






这是我本学期的第二份pattern recognition作业,现在已经考完了,有时间把这些内容传上来...
实验原理:
1、求两类样品均值:![]() , i=1,2
, i=1,2
2、求两类样品类内离散度矩阵以及总类间离散度矩阵:![]() i=1,2 和
i=1,2 和 ![]()
3、求向量:![]() ,该向量使得Fisher准则函数取得最大值的向量
,该向量使得Fisher准则函数取得最大值的向量
4、将训练集内所有样品进行投影:![]()
5、求各类样品均值:![]()
6、选取并计算阈值:![]()
7、对于位置样品X,计算他在上的投影点y:![]()
8、根据决策规则分类:![]() 或者公
或者公![]()
程序流程图:
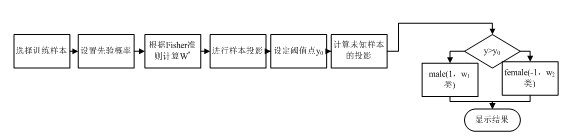
实验结果及分析:
本次实验采用的分类器方法为:Fisher和基于概率密度的Bayesian,训练样本集:Female.txt(已用-1标注性别)和Male.txt(已用1标注性别),未知样本集:test1.txt和test2.txt,其中未知样本集的性别用”-1”表示女性,”1”表示男性。下表3-1、3-2为实验结果:
表3-1条件:未知样本集为test1.txt
| 男女先验概率 | Fisher分类器 | Bayesian分类器 |
| 0.9vs0.1 | 0.17143 | 0.25714 |
| 0.7vs0.3 | 0.085714 | 0.2 |
| 0.5vs0.5 | 0.028571 | 0.14286 |
| 0.3vs0.7 | 0.057143 | 0.11429 |
| 0.1vs0.9 | 0.25714 | 0.22857 |
表3-2条件:未知样本集为test2.txt
| 男女先验概率 | Fisher分类器 | Bayesian分类器 |
| 0.9vs0.1 | 0.063333 | 0.12667 |
| 0.7vs0.3 | 0.086667 | 0.10667 |
| 0.5vs0.5 | 0.11667 | 0.083333 |
| 0.3vs0.7 | 0.15333 | 0.14667 |
| 0.1vs0.9 | 0.4 | 0.30667 |
由表3-1可以得知,Fisher分类器的错误明显低于Bayesian分类器,尤其在0.7和0.3、0.5和0.5、0.3和0.7这几组先验概率的条件下,Fisher分类器的准确率达到90%以上。
由表3-2可以得知,Fisher分类器在0.9和0.1、0.7和0.3两组条件下,Fisher分类器的错误率明显低于Bayesian分类器,达到90%以上,而在0.5和0.5、0.3和0.7、0.1和0.9三组条件下,Fisher分类器的错误率明显大于Bayesian分类器,甚至在0.1和0.9的情况下,Fisher分类器的错误高达40%。
体会:
根据实验数据以及未知样本的分布情况,我个人认为造成Fisher分类器错误率高于Bayesian分类器的原因是由于如果未知样本中大量的样本均为男性,并且男性的先验概率不高于女性的先验概率。而两个表中的十组数据也能很好的支持我的推测,只有在以上原因成立的条件下,Fisher分类器的效果才会低于Bayesian分类器,而一般情况下,Fisher分类器的正确率都在80%以上,甚至超过90%。可见Fisher分类器的效果要好于Bayesian分类器。
此次程序还使用了matlab中的plot函数,通过使用该函数能使得原本抽象的数据图变得更为直观,把样本分布和出错样本都能在图中很好的表示出来。
程序运行截图:
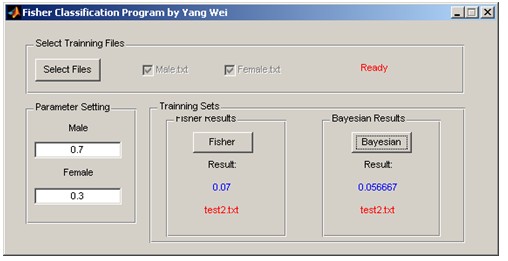
程序部分代码:
- if isempty(get(handles.Female_Parameter_edit,'String')) || isempty(get(handles.Male_Parameter_edit,'String'))
- errordlg('Please input the parameter of Male and Female!','Parameter Error');
- return;
- end
- % Read Files
- [Filename Pathname] = uigetfile({'*.txt','Text Files(*.txt)'},'Choose a test file');
- str = [Pathname Filename];
- set(handles.Fisher_File_text,'string',Filename);
- testfile = fopen(str,'r');
- counter = 1;
- while feof(testfile) == 0
- str = fgetl(testfile);
- [str1 str2 str3] = strread(str,'%s %s %s','delimiter',' ');
- Test_File(counter) = [str1 str2 str3];
- counter = counter+1;
- end
- female = handles.female;
- male = handles.male;
- female = female(:,1:2);
- male = male(:,1:2);
- test = dlmread(Filename);
- [length, width] = size(test);
- %Read the value of Pw for male and female
- p_male = str2num(get(handles.Male_Parameter_edit,'String'));
- p_female = str2num(get(handles.Female_Parameter_edit,'String'));
- %%%%%%%%%%%%%%%Fisher training Computing%%%%%%%%%%%%%%%%%%%%%%
- %1.Compute the mean value of samples, M1, M2;
- M1 = mean(male);
- M2 = mean(female);
- train_X1 = male';
- train_X2 = female';
- %2.Compute the matrix of samples, Si, Sw;
- S1 = zeros(2);
- S2 = zeros(2);
- for i = 1:50
- S1 = S1+(train_X1(:,i)'-M1)'*(train_X1(:,i)'-M1);
- S2 = S2+(train_X2(:,i)'-M2)'*(train_X2(:,i)'-M2);
- end
- %Read the value of Pw1 and Pw2
- P = [p_male p_female];
- Sw = P(1)*S1+P(2)*S2;
- %3.Compute the vaule of the projection line, W;
- W = (M1-M2)*inv(Sw);
- %4.Compute the projection of samples, y and the mean value of y, my1,my2;
- my1 = 0;
- my2 = 0;
- N1 = 50;
- N2 = 50;
- for i = 1:100
- if i <= 50
- y(i) = W*train_X1(:,i); %the projection
- my1 = my1+y(i);
- else
- y(i) = W*train_X2(:,(i-50));
- my2 = my2+y(i);
- end
- end
- my1 = my1/N1;
- my2 = my2/N2;
- %setting the thresholding of y0;
- %the formulation: y0=[(my1+my2)/2-ln(Pw1/Pw2)/(N1+N2-2)];
- Pw1 = p_male;
- Pw2 = p_female;
- y0 = [(my1+my2)/2-log(Pw1/Pw2)/(N1+N2-2)];
- %%%%%%%%%%%%%%%%%%%%%Fisher training set end%%%%%%%%%%%%%%%%%%%%%%%%%%%%
- %%%%%%%%%%%%%%%Testing the sets by trained data%%%%%%%%%%%%%%%%%%%%%%%%%
- text_X = (test(:,1:2))';
- E=[0 0];
- %male_num = 0;
- %female_num = 0;
- figure('Name','Fisher Figure','NumberTitle','off');
- for i = 1:length
- %%%%%Draw the point of samples
- Y = (test(:,1:2))';
- if test(i,3) == 1
- plot(Y(1,i),Y(2,i),'r+');
- axis([150 195 0 140]);
- hold on;
- else
- plot(Y(1,i),Y(2,i),'kx');
- hold on;
- end
- %%%%%Draw done
- g = W*text_X(:,i)-y0;
- if test(i,3)*g < 0
- if test(i,3) == 1
- E(1)=E(1)+1; %It means the error during the classification for male
- %male_num = male_num + 1;
- plot(Y(1,i),Y(2,i),'bO');
- hold on;
- else
- E(2)=E(2)+1; %It means the error during the classification for female
- %female_num = female_num + 1;
- plot(Y(1,i),Y(2,i),'bO');
- hold on;
- end
- end
- end
- %error_male = E(1)/male_num;
- %error_female = E(2)/female_num;
- error=(E(1)+E(2))/length;
- set(handles.Fisher_Result_text,'string',num2str(error)); %Output the total error during the classification by Fisher method
- hold off;
总结:
这次的程序是最后一份课程作业,这门课对我的启发很大,随后我会自己再继续好好学一下,做些小东西并总结地发上来。















 2166
2166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









