






一、概念:SVM思想和线性回归很相似,两个都是寻找一条最佳直线。
不同点:最佳直线的定义方法不一样,线性回归要求的是直线到各个点的距离最近,SVM要求的是直线离两边的点距离尽量大。
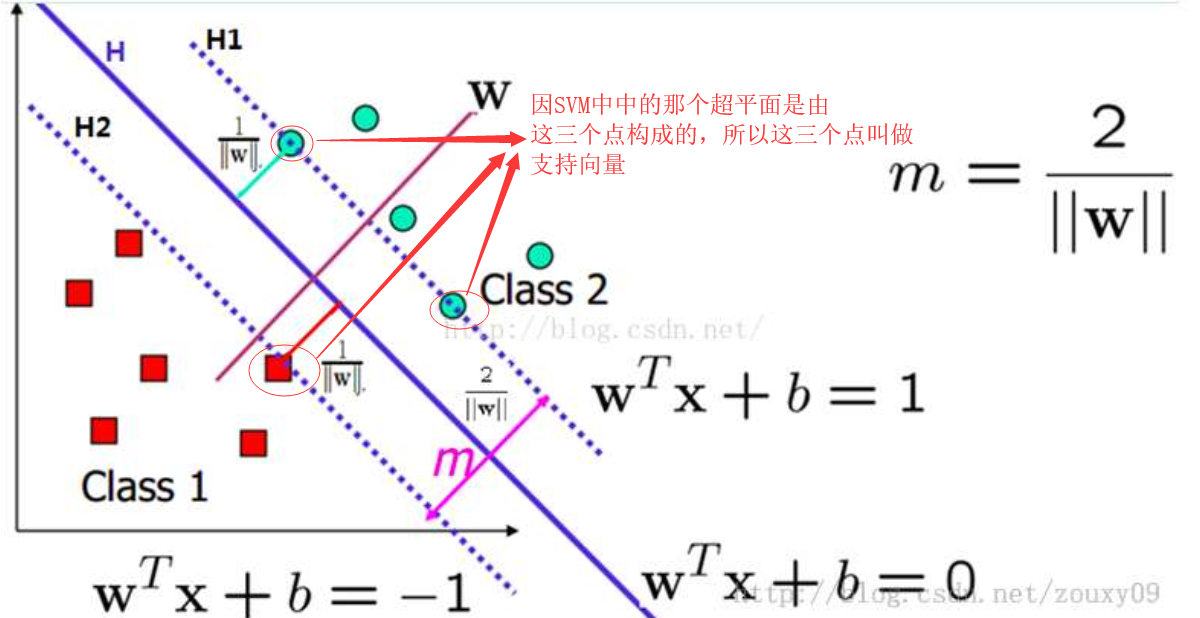
SVM本质,
距离测度,即把点的坐标转换成点到几个固定点的距离 ,从而实现升维。

如下所示

因为SVM要映射到高维空间,再来求分离超平面,但是这样的话,运算量会非常庞大,又因为上面的核函数和和映射到高维空间的解类似,所以求SVM分离超平面时,可以用求核函数方法代替在高维空间中计算,从而实现在一维平面上计算达到高维空间计算的效果















 2715
2715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









