







本文目录
0 聚类算法概述
1 K-means聚类算法
2 常见面试题
2.1 简述K-means聚类算法的执行过程
2.2 分析K-means聚类算法中的K如何取值
2.3 K-means算法有哪些优缺点?有哪些改进的模型?
0 聚类算法概述
聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇)。这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。比如在商业中,如果我们手头有大量的当前和潜在客户的信息,我们可以使用聚类将客户划分为若干组,以便进一步分析和开展营销活动,最有名的客户价值判断模型RFM,就常常和聚类分析共同使用。再比如,聚类可以用于降维和矢量量化(vector quantization),可以将高维特征压缩到一列当中,常常用于图像,声音,视频等非结构化数据,可以大幅度压缩数据量。
聚类算法和分类算法的区别:

常用聚类算法的简单介绍:
- K-means聚类:也称为K均值聚类,它试图发现k(用户指定个数)个不同的簇 ,并且每个簇的中心采用簇中所含值的均值计算而成。
- 层次聚类:层次聚类(hierarchical clustering)试图在不同层次对数据集进行划分,从而形成树形的聚类结构。
- DBSCAN:这是一种基于密度的聚类算法,簇的个数由算法自动地确定。低密度区域中的点被视为噪声而忽略,因此DBSCAN不产生完全聚类。
1 K-means 聚类算法
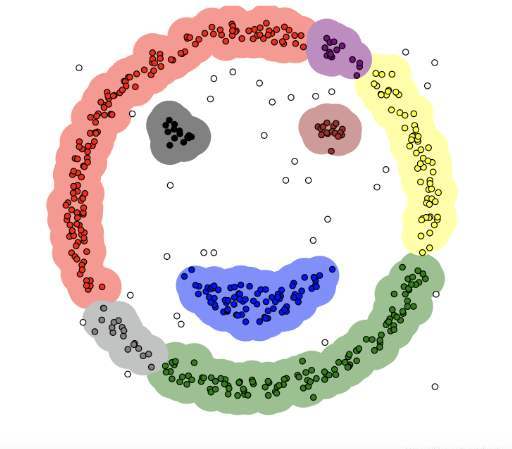
KMeans算法将一组N个样本的特征矩阵X划分为K个无交集的簇,直观上来看是簇是一组一组聚集在一起的数据,在一个簇中的数据就认为是同一类。簇就是聚类的结果表现。
簇中所有数据的均值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2017
2017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









