






最近多模态大模型是真热闹啊。公司里神经病也天天说这个
Transformer一作携团队也带来了新作,一个规模为80亿参数的多模态大模型Fuyu-8B。
而且发布即开源,模型权重在Hugging Face上可以看到。100毫秒极速响应
该模型具备强大的图像理解能力。
照片、图表、PDF、界面UI都不在话下。
能从这么一张复杂的食物网里理清楚各个生物之间的关系。
提问:道格拉斯冷杉针叶缺失了,哪种生物会灭绝?
回答:红树田鼠。

也能从密密麻麻的连线图里找到,权游“小指头”扮演者Aidan Gillen出演过HBO两个系列的剧。

看得懂专业图表,可以帮你找到想要的数据。
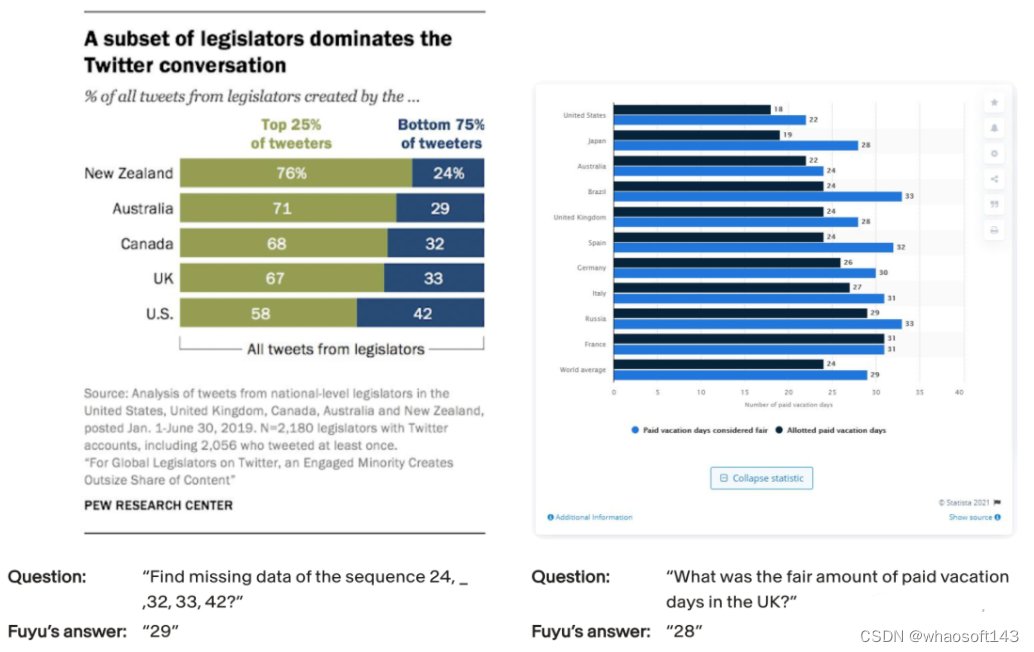
提问:(左图)24、32、33、42这组数字序列中丢了哪个数?
回答:29
一张包含多个图表的PDF也难不倒它。提问:加州哪里的工作前景不错?
Fuyu-8B可以准确找到对应的信息块,并给出正确答案“洛杉矶”。

而且Fuyu-8B的处理速度很快,研究团队表示100毫秒内可反馈大图像处理结果。
同时它还很“轻巧”,不仅模型规模没超百亿,还没有使用图像编码器。
这让它能更快速进行训练和推理,并支持处理任意大小图像。
Hugging Face联创兼CTO看了都有点激动,表示假如自己还没有创业,那么这个项目会启发他做点什么。
该成果来自Transformer一作Ashish Vaswani所在创业公司Adept。
目前该模型已开源,demo可线上试玩。
一个只有解码器的Transformer
现在在Hugging Face上即可体验Fuyu-8B的能力。
Demo中提供了两种任务。
- 看图问答
- 图像概述
可以上传一张图片然后对大模型进行提问。
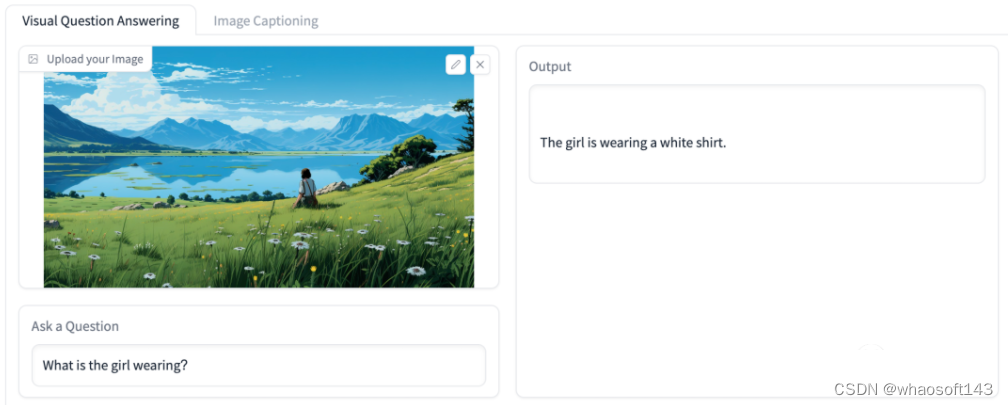
或者是直接让它看图然后描述图片内容。
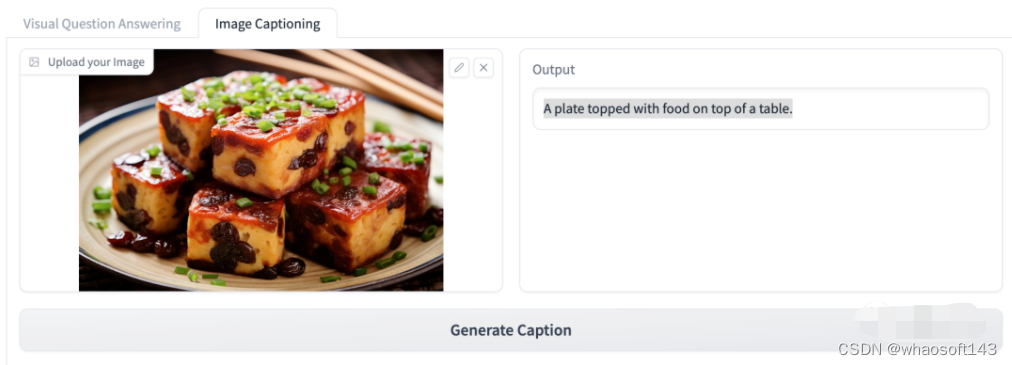
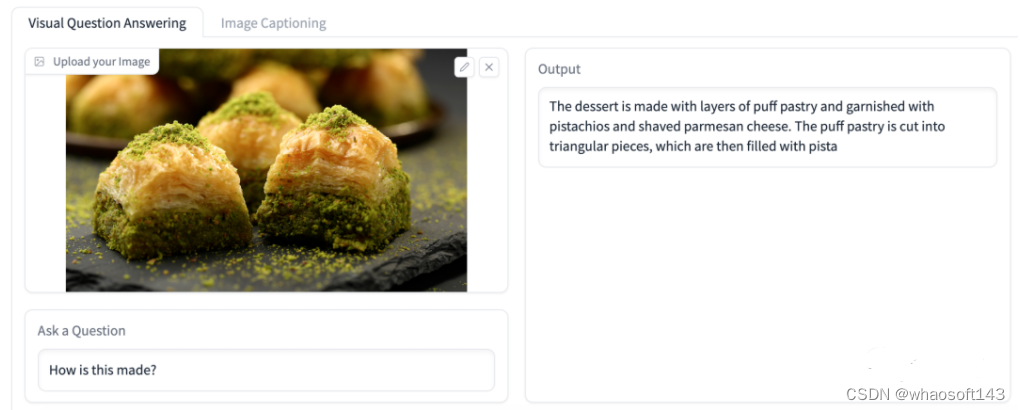
大模型的常识水平不错,比如问它一道甜点是怎么做的?
它给出的回答是:
这道甜点是用一层层的酥皮做成的,上面点缀着开心果和帕玛森奶酪。
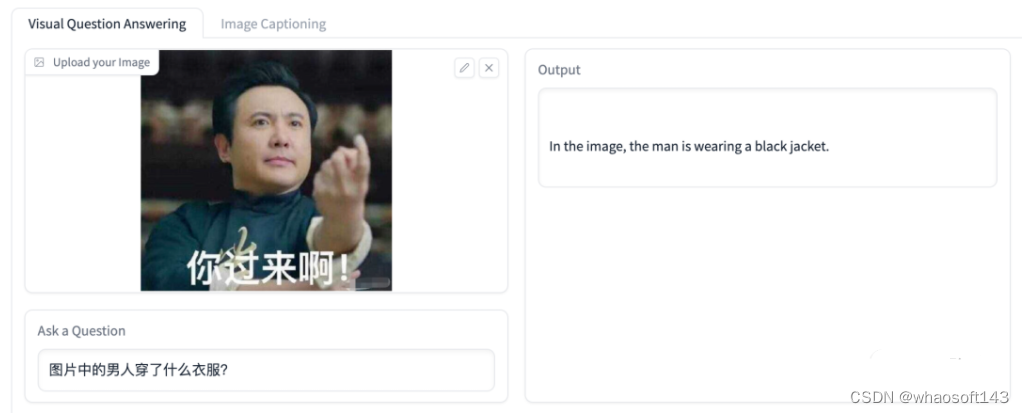
测试了下中文能力,发现它能理解中文,但是“习惯性”用英文回答。
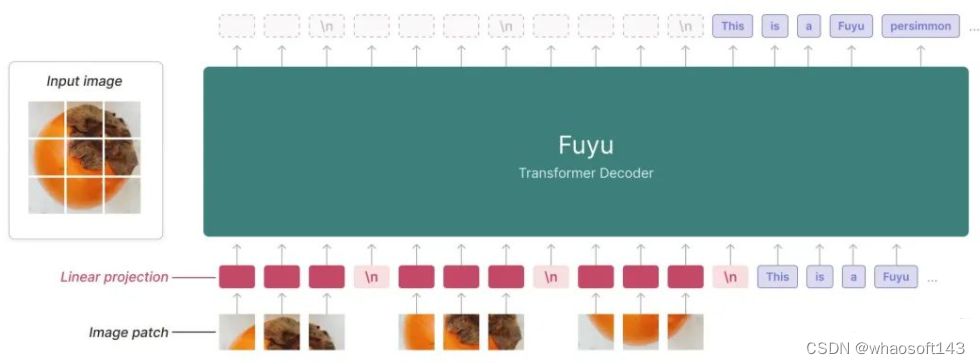
模型采用了一种简单的架构:纯解码器Transformer。
它没有图像编码器。图像块(image patch)绕过embedding lookup,即在嵌入矩阵中查找特定输入的过程,直接映射到Transformer的第一层。
这种架构使得模型能支持任意图像分辨率。
研究团队删除了图像特定位置嵌入,并按扫描线顺序(raster-scan order)输入尽可能多的图像token。
通过一个特殊的图像转换行符号,模型能知道在什么时候断行。
由此模型在训练时可以使用任意大小的图像。
这种架构也更进一步简化了模型的训练和推理过程。
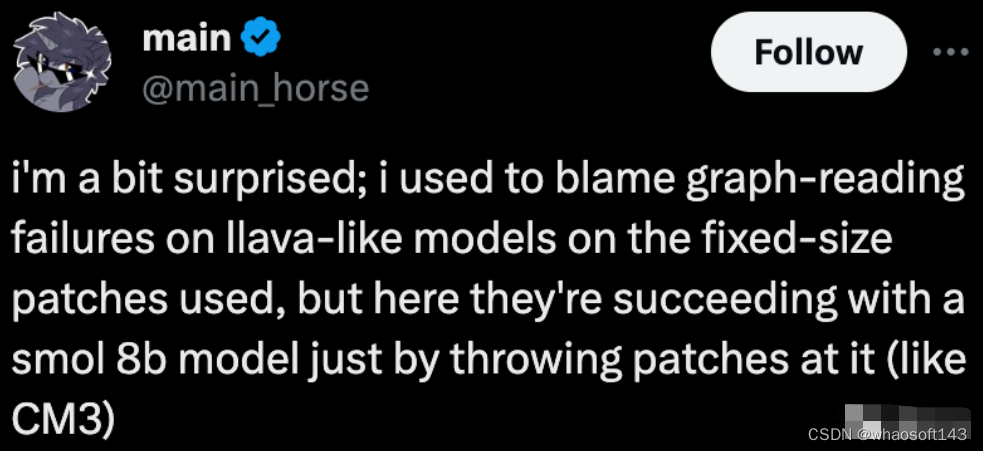
这种架构模式也引起了不少网友的关注,有人就表示,之前总觉得大模型图像理解能力差是因为使用了固定大小的patch。
但Fuyu-8B反驳了他的这一想法。
实验结果显示Fuyu-8B在多个任务中性能优于PaLM-e-12B和QWEN-VL(10B)。
研究团队还表示,刷榜不是他们本次工作的最终目的,所以模型没有进行优化。

他们构建这个大模型的真正目的是为了提升自家产品的能力。
Adept团队致力于打造一个AI Copilot。
这个Copilot能够理解用户屏幕上的内容(比如网页、PPT、PDF、图表等),并能辅助人类快速完成工作。
这就要求大模型需要能理解环境信息,同时可以代替人类进行操作。换言之,需要大模型能具备超强的图像理解能力。
所以这也是为啥Fuyu-8B会很强调对UI的理解能力。
比如它能理解你打开的窗口,以及窗口内的信息。
Demo试玩:
https://huggingface.co/spaces/adept/fuyu-8b-demo
参考链接:
[1]https://www.adept.ai/blog/fuyu-8b
[2]https://twitter.com/AdeptAILabs/status/1714682413983601046
[3]https://twitter.com/julien_c/status/1714694606095310876?s=20
[4]https://twitter.com/main_horse/status/1714684833488949519?s=20















 181
181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









