







一、Nccl AllReduce基本原理:
allreduce是collective communication中的一种,其他种类的还有:Broadcast、Scatter、Gather、Reduce等
具体含义可以参考文档:https://images.nvidia.com/events/sc15/pdfs/NCCL-Woolley.pdf、
其中nccl采用一种Undirectional-Ring的单向环算法,可以实现同步时间与卡的个数无关,以BroadCast为例:
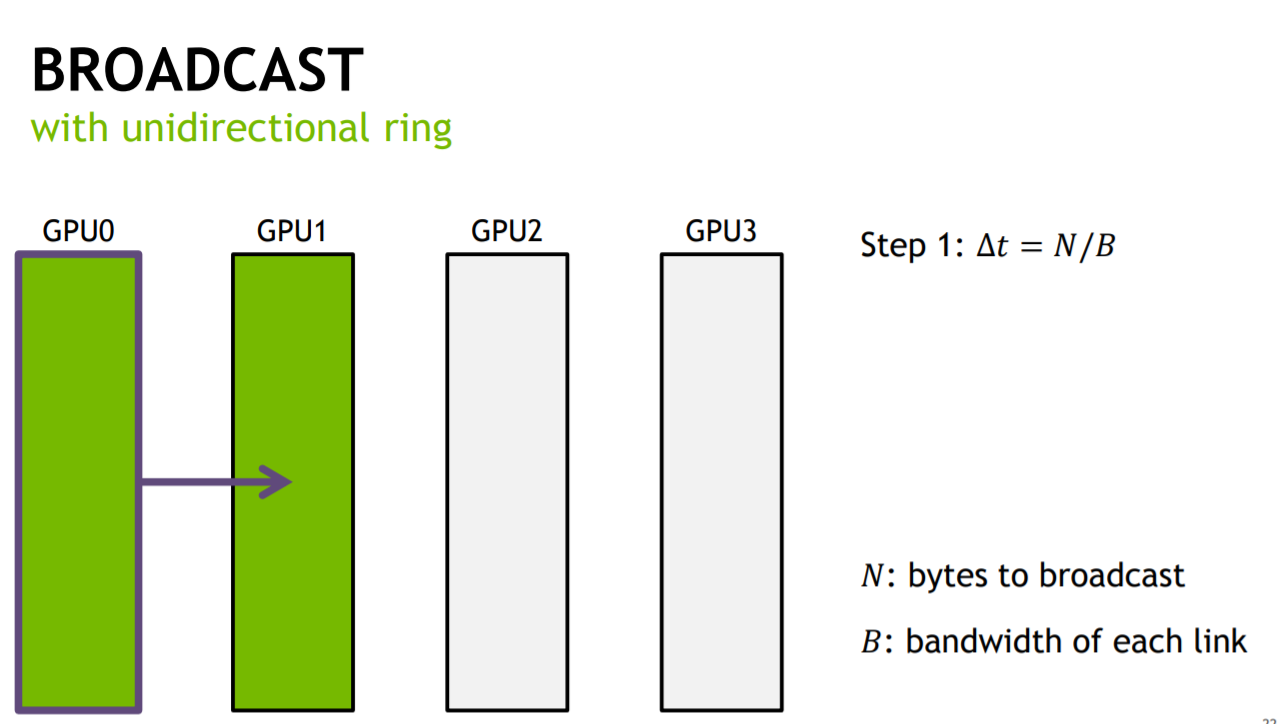
假设有4块GPU,传输的数据量为N,传输带宽为B(单机多卡间的传输带宽可以通过cuda/sample下的p2pBandwidthLatencyTest得到),如果按照顺序发送的方式,完成整个BroadCast的时间(同步时间)为:(4-1)N/B,即传输时间与卡的个数成正比.

如果将N大小的数据分成S份,然后GPU0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5043
5043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









