






1、优化卷积核技术
在实际的卷积训练中,为了加快速度,常常把卷积核裁开。比如一个3x3的卷积核,可以裁成一个3x1和1x3的卷积核(通过矩阵乘法得知),分别对原有输入做卷积运算,这样可以大大提升运算的速度。
原理:在浮点运算中乘法消耗的资源比较多,我们目的就是尽量减少乘法运算。
- 比如对一个5x2的原始图片进行一次3x3的SAME卷积,相当于生成的5x2的像素中,每一个像素都需要经历3x3次乘法,那么一共是90次。
- 同样是这样图片,如果先进行一次3X1的SAME卷积,相当于生成的5x2的像素中,每一个像素都需要经历3x1次乘法,那么一共是30次。再进行一次1x3的SAME卷积也是计算30次,在一起总共60次。
#1.卷积层 ->池化层 W_conv1 = weight_variable([5,5,3,64]) b_conv1 = bias_variable([64]) h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1) #输出为[-1,24,24,64] print_op_shape(h_conv1) h_pool1 = max_pool_2x2(h_conv1) #输出为[-1,12,12,64] print_op_shape(h_pool1) #2.卷积层 ->池化层 卷积核做优化 W_conv21 = weight_variable([5,1,64,64]) b_conv21 = bias_variable([64]) h_conv21 = tf.nn.relu(conv2d(h_pool1,W_conv21) + b_conv21) #输出为[-1,12,12,64] print_op_shape(h_conv21) W_conv2 = weight_variable([1,5,64,64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_conv21,W_conv2) + b_conv2) #输出为[-1,12,12,64] print_op_shape(h_conv2) h_pool2 = max_pool_2x2(h_conv2) #输出为[-1,6,6,64] print_op_shape(h_pool2)
将原来的第二层5x5的卷积操作换成两个5x1和1x5的卷积操作,代码运行后准确率没有变化,但是速度快了一些。
2、多通道卷积技术:可以理解为一种新型的CNN网络模型,在原有的卷积模型基础上的扩展。
- 在原有的卷积层中使用单个尺寸的卷积核对输入数据进行卷积操作,生成若干个feature map。
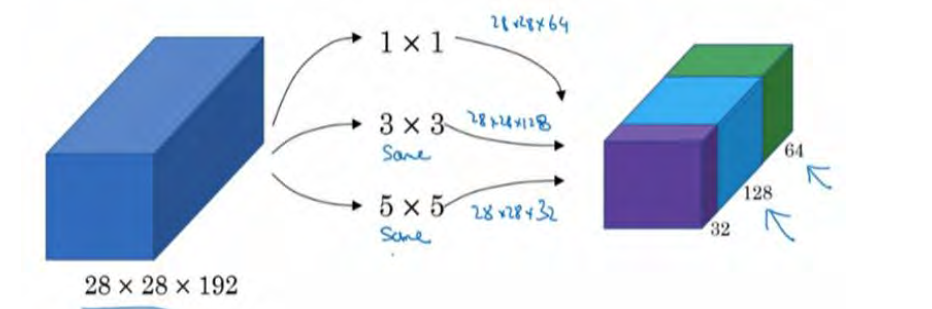
- 多通道卷积的 变化就是在单个卷积层中 加入若干个不同尺寸的过滤器,这样会使生成的feature map特征更加多样性。
#2.卷积层 ->池化层 这里使用多通道卷积 W_conv2_1x1 = weight_variable([1,1,64,64]) b_conv2_1x1 = bias_variable([64]) W_conv2_3x3 = weight_variable([3,3,64,64]) b_conv2_3x3 = bias_variable([64]) W_conv2_5x5 = weight_variable([5,5,64,64]) b_conv2_5x5 = bias_variable([64]) W_conv2_7x7 = weight_variable([7,7,64,64]) b_conv2_7x7 = bias_variable([64]) h_conv2_1x1 = tf.nn.relu(conv2d(h_pool1,W_conv2_1x1) + b_conv2_1x1) #输出为[-1,12,12,64] h_conv2_3x3 = tf.nn.relu(conv2d(h_pool1,W_conv2_3x3) + b_conv2_3x3) #输出为[-1,12,12,64] h_conv2_5x5 = tf.nn.relu(conv2d(h_pool1,W_conv2_5x5) + b_conv2_5x5) #输出为[-1,12,12,64] h_conv2_7x7 = tf.nn.relu(conv2d(h_pool1,W_conv2_7x7) + b_conv2_7x7) #输出为[-1,12,12,64] #合并 3表示沿着通道合并 h_conv2 = tf.concat((h_conv2_1x1,h_conv2_3x3,h_conv2_5x5,h_conv2_7x7),axis=3) #输出为[-1,12,12,256] h_pool2 = max_pool_2x2(h_conv2) #输出为[-1,6,6,256]
3、批量归一化
最大限度的保证每次的正向传播输出在同意分布上,这样反向计算时参照的数据样本分布就会与正向计算时的数据分布一样了。
批量归一化在tensorflow中的函数定义tf.nn.batch_normalization(x,mean,variance,offset,scale,variance_epsilon,name=None)
- x:代表输入
- mean:样本均值
- variance:方差
- offset:偏移量,
使用这个函数必有由另一个函数配合——tf.nn.moments,计算均值和方差tf.nn,moments(x,axes,name=None,keep_dims=False)
#需要引入头文件 from tensorflow.contrib.layers.python.layers import batch_norm # 为BN函数添加占位符参数 train = tf.placeholder(tf.float32) ...... def batch_norm_layer(value,train=None,name='batch_norm): if train is not None: return batch_norm(value,decay=0.9,updates_collections=None,is_training=True) else: return batch_norm(value,decay=0.9,updates_collections=None,is_training=Flase) ....... #在第一层h_conv1与第二层h_conv2的输出之前卷积之后加入BN层 h_conv1 = tf.nn.relu(batch_norm_layer((conv2(x_image,W_conv1)+b_conv1),train) h_pool1 = max_pool_2x2(h_conv1) h_conv2 = tf.nn.relu(batch_norm_layer((conv2(h_pool1,W_conv2)+b_conv2),train) h_pool2 = max_pool_2x2(h_conv2) ...... #在运行session中添加训练标志 for i in range(20000): image_batch,label_batch = sess.run([image_train,labels_train]) label_b = np.eye(10,dtype=float)[label_batch] #one hot编码 train_step.run(feed_dict={x:image_batch,y:label_b,train:1},session=sess) .......















 1000
1000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









