






本文属于图神经网络的系列文章,文章目录如下:
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一)
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (二)
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (三)
恭喜你看到了本系列的第三篇!前面两篇博客分别介绍了基于循环的图神经网络和基于卷积的图神经网络,那么在本篇中,我们则主要关注在得到了各个结点的表示后,如何生成整个图的表示。其实之前我们也举了一些例子,比如最朴素的方法,例如图上所有结点的表示取个均值,即可得到图的表示。那有没有更好的方法呢,它们各自的优点和缺点又是什么呢,本篇主要对上面这两个问题做一点探讨。篇幅不多,理论也不艰深,请读者放心地看。
图读出操作(ReadOut)
图读出操作,顾名思义,就是用来生成图表示的。它的别名有图粗化(翻译捉急,Graph Coarsening)/图池化(Graph Pooling)。对于这种操作而言,它的核心要义在于:操作本身要对结点顺序不敏感。
这是为什么呢?这就不得不提到图本身的一些性质了。我们都知道,在欧氏空间中,如果一张图片旋转了,那么形成的新图片就不再是原来那张图片了;但在非欧式空间的图上,如果一个图旋转一下,例如对它的结点重新编号,这样形成的图与原先的图其实是一个。这就是典型的图重构(Graph Isomorphism)问题。比如下面左右两个图,其实是等价的:
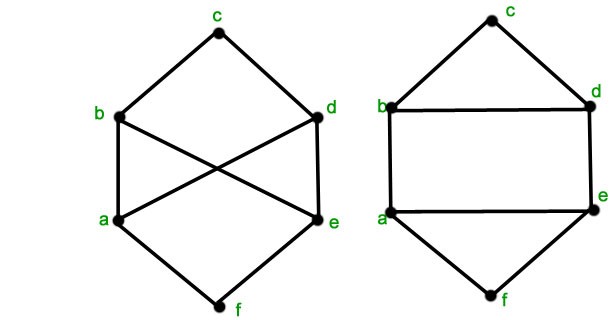
为了使得同构图的表示能够保持一致,图读出的操作就需要对结点顺序不敏感。在数学上,能表达这种操作的函数也被称为对称函数。
那么我们一般如何实现图读出操作呢?笔者接下来主要介绍两种方法:基于统计的方法 与 基于学习的方法。
基于统计的方法(Statistics Category)
基于统计的方法应该是最常见的,比如说我们在求各种抽象表示所使用的 平均(mean),求和(sum),取最大(max) 等操作。这些方法简单有效,又不会带来额外的模型参数。但同时我们必须承认,这些方法的信息损失太大。假设一个图里有 1000个结点,每个结点的表示是 100维;整张图本可表达 1000 * 100 的特征,这些简单的统计函数却直接将信息量直接压缩到了100维。尤其是,在这个过程中,每一维上数据的分布特性被完全抹除。
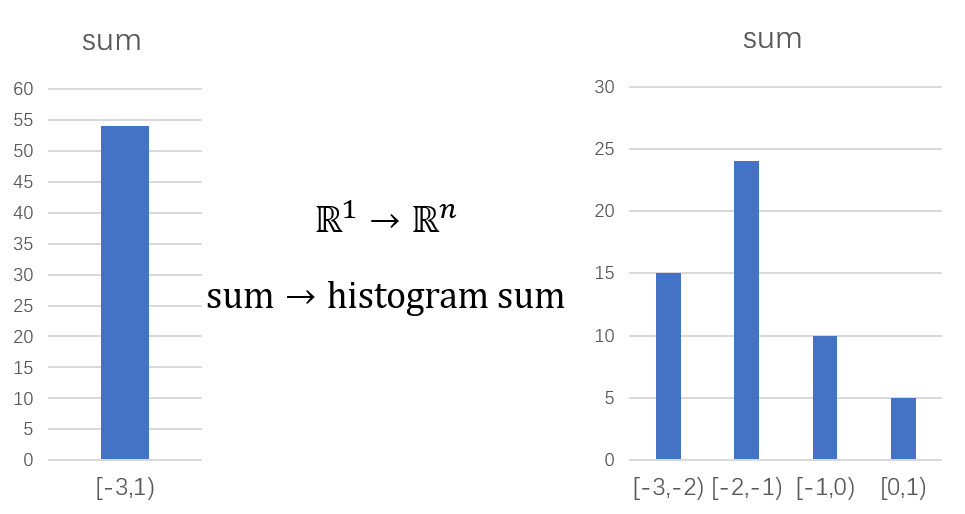
考虑到这一点,文献[1]的作者就提出要用类似直方图的方法来对每维数据分布进行建模。具体而言,请读者先通过下面的对比图来直观感受一下直方图是如何巧妙平衡数据信息与数据分布的。假设我们有100个介于[-3,1]的数字,如果我们直接将它们求和,如左图所示,我们完全看不出这100个数据的分布;而如果我们将[-3, 1]等分成4个区域,分开统计各个区域的和,我们还是可以发现一点原数据的分布特征,如右图所示。
参考文献
[1]. Molecular graph convolutions moving beyond fingerprints, https://arxiv.org/abs/1603.00856
[待续... 挖坑容易 填坑不易啊...]















 8585
8585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









