






Random Shuffle
Goal. Rearrange array so that result is a uniformly random permutation.
(洗牌算法)
Shuffle Sort
使用排序算法来shuffle:
- Generate a random real number for each array entry.
- Sort the array. (以随机数为key来排序,每个item和对应的随机数一起exchange)
分析: 复杂度为$O(n logn)$。
Linear Shuffle
Algorithm
$O(n)$复杂度的shuffle算法——Fisher–Yates shuffle (Knuthe shuffle)。
- In iteration i , pick integer r between 0 and i uniformly at random.
- Swap a[i] and a[r].
Pseudo-code:
/*
Input: an array a of length n.
Output: an shuffled array a.
*/
For i = 0 to n-1
r = random number that in [0,i]
swap a[i] and a[r]或者从后往前循环(Knuth-Durstenfeld Shuffle)
To shuffle an array a of n elements (indices 0..n-1):
for i from n − 1 downto 1 do
j ← random integer such that 0 ≤ j ≤ i
exchange a[j] and a[i]
Java code. ( From Algorithm 4th.)
public static void shuffle(Object[] a)
{
int N = a.length;
for (int i = 0; i < N; i++)
{
// generate random number between 0 and i
int r = StdRandom.uniform(i + 1);
exch(a, i, r);
}
}注意: 产生随机数的范围为$[0, i]$,而不是$[0, n-1]$。
Proof
Proposition. [Fisher-Yates 1938] Fisher-Yates shuffling algorithm produces a
uniformly random permutation of the input array in linear time.
Proof.[^ref]
[^ref]: http://www.cse.cuhk.edu.hk/~taoyf/course/wst501/notes/lec9.pdf
用$S[1], S[2], \dots, S[n]$来表示array中的n个元素,为证明该命题,只需证明如下引理
Lemme. The list of elements $(S[1], \dots, S[n])$ at the end of the algorithm can be any of the $n!$
permutations with the same probability.
即,$(S[1], \dots, S[n])$在算法结束时,可以等概率地生成所有$n!$排列中的任何一个。
使用归纳法来证明:
当算法完成$i=k , (1 \le k \le n)$次循环后,数组$(S[1], \dots, S[k])$可以等概率地生成所有$k!$排列中的任何一个。
- 当$i=1$时,只有$S[1]$一个元素,只有一种排列,显然成立;
- 假设$i=k$时,命题成立;
- 当$i=k+1$时,令$x$为第$k+1$次循环中生成的随机数,$P$为$k+1$次循环之前数组$(S[1], \dots, S[k])$的排列,$P'$表示第$k+1$次循环之后数组的排列,则$P'$为$(P, x)$的函数。则根据命题,$P$有$k!$种可能,而$1 \le x \le k+1$,因此pair $(P, x)$共有$(i+1)!$中可能。
- 下面证明:
- Fact 1: each pair of $(P,x)$ happens with the same probability in the algorithm.
($(P,x)$的每种情况等概率) Fact 2: each pair of $(P,x)$ produces a distinct $P'$.
($(P,x)$的每种情况结果各不相同)- Proof of Fact 1. 根据归纳假设,$P$可能的$k!$种情况等概率,而$x$也是等概率生成的,即$x$为$[1, \dots, k+1]$中的任何一个数的概率都是$1/(k+1)$,因此每种$(P,x)$ pair 出现的概率都为$1/(k+1)!$。
- Proof of Fact 2. 设$(P_1, x_1), (P_2, x_2)$为两个不同的pair,则至少满足如下两个不等式中的一个$P_1 \ne P_2, x_1 \ne x_2$。令$P'_1, P'_2$为上述两个pair分别所生成的,
Case 1: $P_1 = P_2$. 则$x_1 \ne x_2$,因此$P'_1, P'_2$在第$k+1$个位置拥有不同的元素(分别为$S[x_1], S[x_2]$);
Case 2:$P_1 \ne P_2$. 设$P_1$与$P_2$在位置$j$上有不同的元素。若$x_1 \ne x_2$或$x_1 = x_2 \ne j$,那么$P'_1, P'_2$仍然在位置$j$拥有不同的元素; 否则($x_1 = x_2 = j$),$P'_1, P'_2$在位置$k+1$有不同的元素。
- Fact 1: each pair of $(P,x)$ happens with the same probability in the algorithm.
$\square$
A Common Mistake
一种常见的错误是在循环中产生的随机数范围为整个数组长度(the naïve algorithm),这种方法的概率分布是不均衡的。
The naïve algorithm.
for i=0 to n-1
swap(A[i], A[random(n)])
以数列[1, 2, 3]为例,两种方法的可能结果如下图所示。图1为naïve algorithm产生的结果,从图中可以明显看出结果中包含有重复项,并且每项重复的次数不同。
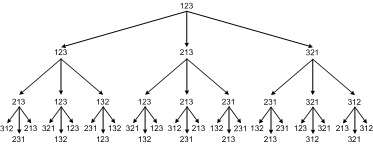
图1 - bias
图2 - uniform
从数学上看,naïve algorithm一共可以产生$n^n$种结果,而不同的permutation一共有$n!$种。由于当$n > 2$时,$n^n$不能被$n!$除尽(因为$n$与$n-1$没有共同的质因子),因此naïve algorithm不可能产生uniform distribution。
更进一步的对比分析见:
Python - random.shuffle
Python random module中shuffle的源码,使用Knuth-Durstenfeld Shuffle算法。
def shuffle(self, x, random=None):
"""x, random=random.random -> shuffle list x in place; return None.
Optional arg random is a 0-argument function returning a random
float in [0.0, 1.0); by default, the standard random.random.
"""
if random is None:
random = self.random
_int = int
for i in reversed(xrange(1, len(x))):
# pick an element in x[:i+1] with which to exchange x[i]
j = _int(random() * (i+1))
x[i], x[j] = x[j], x[i]














 158
158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









