






损失函数,一般由两项组成,一项是loss term,另外一项是regularization term。
J=L+R
先说损失项loss,再说regularization项。
1. 分对得分1,分错得分0.gold standard
2. hinge loss(for softmargin svm),J=1/2||w||^2 + sum(max(0,1-yf(w,x)))
3. log los, cross entropy loss function in logistic regression model.J=lamda||w||^2+sum(log(1+e(-yf(wx))))
4. squared loss, in linear regression. loss=(y-f(w,x))^2
5. exponential loss in boosting. J=lambda*R+exp(-yf(w,x))
再说regularization项,
一般用的多的是R2=1/2||w||^2,R1=sum(|w|)。R1和R2是凸的,同时R1会使得损失函数更加具有sparse,而R2则会更加光滑些。具体可以参见下图:

caffe的损失函数,目前已经囊括了所有可以用的了吧,损失函数由最后一层分类器决定,同时有时会加入regularization,在BP过程中,使得误差传递得以良好运行。
contrastive_loss,对应contrastive_loss_layer,我看了看代码,这个应该是输入是一对用来做验证的数据,比如两张人脸图,可能是同一个人的(正样本),也可能是不同个人(负样本)。在caffe的examples中,siamese这个例子中,用的损失函数是该类型的。该损失函数具体数学表达形式可以参考lecun的文章Dimensionality Reduction by Learning an Invariant Mapping, Raia Hadsell, Sumit Chopra, Yann LeCun, cvpr 2006.
euclidean_loss,对应euclidean_loss_layer,该损失函数就是l=(y-f(wx))^2,是线性回归常用的损失函数。
hinge_loss,对应hinge_loss_layer,该损失函数就是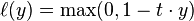 。主要用在SVM分类器中。
。主要用在SVM分类器中。
infogain_loss,对应infogain_loss_layer,损失函数表达式没找到,只知道这是在文本处理中用到的损失函数。
multinomial_logistic_loss,对应multinomial_logistic_loss_layer,
sigmoid_cross_entropy,对应sigmoid_cross_entropy_loss_layer,也就是logistic regression使用的损失函数。
softmax_loss,对应softmax_loss_layer,损失函数等可以见UFLDL中关于softmax章节。在caffe中多类分类问题,损失函数就是softmax_loss,比如imagenet, mnist等。softmax_loss是sigmoid的多类问题。但是,我就没明白,multinomial_logistic_loss和这个有什么区别,看代码,输入有点差别,softmax的输入是probability,而multinomial好像不要求是probability,但是还是没明白,如果只是这样,岂不是一样啊?
这里详细说明了两者之间的差异,并且有详细的测试结果,非常赞。简单理解,multinomial 是将loss分成两个层进行,而softmax则是合在一起了。或者说,multinomial loss是按部就班的计算反向梯度,而softmax则是把两个步骤直接合并为一个步骤进行了,减少了中间的精度损失等 ,从计算稳定性讲,softmax更好,multinomial是标准做法,softmax则是一种优化吧。
转自caffe:
Softmax
- LayerType:
SOFTMAX_LOSS
The softmax loss layer computes the multinomial logistic loss of the softmax of its inputs. It’s conceptually identical to a softmax layer followed by a multinomial logistic loss layer, but provides a more numerically stable gradient.
references:
http://www.ics.uci.edu/~dramanan/teaching/ics273a_winter08/lectures/lecture14.pdf
http://caffe.berkeleyvision.org/tutorial/layers.html
Bishop, pattern recognition and machine learning
http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
http://freemind.pluskid.org/machine-learning/softmax-vs-softmax-loss-numerical-stability/














 1455
1455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









