







写在最前面:首先需要说一下,本文的bootstrap和jackknife都算是蒙特卡罗方法(Monte Carlo method)的一种。应用广泛的的MCMC链(马尔可夫链蒙特卡洛方法;Markov chain Monte Carlo)也是蒙特卡罗与马尔可夫链的结合。简单来说,蒙特卡罗方法就是从已知样本的分布中随机抽取新的样本集进行评估,然后放回,再次抽取的方法。根据具体方法的不同,抽取样本集的手段也不同。
bootstrap方法
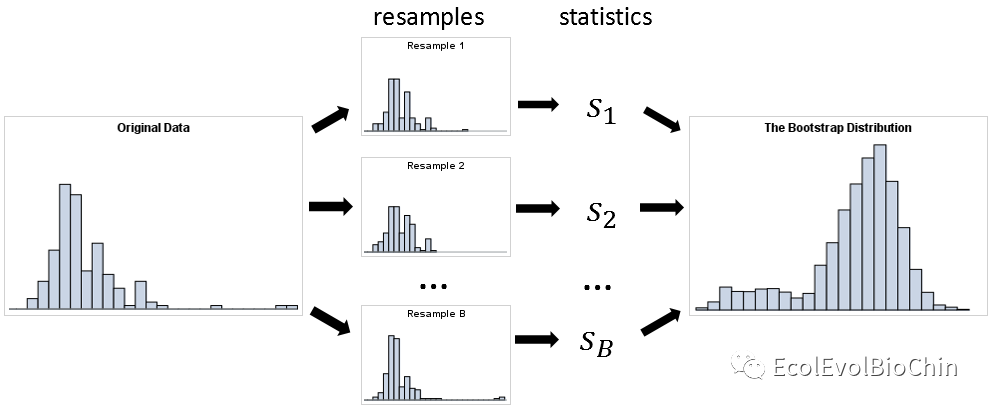
bootstrap抽样方法将观测到的样本视为一个有限的总体,是唯一的信息来源,从中有放回的随机抽样来评估总体特征,以及对抽样总体进行推断统计。bootstrap 也分参数bootstrap和非参数bootstrap,前者的分布已完全知道。但在生信领域一般没有这种情况。所以下面讨论的是非参数bootstrap。
直接上例子:假设现在有bootstrap包中的law数据集如下,
> library(bootstrap)
> data(law)
> law
LSAT GPA
1 576 3.39
2 635 3.30
3 558 2.81
4 578 3.03
5 666 3.44
6 580 3.07
7 555 3.00
8 661 3.43
9 651 3.36
10 605 3.13
11 653 3.12
12 575 2.74
13 545 2.76
14 572 2.88
15 594 2.96
现在我们要计算LSAT成绩(美国法学入学考试)和GPA之间的相关系数。但因为样本量太少了,所以我们使用bootstrap重复抽样评估其标准误。
library(bootstrap)
data(law)
law
cor(law$LSAT, law$GPA)
print(cor(law$LSAT, law$GPA))
#设置bootstrap循环
B #重复抽样的次数
n #样本大小(15个)
R #储存每次循环后计算得到的相关系数
#对R的标准差进行bootstrap评估(通过计算每次抽样的标准差)
for (b in 1:B) {
#randomly select the indices
i # 从1:n的范围内有放回地抽取n个样本
LSAT $LSAT[I]
GPA $GPA[I]
R[b] }
#output
print(se.R #多次抽样的 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









