






什么是KMP算法?
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。
暴力搜索算法实现
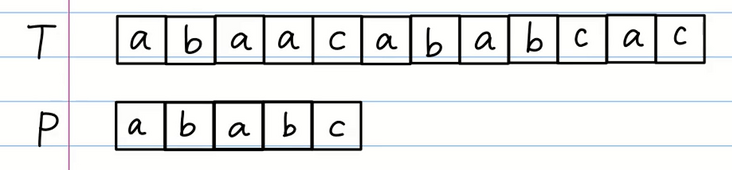
请问,在字符串 T 中是否包含 P 的 "ababc"?
我们可以从第一个字符开始比对,如下图:
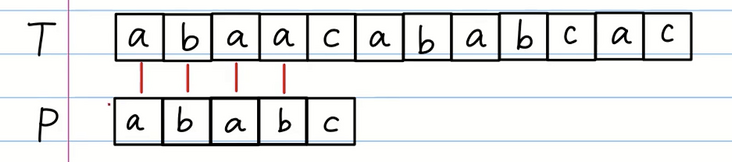
在第四次比对的时候,我们发现 T 字符串和 P 字符串并不一致。
我们将字符串 P 整体后移一位重新进行对比。
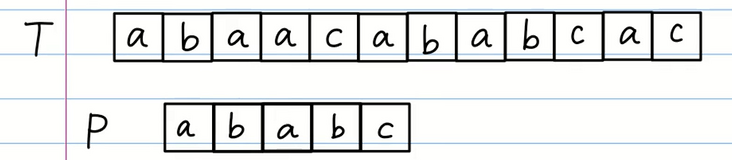
第一次比对我们就发现 T 字符串和 P 字符串比对不上。所以我们需要继续后移 P 字符串进行对比。
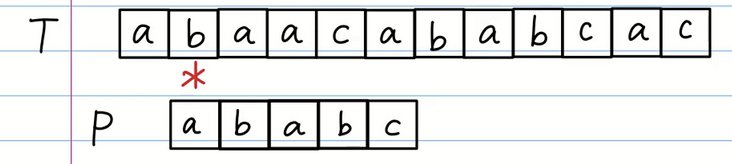
以此类推,当所有字符能匹配上则说明匹配成功,如果匹配到 T 的末尾都没有成功的话则失败,此算法效率很低。
KMP算法实现
请问,在字符串 T 中是否包含 P 的 "ababc"?
第一步:
在学习KMP算法之前,我们需要先了解前缀表(Prefix Table)。
我们先做的就是找到字符串长度较短的字符串,也就是字符串 P。
a
a b
a b a
a b a b
一共有四个前缀。
第二步:
我们需要找出最长公共前后缀并且比原始字符串短。
这句话有点不太好理解,我们使用a b a b来举例子。
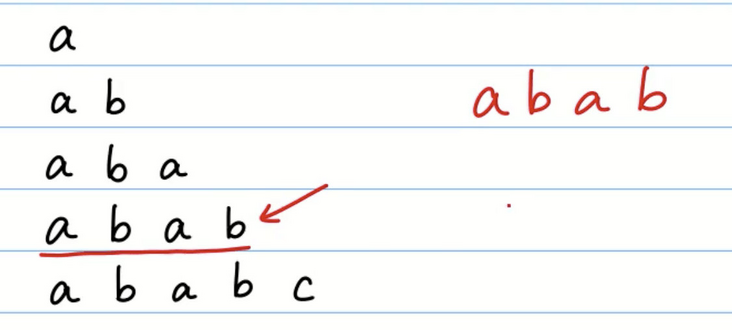
我们可以看到 a b a b 最长前缀就是 a b a,最长后缀就是 b a b。

但是我们发现这两个字符串明显是不一样的。

3个字符的前后缀明显不同,所以我们使用2个字符前后缀进行匹配看看。
我们发现 前缀是 a b 后缀也是 a b 。这样我们就知道最长公共前后缀是2。

然后我们继续往上看 a b a 很明显它的公共前后缀就是1。如果我们用2来看的话就是 ab 和 ba 很明显是不同的。
ok。再往上就是 a b 很明显,1是不匹配的。所以最长公共前后缀是0。 a 也一样。
我们看下最终是怎样的。

我们进行整体向右移动一位,然后初始值赋为 -1 可以得到如下结果:ababa-10012
这样我们去进行和 T 字符串进行比对,当比对到下标为3时,我们发现 a 和 b不同匹配失败。
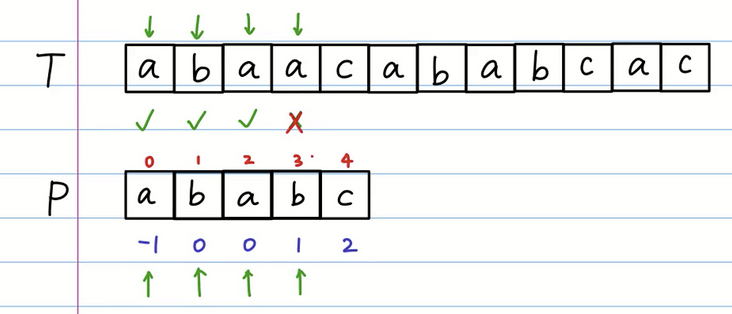
这个时候我们应该怎么做?
我们发现在 P 数组中下标为3的 b 匹配错误,而 b 的前缀表是 1,我们需要将 P 数组下标为 1 的位置 移动 T 数组匹配失败的位置。
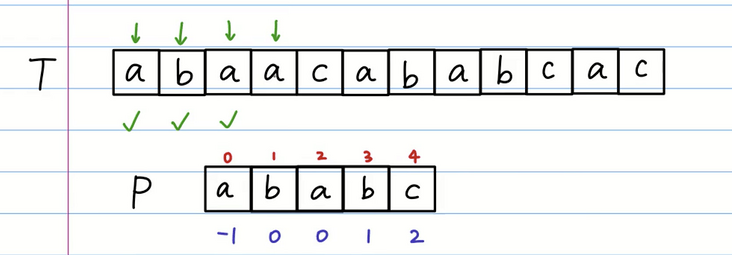
但是我们发现匹配还是错误的,我们可以知道 b 的 前缀表是 0 所以我们让下标为0的位置整体移动到 T 数组匹配失败的位置。
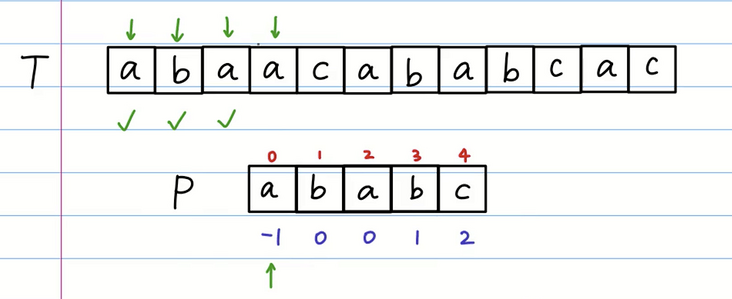
我们重新进行匹配,发现第一个 a 相等,第二个 b 和 c 不相等。
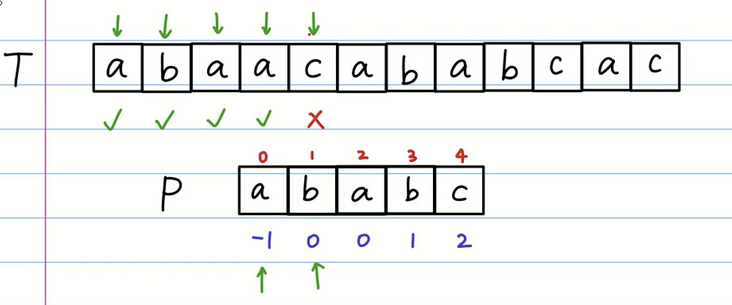
我们继续移动,b 的前缀表是 0 所以我们让下标为0的位置整体移动到 T 数组匹配失败的位置。但是还是 a 和 c 匹配失败。
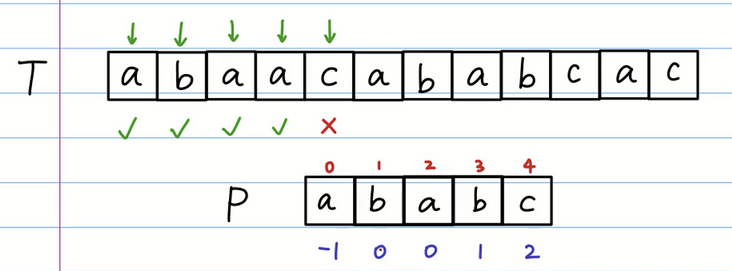
但是我们知道 a 的前缀表是 -1 也就是一个空的字符串,我们将空的字符串对准匹配失败的位置,等同于-1就是整体右移一位
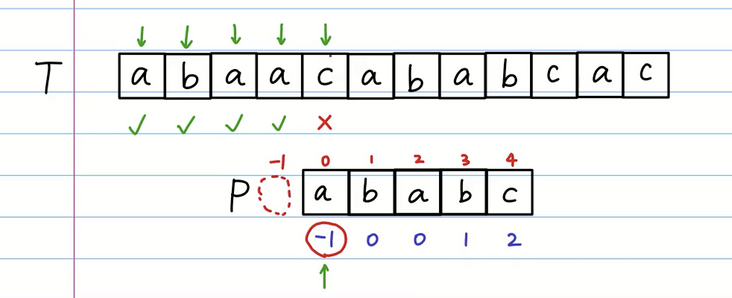
这个时候我们继续进行匹配,发现已经匹配成功了!
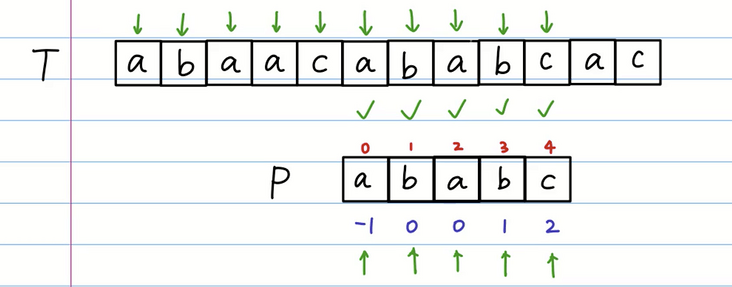
暴力搜索和KMP区别
举一个例子:

如果我们使用暴力搜索的话我们会发现我们需要将 P 字符串一直后移一位,需要四次后移才可匹配成功。
如果我们使用KMP来解决的话,还是首先我们需要知道前缀表是多少,如下图:
 aaaab-10123
aaaab-10123
然后我们进行比对。
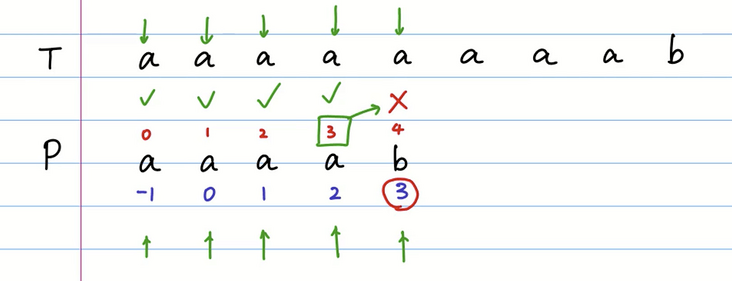
前缀表为3匹配失败,将数组下标为3移动至此,继续进行对比。

需要注意的是,我们不需要再重头开始对比,只需要从下标为3的位置开始匹配即可
后面其实就是大同小异,继续后移匹配即可。
总结
由此我们可以知道,暴力搜索每次移动后都要从第一位开始重新匹配,而我们用KMP的话我们不需要再重头开始对比可以省去大量时间。
Java代码实现KMP算法
使用Java代码如何先得到前缀表。private static void buildPrefixTable(char[] pattern, int[] prefix) {
// 对比指针下标
int len = 0;
// 第一位不需要进行比对因为肯定是0
prefix[0] = 0;
//因为第一位不需要进行比对,我们从1开始
int i = 1;
//最后一位不需要比较因为我们需要的前缀表是比原始字符串短
int length = prefix.length -1;
while (i < length) {
if (pattern[i] == pattern[len]) {
//匹配成功,自增继续匹配下一位字符
len++;
prefix[i] = len;
i++;
} else {
if (len > 0) {
//获得前一位的前缀
len = prefix[len - 1];
} else {
//没有找到只能是0,i++继续匹配下一位
prefix[i] = len;
i++;
}
}
}
//整体后移一位,将第一位修改为-1
for (int j = prefix.length - 1; j > 0; j--) {
prefix[j] = prefix[j - 1];
}
prefix[0] = -1;
}
整体逻辑代码如下:public static void main(String[] args) {
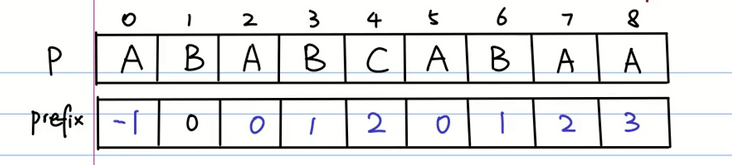
String T = "ABABABCABAABABABAB";
String P = "ABABCABAA";
char[] text = T.toCharArray();
char[] pattern = P.toCharArray();
kmpSearch(text, pattern);
}
private static void kmpSearch(char[] text, char[] pattern) {
int m = text.length;
int n = pattern.length;
int[] prefix = new int[n];
buildPrefixTable(pattern, prefix);
// 字符串 text 的指针下标
int i = 0;
// 字符串 pattern 的指针下标
int j = 0;
while (i < m) {
if (j == n - 1 && text[i] == pattern[j]) {
System.out.println("找到了!开始下标为:" + (i - j));
j = prefix[j];
//如果未比较的pattern长度已超出text剩下的长度则提前结束
if (n - j > m - i) {
break;
}
}
if (text[i] == pattern[j]) {
//相同的话自增匹配下一位
i++;
j++;
} else {
//不同的话就将前缀值当下标进行整体移动
j = prefix[j];
if (j == -1) {
//如果值为-1则说明需要整体后移一位进行匹配
i++;
j++;
}
}
}
}
/**
* 构建前缀表
*/
private static void buildPrefixTable(char[] pattern, int[] prefix) {
// 对比指针下标
int len = 0;
// 第一位不需要进行比对因为肯定是0
prefix[0] = 0;
//因为第一位不需要进行比对,我们从1开始
int i = 1;
//最后一位不需要比较因为我们需要的前缀表是比原始字符串短
int length = prefix.length -1;
while (i < length) {
if (pattern[i] == pattern[len]) {
//匹配成功,自增继续匹配下一位字符
len++;
prefix[i] = len;
i++;
} else {
if (len > 0) {
//获得前一位的前缀
len = prefix[len - 1];
} else {
//没有找到只能是0,i++继续匹配下一位
prefix[i] = len;
i++;
}
}
}
//整体后移一位,将第一位修改为-1
for (int j = length; j > 0; j--) {
prefix[j] = prefix[j - 1];
}
prefix[0] = -1;
System.out.println("前缀表为:"+Arrays.toString(prefix));
}
输出结果:前缀表为:[-1, 0, 0, 1, 2, 0, 1, 2, 3]
找到了!开始下标为:2














 7998
7998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









