







- 算法1 K-means聚类算法
- 一、简介:
- K-means算法又称K-均值算法,是一种无监督的机器学习算法。算法简单,聚类效果好,且在巨大数据集上也容易部署实施。常应用于市场划分、机器视觉、地质统计、天文、农业等等。K-means算法优化出几种算法:K-means++ ;K二代 ;Mini Batch K-means
- 一、简介:
-
- 二、算法流程:
- 1. 选定初始化的K 个质心(K值需要调参确定)
- 2. 计算所有样本到每个质心的距离
- 3. 比较样本点距离哪一个质心最近,就归为哪一个簇。
- 4. 使用当前簇内样本的均值更新质心
- 5. 终止更新的条件:
- 到达迭代次数
- MSE
- 簇中心变化率
- 二、算法流程:
-
-
- 最小化平方误差公式:x 代表样本
-
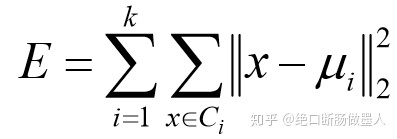
-
-
- 质心μi的公式:由于质心是取得样本加和得均值
-
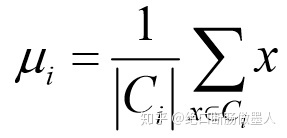
-
- 三、底层代码实现
- 1. 导入需要用的包
- 2. 定义样本集合
- 3. 定义初始化质心
- 4. 设置迭代次数
- 5. 统计迭代次数
- 6. 条件循环:
- 1)计算每个质心到每个样本点之间的欧式距离并用列表B存储
- 2)取出距离最小值的索引
- 3)使用当前簇内样本的均值更换每个质心的位置
- 4)设定终止条件:变化率为0时就终止
- 三、底层代码实现
-
- 四、K-means衍生算法:
- K-means算法缺陷:
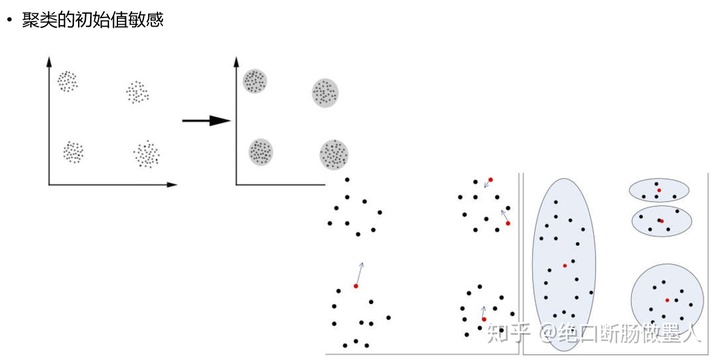
- 1. 初始的K值设定不一定合适。K值关系到分成几个类别,选定几个质心,实际操作选定比较困难。
- 2. K-means算法初始需要随机选定质心,不同的质心可能导致不同的聚类结果,很可能导致收敛过慢甚至聚类错误如图:
- K-means算法缺陷:
- 四、K-means衍生算法:
-
-
- 由于K-means算法有缺陷,为了解决缺陷,发展出了K-means++算法。
- (一) K-means++算法:改变了初始化质心的问题
- 1. 从数据集中任选一个样本点作为聚类中心
- 2. 对于数据集中的所有样本点x,计算到聚类中心的距离
- 3. 下一个质心选择相对于它前面的质心距离最远的样本点
-

-
-
-
- 4. 重复2、3步操作,直到找到K个质心点完成聚类。
- 缺陷:
- 每一次质心的设定非常依赖之前的质心设定
- 计算量大,计算速度非常慢
-
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6040
6040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









