P_C[i] : i类别占训练样本总体的概率
std::vector< double> P[MAX_Class][MAX_Character];
// P[i][j][k] : i类别条件下, j特征, k情况的概率
double lap = ( double)MAX_Character;
struct Check {
int p_kind[ 3] = { 0};
Check( double a, double b, int c) {
if(a < 0.1) p_kind[ 0] = 0;
else if(a < 0.2) p_kind[ 0] = 1;
else p_kind[ 0] = 2;
if(b < 0.1) p_kind[ 1] = 0;
else if(b < 0.8) p_kind[ 1] = 1;
else p_kind[ 1] = 2;
if(c == 0) p_kind[ 2] = 0;
else p_kind[ 2] = 1;
}
} ;
void Virtual_Learned() {
P_C[ 0] = 0.89, P_C[ 1] = 0.11;
P[ 0][ 0].push_back( 0.3), P[ 0][ 0].push_back( 0.5), P[ 0][ 0].push_back( 0.2);
P[ 1][ 0].push_back( 0.75), P[ 1][ 0].push_back( 0.15), P[ 1][ 0].push_back( 0.1);
P[ 0][ 1].push_back( 0.1), P[ 0][ 1].push_back( 0.7), P[ 0][ 1].push_back( 0.2);
P[ 1][ 1].push_back( 0.7), P[ 1][ 1].push_back( 0.2), P[ 1][ 1].push_back( 0.1);
P[ 0][ 2].push_back( 0.2), P[ 0][ 2].push_back( 0.8);
P[ 1][ 2].push_back( 0.9), P[ 1][ 2].push_back( 0.1);
}
int main() {
Virtual_Learned();
double a, b;
int c;
// 分别输入:发表博文数量/ID注册天数
// 互加好友数量/ID注册天数
// 是否上传真实头像(0否, 1是)
while(std::cin >> a >> b >> c) {
Check test = Check(a, b, c);
double test_ans[MAX_Class] = { 0.0};
for( int i = 0; i < MAX_Class; i++) {
test_ans[i] = P_C[i];
for( int j = 0; j < MAX_Character; j++) {
test_ans[i] *= P[i][j][test.p_kind[j]];
}
// test_ans[i] /= lap;
}
std::cout << " 该账号为主用账号的相对系数: " ;
std::cout << test_ans[ 0] << std::endl;
std::cout << " 该账号为辅助账号的相对系数: " ;
std::cout << test_ans[ 1] << std::endl;
if(test_ans[ 0] >= test_ans[ 1])
std::cout << " 故该账号为用户主用账号 " << std::endl;
else std::cout << " 故该账号为用户辅助账号 " << std::endl;
}
return 0;
}
假设,当前有一个账号,该账号并没有上传真实头像,但是其第1属性值为0.1,第二属性值为0.4
通过计算,我们将得到:

由此,我们也可大致地发现,当特征属性比较多的时候,朴素贝叶斯可以具有相对较强的抗干扰能力。
————————————————————————————————————————————————
【PS:以上的例子中,由于特征属性之间均互相独立,我们以样本数据中某的出现频率当作概率,然而当特征属性是连续值得时候。通常是假设该值服从高斯分布,需要求出样本中该值的均值和标准差,然后以如下公式带入求得P值。】
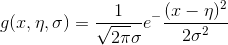
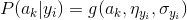















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









