






I'm trying to minimize the following function with scipy.optimize:
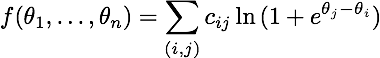
whose gradient is this:
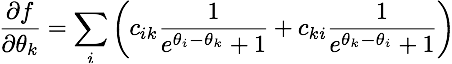
(for those who are interested, this is the likelihood function of a Bradley-Terry-Luce model for pairwise comparisons. Very closely linked to logistic regression.)
It is fairly clear that adding a constant to all the parameters does not change the value of the function. Hence, I let \theta_1 = 0. Here are the implementation the objective functions and the gradient in python (theta becomes x here):
def objective(x):
x = np.insert(x, 0, 0.0)
tiles = np.tile(x, (len(x), 1))
combs = tiles.T - tiles
exps = np.dstack((zeros, combs))
return np.sum(cijs * scipy.misc.logsumexp(exps, axis=2))
def gradient(x):
zeros = np.zeros(cijs.shape)
x = np.insert(x, 0, 0.0)
tiles = np.tile(x, (len(x), 1))
combs = tiles - tiles.T
one = 1.0 / (np.exp(combs) + 1)
two = 1.0 / (np.exp(combs.T) + 1)
mat = (cijs * one) + (cijs.T * two)
grad = np.sum(mat, axis=0)
return grad[1:] # Don't return the first element
Here's an example of what cijs might look like:
[[ 0 5 1 4 6]
[ 4 0 2 2 0]
[ 6 4 0 9 3]
[ 6 8 3 0 5]
[10 7 11 4 0]]
This is the code I run to perform the minimization:
x0 = numpy.random.random(nb_items - 1)
# Let's try one algorithm...
xopt1 = scipy.optimize.fmin_bfgs(objective, x0, fprime=gradient, disp=True)
# And another one...
xopt2 = scipy.optimize.fmin_cg(objective, x0, fprime=gradient, disp=True)
However, it always fails in the first iteration:
Warning: Desired error not necessarily achieved due to precision loss.
Current function value: 73.290610
Iterations: 0
Function evaluations: 38
Gradient evaluations: 27
I can't figure out why it fails. The error gets displayed because of this line:
https://github.com/scipy/scipy/blob/master/scipy/optimize/optimize.py#L853
So this "Wolfe line search" does not seem to succeed, but I have no idea how to proceed from here... Any help is appreciated!
解决方案
As @pv. pointed out as a comment, I made a mistake in computing the gradient. First of all, the correct (mathematical) expression for the gradient of my objective function is:
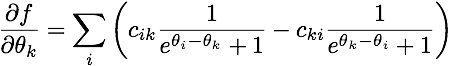
(notice the minus sign.) Furthermore, my Python implementation was completely wrong, beyond the sign mistake. Here's my updated gradient:
def gradient(x):
nb_comparisons = cijs + cijs.T
x = np.insert(x, 0, 0.0)
tiles = np.tile(x, (len(x), 1))
combs = tiles - tiles.T
probs = 1.0 / (np.exp(combs) + 1)
mat = (nb_comparisons * probs) - cijs
grad = np.sum(mat, axis=1)
return grad[1:] # Don't return the first element.
To debug it , I used:
scipy.optimize.check_grad: showed that my gradient function was producing results very far away from an approximated (finite difference) gradient.
scipy.optimize.approx_fprime to get an idea of the values should look like.
a few hand-picked simple examples that could be analyzed by hand if needed, and a few Wolfram Alpha queries for sanity-checking.















 2866
2866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









