







(2017年)百度将高性能计算引入深度学习:可高效实现模型的大规模扩展
RingAllreduce;适用于单机多卡/多机多卡;
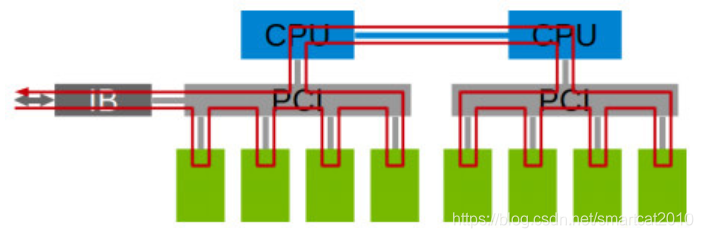
关键在于认识到机器硬件拓扑,然后根据拓扑去构建使得最大的边延迟最小的方案;
(Step1, Step2, Step3那种AllReduce,在多机通过交换机互联情况下,也可以和机器数目无关);




最后再进行5轮类似的传输,所有GPU上就都有了各段之和;
NCCL是最快的!
不同的GPU卡拓扑,采用环形AllReduce,性能是不同的:(1经过CPU和QPI总线;2经过CPU;3经过PCIe总线;4

DGX-1
GPU卡之间用多组NVLINK(50GB/s双向带宽的高速数据线)连接;

nvidia-smi命令可查看GPU卡之间的拓扑连接
知乎文章
介绍了带宽:PCIe switch(10.6GB/s) > PCIe host bridge(CPU自带, 10.1GB/s) > QPI(9.1GB/s), 差别不大;(Infiniband能到8GB/s)
CUDA自带测试单机各卡P2P通信带宽的代码;
袁进辉:
除了Ring allreduce,还增加了double tree拓扑的allreduce,在节点更多时表现更出色。NCCL 性能好,有多方面原因,1,拓扑算法,ring allreduce, double tree拓扑等;2,细节处理好,gpu p2p数据搬运,GPU-Direct支持等;3,节点间支持RDMA和socket,前者在特定网络设备上表现特别好;4,手工实现了一个类似cuda stream的任务队列,方便从host向device派遣任务;5,在cuda kernel上限定每个block使用比较少数thread,集群操作不太影响其他计算任务;6,把host memory映射到device地址空间,从device直接访问host,流式处理数据搬运和计算;7,device之间使用底层通信原语进行同步,而不是cuda api里的event。
Uber的Horovod
由于 TensorFlow 集群太不友好,业内也一直在尝试新的集群方案。
2017 年 Facebook 发布了《Accurate, large minibatch SGD: Training ImageNet in 1 hour 》验证了大数据并行的高效性,同年百度发表了《Bringing HPC techniques to deep learning 》,验证了全新的梯度同步和权值更新算法的可行性。受这两篇论文的启发,Uber 开发了 Horovod 集群方案。
Horovod 的梯度同步和权值同步就采用了 ring-allreduce 算法。Horovod 的数据传递是基于 MPI
DGX-2的NvSwitch
NVSwitch是一种畅通无阻的设备,具有18个NVLink端口,每端口51.5 GBps,聚合双向带宽达928 GBps。
byteps
byteps+NCCL性能高于Horovod+NCCL;
单机内部用的NCCL,机器之间用的自研通信;
解释:allreduce会是数据量的2倍发送+接收(NCCL文档里解释的很清楚,还有好几种通信操作的复杂度);ps是1倍发送+接收;Tensorflow和Mxnet的ps工程实现差劲;
郭传雄的paper :层数越靠前的,梯度传输优先级越高,因为马上就要用更新后的层来计算Forward了;用了分小块传输(充分利用双向带宽,push和pull同时进行),在优先级和网络不闲置方面的最优trade-off。














 1285
1285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









