






背景论文:
Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks
(https://arxiv.org/abs/1312.6082)
英文车牌迁移参考:http://matthewearl.github.io/2016/05/06/cnn-anpr/
上述博文所描述过程大致为:
- 利用gen.py生成1000张训练图片,图片组成为一个生成的车牌,加上随机的背景,并且添加上高斯噪声,旋转等,并且使用0,1标注该车牌是否完全包含在图片中(位置,大小等);
- 利用生成的1000张图片进行训练,此处可能需要进行的修改是(视tensorflow版本决定是不是需要修改)即添加logits和labels(如图):
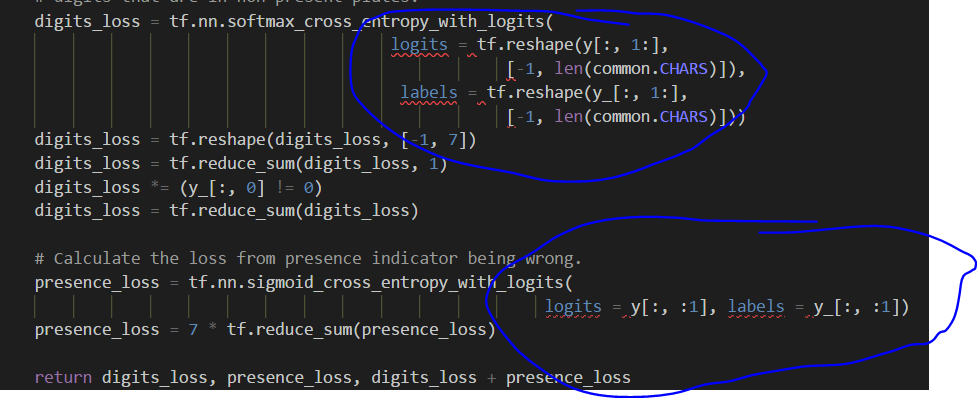
- 窗口思想,利用滑动窗口在一幅尺寸较大的图当中截取合适的部分来应对尺寸变换。
训练结束后进行评估,此代码结果跑了两张从网上的图片,似乎效果还不错:


既然效果还不错,那可以试着迁移到中文车牌上了,
修改后的代码地址:
代码修改中所遇到的最主要问题是编码问题!在Ubuntu下默认的编码是ASCII,windows下默认编码是gbk,所以在代码修改过程中,
为了输出中文,需要
- 对字符串进行utf-8编码的转换。
- 对中文的读入和输出也需要对字符串的编码方式进行转换。由于python3中不再对str支持decode和encode操作,所以将文件的读入输出由imread和imwrite修改成imencode和imdecode。
之后的训练过程和之前并没有什么差别。具体修改见项目代码。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









