






模式分类(Pattern Recognition/Classification)笔记--聚类分析算法
模式分类课程笔记。码字不易,转载注明出处:http://www.cnblogs.com/Lin-chun/p/6894544.html
1、什么是聚类分析算法
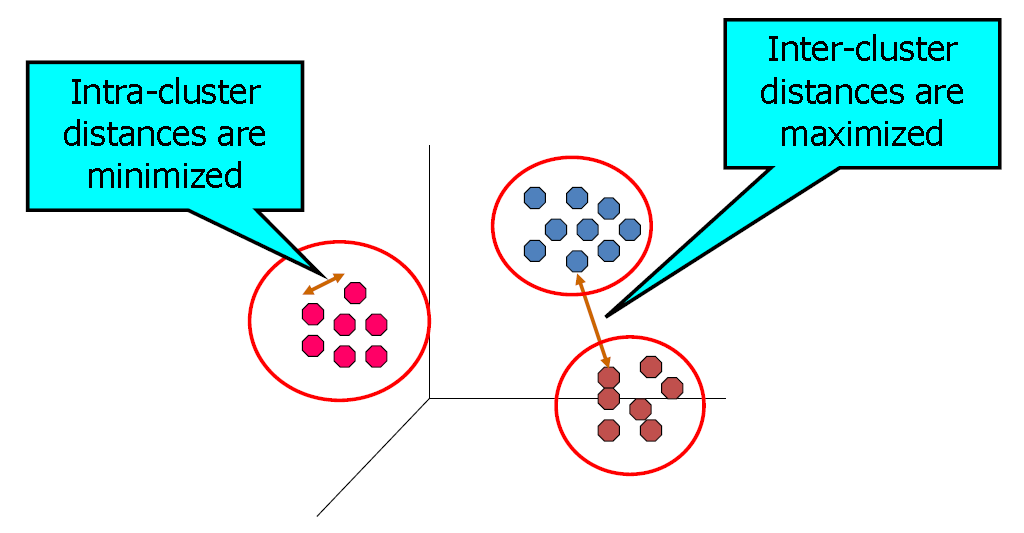
在讲聚类算法之前,需要先了解一下什么是监督学习和无监督学习。所谓的监督学习就是发现原始数据属性和标签属性之间的内在模式关系。然后利用这些模式预测新的数据实例中目标属性的值。换句话说就是希望学习到已标签化的数据的内在模式,从而能用这种模式去预测相近的新数据。而无监督学习是没有目标属性的方法,希望的是直接找到数据的内在固有属性。所谓的无监督和有监督的关键差别在于有无人工标注的原始数据。接着我们看一下聚类分析的详细定义。聚类分析是一种通过发现对象的内在类别性质,使对象间彼此相似(或相关)的部分聚集,并与其他类别中的对象尽量不相关(或远离)。可以从下图中看出,聚类算法的目标是让数据相同类的类内距尽量达到最小,而让不同类的类间距尽量达到最大。显然,从定义来看,聚类算法是一种无监督的算法。
2、聚类算法的种类
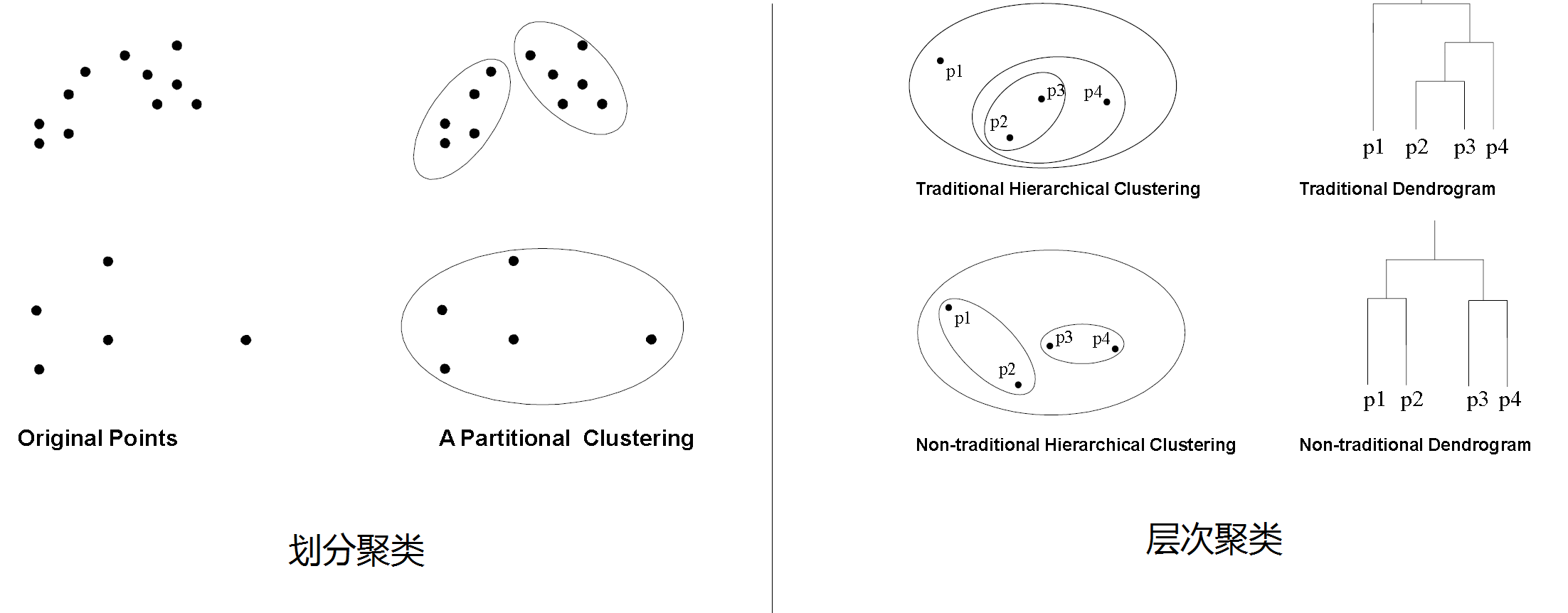
聚类算法其实有很多种,但是大体上来分可以分为划分聚类以及层次聚类。前者的目标是让数据能划分为彼此不重叠的子集,后者则是一组嵌套的聚集组织形成层次树。可以从下面的图示中得到两种算法的差别:
划分聚类:每个实例都被安置在特定的第K个非重叠的类别中。由于只输出一组集群,所以用户通常必须输入所需聚类数量K。
层次聚类:生成一组以层次树形式组织的嵌套聚类,其聚类过程可被可视化为树状图。
虽然聚类算法有多种多样,但是我们可以对聚类算法做统一建模。假设数据点$j$到聚类中心$i$的聚类为$Se_{ji}$,我们可以用距离来作为目标函数,$Se_{K_i}=\sum_{x_j \ in Cluster_i}\parallel x_j - C_i \parallel ^2$。这样总的目标函数就是:
$\quad min Se_k =\sum_{i=1}^{k}Se_{K_i}$
3、K-means聚类算法
K-means聚类是一种很常见的划分聚类算法。假设我们有一组数据集$D=\left \{X_1,X_2,...,X_n \right \}$,其中$X_i=(x_{i1},x_{i2},...,x_{ir})$是实值向量空间$X \subseteq R^r$中的向量。$r$是数据中的属性(维度)。K-meas算法将数据划分为k个聚类,每个类中都有个聚类中心。具体的算法如下:
1.输入要聚类的个数k;
2.初始化k个聚类中心,通常采用随机的方式来确定;
3.通过将它们分配给最近的聚类中心来确定所有N个对象具体属于哪个类别;
4.假定上一步的划分为正确,重新在新的划分基础上评估k个聚类中心;
5.如果任意一个对象没有在迭代中重新进行类别划分,那么退出迭代,否则转到第三步。
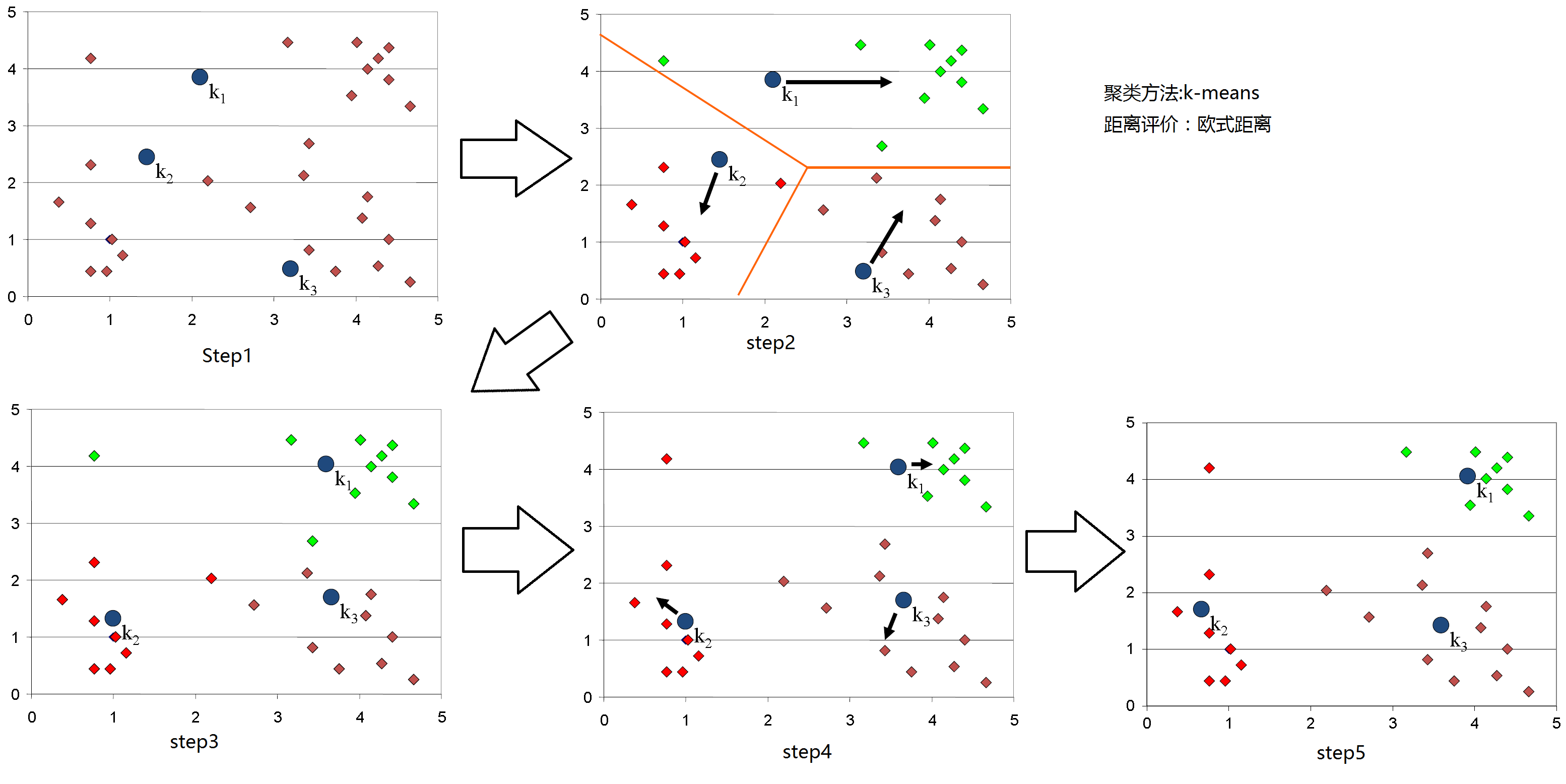
下面的图例可以显示聚类的详细步骤
到目前为止,我们介绍了K-means算法的大致思路,然而还有一个问题没有解决,那就是如何确定聚类的数目k。在实际的应用中,我们并不知道类别到底是多少,或者我们并不清楚数据的分布情况。下面我们举个例子:
下面这组数据中,理想的状态为两聚类,然而事实上我们并不知道聚类的数目。
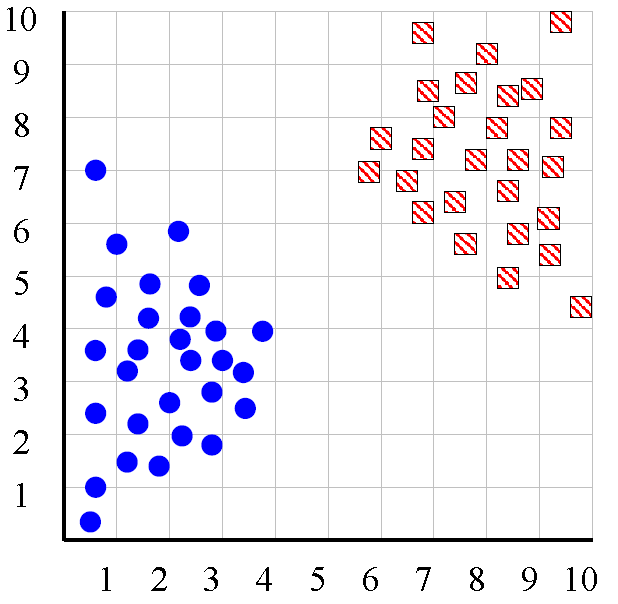
我们尝试着用k=1,k=2,k=3,,,不同的参数有不同的目标函数值。
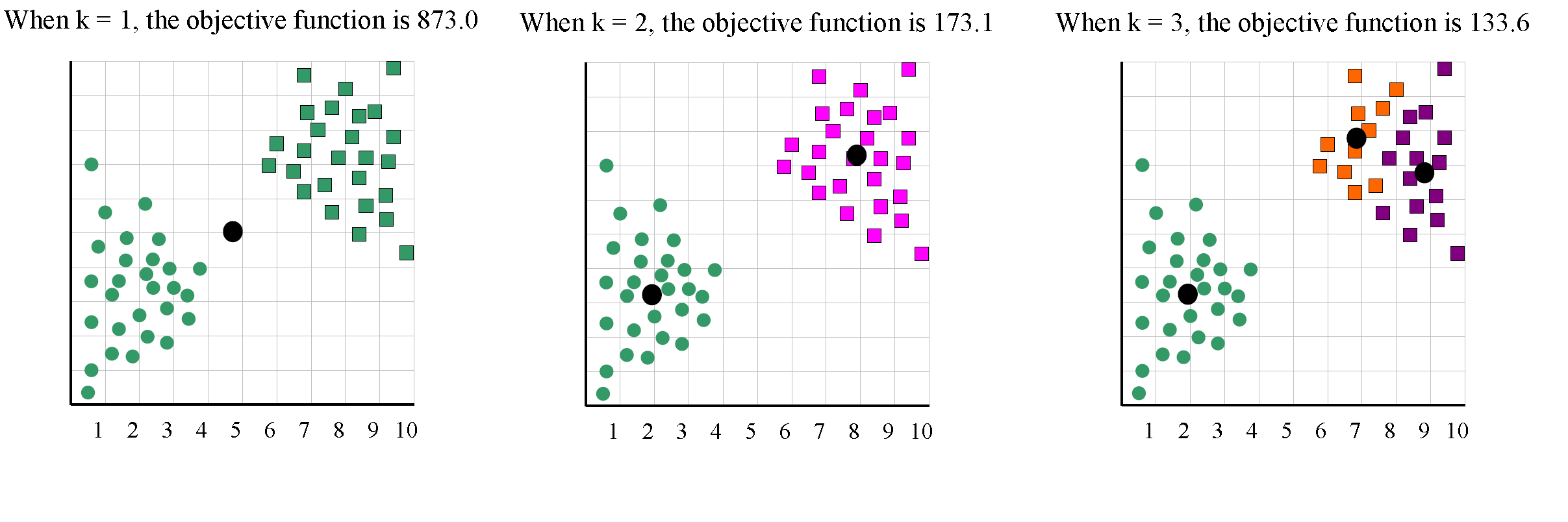
把k=1到6得到的目标函数数据进行绘制,得到如下图:
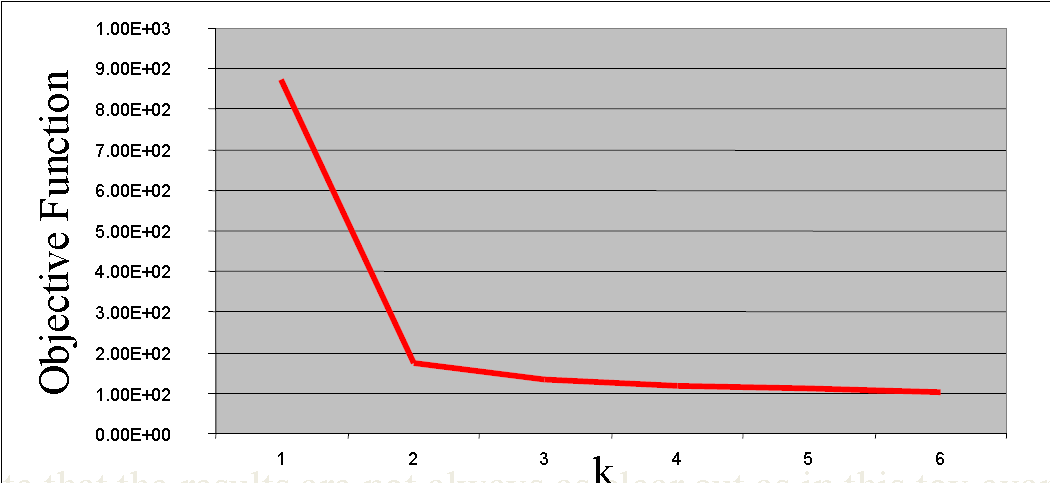
从上述的实验结果我们可以看出,聚类个数从1到2的时候目标函数值出现了一个很陡的下降,那么我们是不是可以从这个图上获得一些启示,从而对目标函数做一定的改进?显然,如果在目标函数的后面加入一个带有k的正则项,那么就能将上述的实验结果引入最终的目标函数中。回顾下上面的聚类目标函数:
$\quad Se_{K_i}=\sum_{x_j \ in Cluster_i}\parallel x_j - C_i \parallel ^2$。
$\quad min Se_k =\sum_{i=1}^{k}Se_{K_i}$
我们有理由将上述$ min Se_K$写成$ min Se_K+cK$的形式,其中$c$是任意的常数。
虽然我们能对其目标函数进行改进,但是K-means聚类还是有先天的缺点的。
1.聚类算法对于异常值很敏感。解决异常值的干扰通常是在移除距离聚类中心过远的数据点,或者对数据进行重采样,因为数据中的异常值被重新采样得到的几率会大大降低。
2.聚类算法对于初始种子点的选择很敏感。解决方案通过随机采样k个种子点,然后利用一些算法做前期处理使得种子点更加满足我们的需求。
3.对于非超椭球的数据难以聚类。
虽然K-means具很多缺点,但是由于具有高效以及简洁的表示,K-means聚类仍旧是最流行的聚类算法之一。另外从机器学习的角度来讲,由于“没有免费的午餐”定理,任何机器学习算法在无限多的数据集中,期望总是趋于一致。因此其他算法也具有不同的缺点。从这个角度上来看,简单而效果好的方法才是更重要的。
4、模糊C均值聚类算法
模糊C聚类算法(FCM)通过最小化下列目标函数达到聚类效果:
$J_f(C,m)=\sum_{i=1}^{C}\sum_{k=1}^{N}(u_{k,i})^md_{k,i}$
$s.t. \sum_{i=1}^{C}u_{i,k}=1$
其中,$C$ - 是聚类的个数
$N $ - 是数据点的个数
$u_{k,i}$ - 是第k个点到第i个聚类中心的模糊隶属度
$d_{k,i}$ - 是第k个数据点到聚类中心i欧式距离
$m \in (1,\infty)$ - 是模糊权重因子定义了结果的模糊程度(通常m=2)
为了描述FCM算法,我们需要对一些概念进行定义,首先根据数据的模糊权重分布定义聚类的中心$v$,
$v_i=\frac{\sum_{k=1}^{N}(u_{k,i}^m x_k)}{\sum_{k=1}^{N}(u_{k,i})^m},i=1,2,...,C$
最小化划分函数将会得到下列的隶属度表达式:
$u_{i,k}=\frac{1}{\sum^{C}_{j=1}(\frac{d_{k,i}}{d{k,j}})^{\frac{2}{m-1}}}$
欧式距离定义为:
$(d_{k,i})^2=\parallel x_k-v_i\parallel^2$
接着有了上述的定义,我们就能进一步对FCM算法进行描述:
1.选择类别的数目$C,2\leq C\leq n$;让$m=2$,初始化$U^{(0)}$,一般都是取随机值
2.计算出聚类的中心$v_i$;
3.计算出新的隶属度划分矩阵$U^{(1)}$;
4.对比$U^{(j)}$和$U^{(j+1)}$。如果隶属度的变化程度小于给定阈值,那么停止迭代,否则就回到第2步。
为了进一步理解FCM聚类,我们给出一个具体的例子:
初始的中心点为3和11,m设置为2

对于节点2(第1个点),计算出隶属度:
$u_{1,1}=\frac{1}{(\frac{2-3}{2-3})^\frac{2}{2-1}+(\frac{2-3}{2-11})^\frac{2}{2-1}}=\frac{1}{1+\frac{1}{81}}=\frac{81}{82}=98.78\%$
$u_{1,2}=\frac{1}{(\frac{2-11}{2-3})^\frac{2}{2-1}+(\frac{2-11}{2-11})^\frac{2}{2-1}}=\frac{1}{1+81}=\frac{1}{82}=1.22\%$
对于节点3(第2个点)
$u_{2,1}=100\%$
$u_{2,2}=0\%$
对于节点4(第3个点)
$u_{3,1}=\frac{1}{(\frac{4-3}{4-3})^\frac{2}{2-1}+(\frac{4-3}{4-11})^\frac{2}{2-1}}=\frac{1}{1+\frac{1}{49}}=\frac{1}{\frac{50}{49}}=98\%$
$u_{3,2}=\frac{1}{(\frac{4-11}{4-3})^\frac{2}{2-1}+(\frac{4-11}{4-11})^\frac{2}{2-1}}=\frac{1}{1+49}=\frac{1}{50}=2\%$
对于节点7(第4个点)
$u_{4,1}=\frac{1}{(\frac{7-3}{7-3})^\frac{2}{2-1}+(\frac{7-3}{7-11})^\frac{2}{2-1}}=\frac{1}{1+1}=\frac{1}{2}=50\%$
$u_{4,2}=\frac{1}{(\frac{7-11}{7-3})^\frac{2}{2-1}+(\frac{7-11}{7-11})^\frac{2}{2-1}}=\frac{1}{1+1}=\frac{1}{2}=50\%$
更新聚类中心:
$v_1=\frac{0.9878^2*2+1^2*3+0.98^2*4+0.5^2*7+....}{0.98^2+1^2+0.98^2+0.5^2+...}$
$v_2=\frac{0.0122^2*2+0^2*3+0.02^2*4+0.5^2*7+...}{0.0122^2+0^2+0.02^2+0.5^2+...}$
5、融合聚类算法
融合聚类算法是层次聚类的一种。层次聚类又可以分自顶向下的Divisive与自底向上的Agglomerative。融合聚类是一种比较流行的层次聚类技术。基本的算法比较简单,基本上可以从下列过程中得到:
首先计算距离矩阵,接着让每个点聚为一个类,不断重复把两个相近的类融合为一个,并更新距离矩阵。最后更新直到只剩下一个类。过程图可以总结如下:
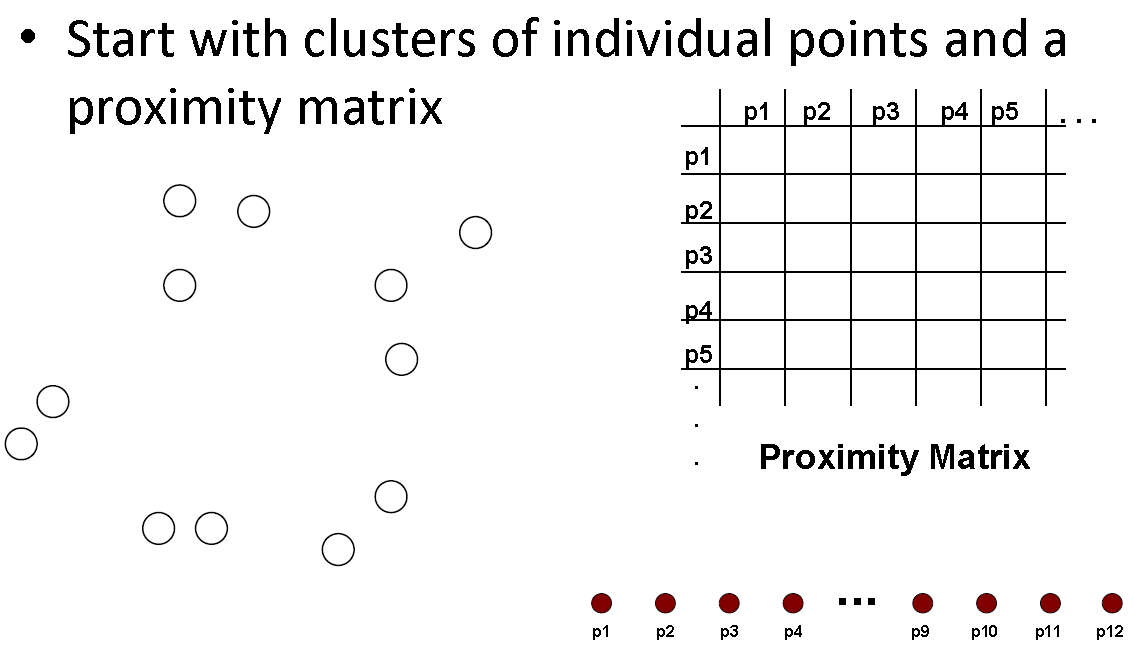



那么从上述的过程来看,我们还需要直到如何更新距离矩阵。两个类之间的平均成对距离可以定义为:
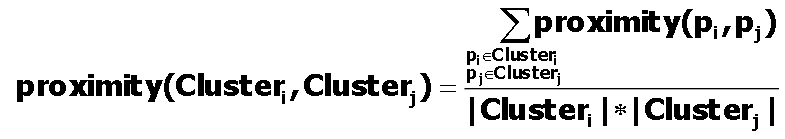
6、总结
- 无监督的学习是探索数据中的一些内在结构。
- 聚类分析是将数据点分组成类,使得类内相似度高,类间相似度低。
- k-means是最流行的算法,由于其简单性和效率。
- 模糊c均值从人类的模糊想法出发,表示模糊的量。
- 层次聚类产生组织为层次树的嵌套集群。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









