






参考资料:https://help.salesforce.com/articleView?id=managing_duplicates_overview.htm
Salesforce 很重要的一个平台是Sales Cloud,涉及到的流程是Lead-Cash。销售团队跟进潜在的客户,争取让他们变成自己的客户并创造机会购买他们的产品。有时,销售人员可能会电话或者其他方式联系不属于他own的Account或者Lead,由于系统中存在着重复的Account/Lead数据,导致销售人员做了很多无用功,同时被电联的客户也会被浪费时间以及认为公司团队办事混乱。所以重复的数据造成的影响特别大,针对这种重复数据的管理也特别有必要。
Salesforce提供了一套针对针对Duplicate数据的管理方式,Duplicate Management可用于以下的object的数据: Account(business & person) / Contact / Lead / 自定义对象。Sales force针对重复数据的管理基于两个Rule: Matching Rule & Duplicate Rule。
通过下面的截图可以看到, Matching rule是用来识别两条记录是否是重复数据的,当我们用Matching Rule确定是否重复以后,通过Duplicate Rule的配置方式来进行后续的操作。

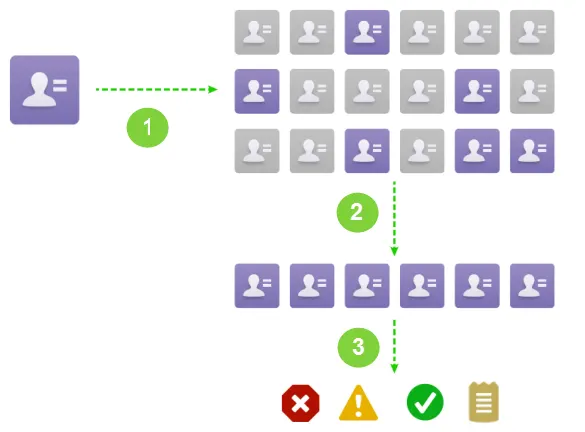
当我们进行一条Contact插入时,Duplicate Management会进行以下的步骤:
1. 一个Contact 创建;
2. 通过Matching Rule规则去查看有哪些匹配到的重复的Contact数据;
3. 通过不同的Duplicate Rule会有不同的操作,比如可以block住创建的操作,也可以弹出alert提示框然后允许其继续创建,针对继续创建也可以做到将潜在的重复记录生成report发送给他的经理邮件。下面分别讲一下Matching Rule以及Duplicate Rule的使用。
Mattching Rule 以及 Duplicate Rule可在Set Up中搜索Duplicate,在Duplicate Management下进行访问,下面针对这两个规则进行详细的说明。
一. Matching Rule
Salesforce默认提供了关于Account / Contact / Lead的标准的Matching Rule,针对这三种Matching Rule的详细使用如下链接所示:
Account Standard Matching Rule:https://help.salesforce.com/articleView?id=matching_rules_standard_account_rule.htm&type=0
Contact Standard Matching Rule:https://help.salesforce.com/articleView?err=1&id=matching_rules_standard_contact_rule.htm&type=5
Lead Standard Matching Rule: https://help.salesforce.com/articleView?err=1&id=matching_rules_standard_leads_on_accounts_rule.htm&type=5
我们下面的内容讲的是如何创建自定义的Matching Rule,以及创建好以后如何判断两条记录是Matching的还是不同的。
1. 首先我们在系统中新建一个Matching Rule,管理员需要设置Matching Criteria。我们在demo中设置了4列,并且设置他们的逻辑为(1 OR 2) AND (3 OR 4).
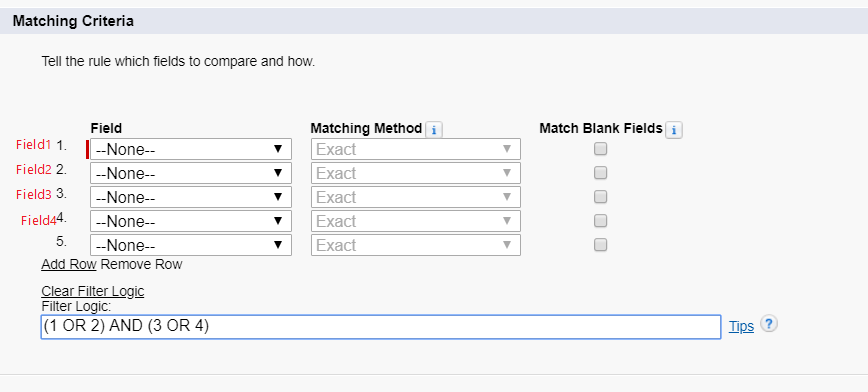
通过上图自定义Matching Rule我们可以看到Matching Criteria有三列,这三列的含义如下:
Field: 用来指定哪个字段用来做比较,支持的比较类型包括email, lookup relationship, master-detail relationship, number, phone, standard picklists, custom picklists (single-select only), text, and URL。
Matching Method: 定义Field如何进行比较的方法。有两种类型可供选择: Exact / Fuzzy。 Exact大部分字段都可以选择,Fuzzy针对常用的字段可以选择。针对Exact以及Fuzzy选择如何影响匹配规则会在下面说明。
Match Blank Fields: 指定在字段比较时,空字符串是否被用于比较。如果没有勾选,则如果两条记录的比较的字段都是空的也会被认为是不一致的。如果勾选的情况下,如果两个记录的比较的字段均为空,则认为是一致,如果一个为空,一个不为空也不认为是一致的。
当我们选择了上面的逻辑进行操作以后,Salesforce适用了一系列的运算逻辑和运算算法来实现匹配。这里涉及到几个关键的概念。
1. Matching equation:
我们在Matching Criteria 选择了字段以及匹配了规则以后,我们便知道了 Matching equation。通过下图可以知道,当前的匹配规则为:
(Field1 OR Field2) & (Field3 OR Field4)。Matching Equation知道以后,我们需要变形,括号内适用AND链接,括号外适用OR链接。
所以 (Field1 OR Field2)AND (Field3 OR Field4) =
(Field1 AND Field3) OR
(Field1 AND Field4) OR
(Field2 AND Field3) OR
(Field2 AND Field4)
我们通过解析成OR的形式便可以知道当前的 matching key的个数,即一个OR的group对应一个 matching key. demo中总共有4个matching key
matching key 由两部分进行自动生成,一个是matching equation,一个是matching method(exact/fuzzy)。当Matching Rule运行时,实际上是根据matching key是否匹配来判断两条数据是否为重复数据,如果matching key匹配,则认为是潜在的匹配数据进行评估,如果matching key不匹配,则认为两条数据不是重复数据。
上面的matching equation已经可以通过Matching Criteria确定出来,matching method可以由管理员勾选选项确定下来。matching method两种方式的详细区别以及用途如下:
exact:顾名思义,精确匹配,用来匹配字符串完全一样的信息。如果你使用的是国际化的数据,建议使用exact模式,大部分字段都支持此种类型匹配,包括自定义字段;
fuzzy: 模糊匹配,寻找与目标字符串近乎匹配的字符串。此种方式匹配不是所有的字段都可以使用,通常用户Account/Contact/Lead的标准字段。
看到上面的两个声明方式,可以看到exact需要完全匹配,fuzzy可以模糊匹配,那针对匹配两个值的准确率是多少,运用什么规则匹配,我们还要针对fuzzy方式提出另外几个概念。
2. Matching Algorithm
定义两个字段是否匹配的逻辑的算法。针对exact模式,则自动使用精确匹配的算法。针对模糊匹配的算法,官方提供了各种模糊匹配的算法。每个字段都是根据匹配程度来评分,用来记录当前的两个字段的匹配分值。针对fuzzy方式可能会有各种评分的匹配值,针对exact只有0和100。Salesforce提供了以下的匹配算法,各个匹配算法描述如下所示。
| MATCHING ALGORITHM | DESCRIPTION |
| Acronym | 判断一个公司的名称是否和他的缩写名称一致。比如上面例子中的International Business Machines和IBM会被认为是一致的。 |
| Edit Distance | 通过两个字符串之间的删除,添加,字符的替换来决定两个字符串的相似度。比如 VP Sales 和 VP Of Sales匹配分数为73% |
| Initials | 比较两个名字的首字母是否相同。比如First Name: Jane 和首字母为J的匹配相似度为100. 需要注意的一点是,如果我们在match rule中配置了First Name为 Fuzzy方式的匹配,设置Last Name为Exact方式的匹配,则我们的match key应该是First Name的首字母加上First Name的最后一个字母加上Last Name全部作为match key。比如Jane Smith,Jane作为First Name使用了Fuzzy方式,Smith作为Last Name使用了Exact方式。则匹配的key应该为 jesmith. |
| Jaro-Winkler Distance | 比较一个字符串转换成另外一个字符串所需要的替换的数量的相似度。通常用于短的字符串的比较。比如Johnny和Johny匹配分数为97 |
| Keyboard Distance | 比较一个字符串通过删除,添加,字符替换转换成另外一个字符串的(由键盘的键的位置加权)来确定两个字符串的相似度。 |
| Kullback Liebler Distance | 根据两个字段中的相同的单词所占的比例来确定相似度。比如Director of Engineering 和 Engineering Director 有2个单词匹配,匹配分数为65% |
| Metaphone 3 | 根据两个字符串发音来确定两个单词的相似度,这个针对First Name和Last Name都有效。比如Joseph和Josef两个单词发音一样,所以匹配程度为100. |
| Name Variant | 根据两个单词是否为相互之间的变形来确定两个单词的相似度,官方给的单词为Bob是Robert的变形,所以返回100, Bob不是Bill的变形,所以返回0 |
| Syllable Alignment | 根据两个单词的发音来确定两个单词的相似度,首先先将单词转换成音节的字符串,然后使用Edit Distance algorithm比较相似度。 |
3. Threshold
当我们使用了Fuzzy的匹配方法以后,我们需要知道针对每个字段的匹配相似度最低在多少情况下,salesforce才认为是匹配的。下面的表例举了针对Fuzzy的各个标准字段适用的匹配算法以及匹配的权重的最小值。
| Matching Method | MATCHING ALGORITHMS | SCORING METHOD | THRESHOLD | SPECIAL HANDLING |
| Exact | Exact | |||
| Fuzzy: First Name | Exact Initials Jaro-Winkler Name Variant | Maximum | 85 | 如果Middle Name字段用来作为matching rule的比较字段,则根据Fuzzy:First Name matching method比较 |
| Fuzzy: Last Name | Exact Keyboard Distance Metaphone 3 | Maximum | 90 | |
| Fuzzy: Company Name | Acronym Exact Syllable Alignment | Maximum | 70 | 在比较字段以前需要先移除inc, corp等词。除此之外,公司名称也遵循规范化的。比如IBM会先规范化成International Business Machines |
| Fuzzy: Phone | Exact | Weighted Average | 80 | 电话号码会分成多个部分进行比较。每个部分都有自己的匹配方法和匹配分数。部分分数经过加权后得出该字段的一个分数。这个计算过程最适合北美的数据。 International code (exact, 10% of field’s match score) 当我们比较这两个号码:1-415-555-1234 and 1-415-555-5678. 1 1 415 415 555 555 1234 5678 前三个部分都匹配,最后一个不匹配,最后一个占的权重为90%超过了80,所以我们认为这两个号码是匹配的。 |
| Fuzzy: City | Edit Distance Exact | Maximum | 85 | |
| Fuzzy: Street | Exact | Weighted Average | 80 | 街道字段的比较方式和上面的电话号码类似,差分成多个比较,不同模块会有不同的权重。这个也是最适合北美的数据。 |
| Fuzzy: ZIP | Exact | Weighted Average | 80 | ZIP code也拆分成多个模块比较 First five digits (Exact, 90% of field’s match score) Next four digits (Exact, 10% of field’s match score) 因为前5个匹配便已经90超过80,所以前5位匹配即认为相同 |
| Fuzzy: Title | Acronym Exact Kullback-Liebler Distance | Maximum | 50 |
4. Matching Key
上文也提到了,我们在有了Matching equation 以后,需要变形成指定的格式,目的就是为了生成 Matching Key。Matching Key有助于提高匹配算法的性能。我们可以根据生成的Matching Key来比较两个字段的相似度,从而可以知道权重是否满足在salesforce规定的范围内。那Matching Key需要如何生成?有哪些要求?
1. 将匹配的方程式从 OR语句格式转换成AND语句格式
2. 匹配规则中的字段的值是规范化的
3. 一个matching rule最多只能有10个matching key,也就是说OR语句转成AND后的数量必须在10个以内,否则会报错。
4. match key用于针对每条记录将规范化的值组合。
第一个我们在前面已经了解了,第二个规范化有什么意义?salesforce又是如何设计的?
意义: 在我们比较两个字段相似度时,不同的字段类型,不同销售人员填的内容可能是不一样的。比如针对名称,可能有些人添加了称呼语(Mr./Mrs),针对公司名称,有些人可能填写的时缩写,有些人可能在名称中添加了 and,the这种连接词等,大大的增加了匹配的难度以及准确性,所以针对部分字段,我们将其按照某种规则在比较以前进行规范化,可以大幅度的增强匹配的准确性以及匹配的效率。
salesforce针对主要字段的规范化如下表所示:
| FIELD | NORMALIZATION DETAILS | APPLIES TO STANDARD AND CUSTOM MATCHING RULES? | EXAMPLES |
| City | 将所有字符小写。删除非字母和非数字字符,包括空格也要删掉。最多保留6位字符 | 如果适用自定义Match Rule,City的match method需要是fuzzy | San Francisco = sanfra 首先先将空格去掉,然后全部小写,最后保留前6个字符串 Rome = rome 如果不到6位的字符串则完全保留 |
| Company | 针对缩写的公司名称先变成全称,将所有的字符小写,删除后缀字符串,比如Corporation, Incorporated, Inc, Limited, and Ltd等。移除and, the , of这种单词。移除特殊字符和accent. | 同上。 | IBM = international business machines Intel Corp. = intel |
| First Name | 如果适用的情况下,将名字替换成别名。移除dear,sir这种称呼语,移除特殊字符。只保留第一个单词的第一个字母并且将字母小写。 | 同上。 | Dr. Jane = j Dr是称呼语,所以删掉,Jane的首字母是J小写以后为j Mr. Bob= robert = r Mr是称呼语,Bob是robert的变形,可以理解成别名,所以Bot替换成Robert首字母为R小写成r |
| Last Name | 删除特殊字符和后缀,将连续的相同的辅音字母替换成单个的辅音字母(b,c,d,f等)。将第一个字母小写。在上述操作标准化以后,使用双变音算法(double metaphone)用来规避拼写错误和拼写变体情况。 | 同上。 | O’Reilly, Jr. = oreily (without double metaphone) O’Reilly, Jr. = oreily = arl (with double metaphone) |
| 删除部分字符串。例如下划线和点(.),保留@字符串 | 只适用于标准的Match Rule | john.doe@us.salesforce.com = johndoe@salesforcecom | |
| Phone | 删除所有的非字母和非数字字符,针对美国的电话号码,将字母字符转换成数字字符并删除国际电码。删除后4位小数。 | 如果适用自定义的Phone,match method需要Fuzzy | 1-800-555-1234 = 800555 44 20 0540 0202 = 44200540 |
| Street Address | 删除所有的字符除了连接符。删除所有的禁用词,比如Avenue和Street等。取前两个单词(token)的前5个字符串 | 同上 | 123 Ocean View Avenue = 123ocean 567 Fifty-fourth St. = 567fifty |
| Website | 删除协议名称(http/https),删除子域(www),删除文件路径。取2个或者3个的单词(token) | 只适用于标准的Match Rule | http://www.us.salesforce.com/product = salesforce.com http://www.ox.ac.uk/ = ox.ac.uk |
当我们规范化完以后,我们将根据规则来确定哪些字段和哪些字符串用于match key里面。
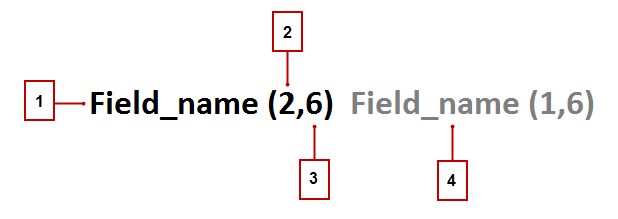
1代表在match key里面的字段。
2代表在match key里面的单词或者token的数量,没有单词数量则所有单词全添加。
3代表在match key里面的单词的字符数,没有单词则字符全算。
4代表着在match key里面的其他的字段。
下面可以通过1个例子直观的展示match key如何操作以及如何生成。
| FIELDS | Matching Method | Match Blank Fields |
| Company | Fuzzy(Company) | Yes |
| Exact | Yes | |
| Phone | Fuzzy(Phone) | Yes |
Matching equation为(Company OR Email) ANDPhone这边有两条数据:
| Company | Phone | |
| Elite Sport | john.doe@elitesport.com | 1-415-555-1235 |
| Elite Sports | john.doe@elitesport.com | 1-415-555-1234 |
第一步,转换成AND模式: (Company OR Email) AND Phone = (Company AND Phone) OR (Email AND Phone)第二步,规范化需要匹配的字段的值。针对第一条:company: Elite Sport -> elite sportEmail: johndoe@elitesport.comPhone: 415555针对第二条:company: Elites Sports -> elites sportEmail: johndoe@elitesport.com
Phone: 415555
第三步,生成matching key.
针对第一条会生成两个matching key
Company(2,5) Phone = elitesport415555
Email Phone = johndoe@elitesport.com415555
针对第二条会生成两个matching key
Company(2,6) Phone = elitessport415555
Email Phone = johndoe@elitesport.com415555
这两条数据尽管第一个key不完全匹配,但是第二个匹配,salesforce会认为这两条时潜在的重复数据。
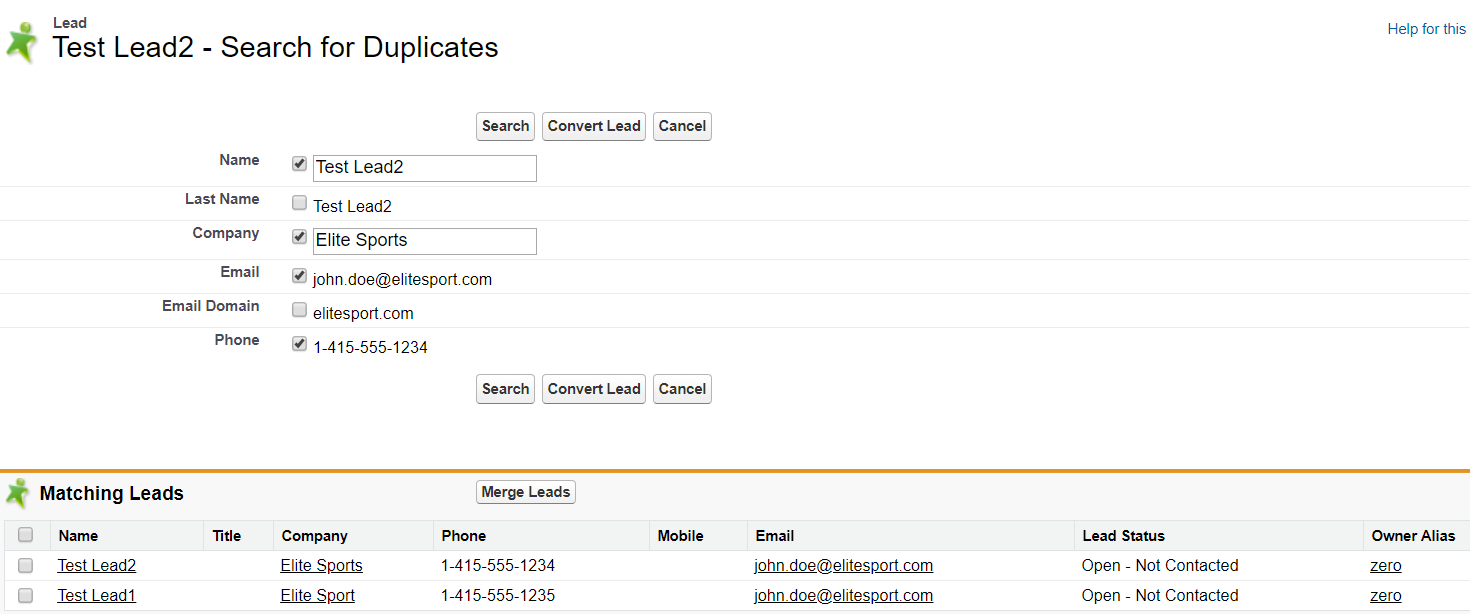
二. Duplicate Rule
我们第一步用了大量的内容去描述Matching Rule的规则,其实Matching Rule一大部分作用是为了Duplicate Rule去服务。用户更关心的是如果出现了Duplicate 数据要如何去处理。我们可以配置自定义的Duplicate Rule去配置给用户关于重复数据的后续处理方式。
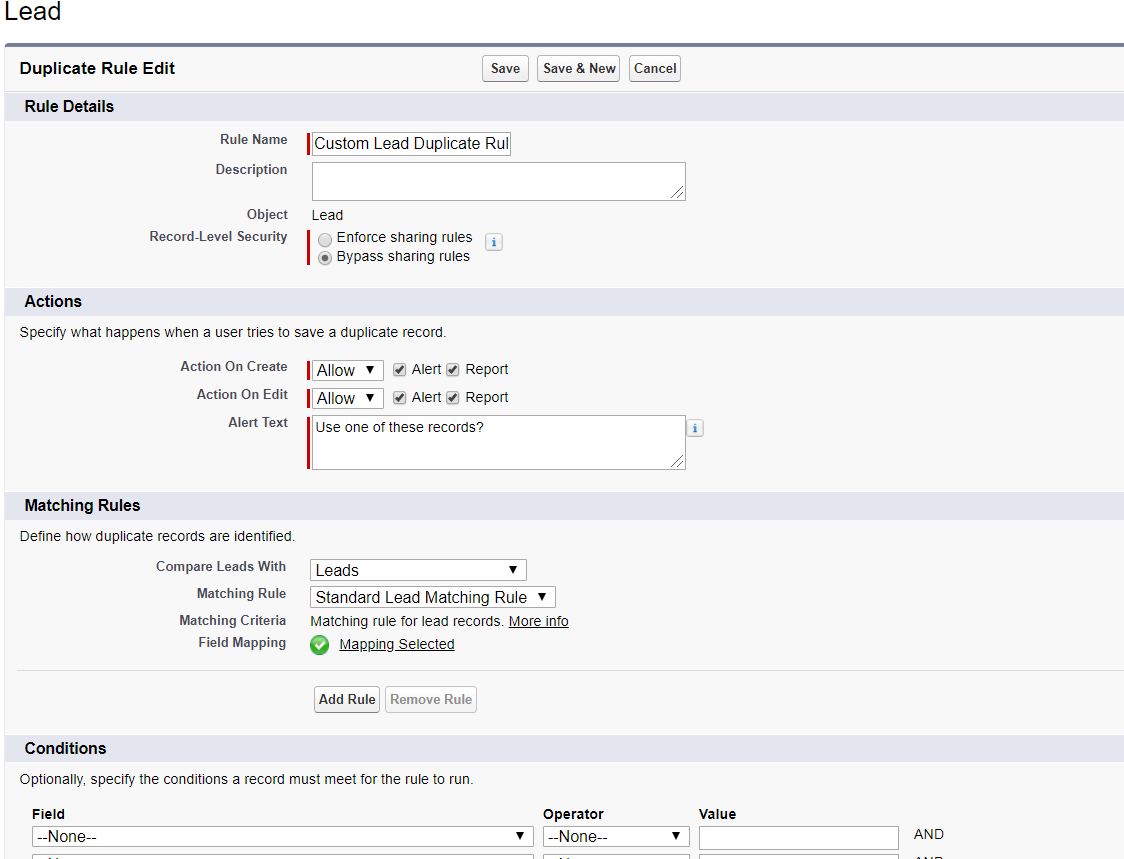
从下图中我们可以看到Duplicate Rule配置时可以控制的选项。
1. Record Level Security: matching rule比较的范围,是比较当前用户有权限的记录还是所有的记录;
2. Action区域可以选择用户基于Create / Edit操作时,针对Duplicate是要block创建还是在提出信息情况下允许创建并且允许report;
3.Matching Rules选择我们如何来确定两条数据时matching的;
4. Conditions可以限制某些条件下才执行当前的Duplicate Rule,比如某些profile或者某些role才需要执行。
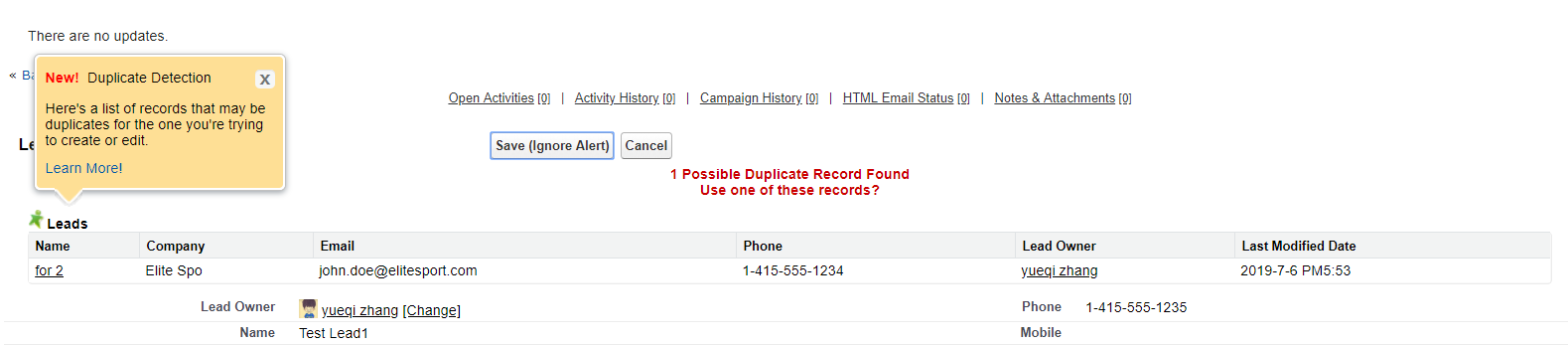
效果展示:当我们active 针对lead的duplicate rule以后,修改了 lead1的数据,会提示以下的内容告诉你有重复的数据。
总结:本篇浅入浅出的讲了以下salesforce中关于Duplicate的数据的管理方式。关于Matching Rule / Duplicate Rule的相关的limitation以及深层次的用法没有涉及。感兴趣的可以自行查看。篇中有错误的地方欢迎指出,有问题欢迎留言。















 3836
3836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









