






一、完整的一致性模型
完整的一致性模型如下图所示。
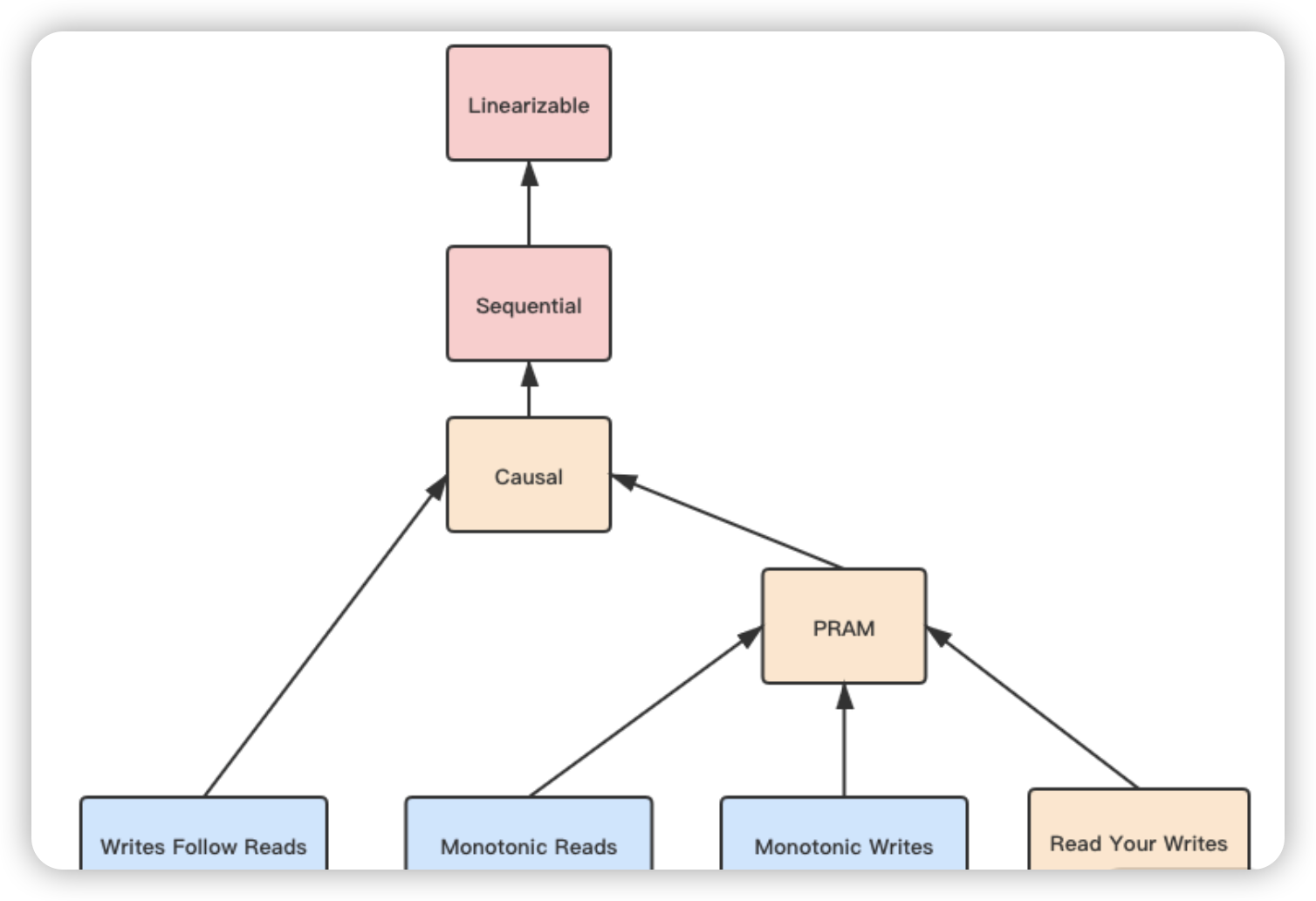
图中不同的颜色代表了可用性的程度
-
1、粉色代表网络分区后完全不可用。也就是 CP 类的数据库。
-
2、黄色代表严格可用。当客户端一直访问同一个数据库节点,那么遭遇网络分区时,在该一致性下依然是可用的。它在数据端或服务端,被认为是 AP 数据库;而从客户端的角度被认为是 CP 数据库。
-
3、蓝色代表完全可用。可以看到其中全都是客户端一致性,所以它们一般被认为是 AP 数据库。
我们看到图中从上到下代表一致性程度在降低。
二、客户端一致性
客户端一致性是站在一个客户端的角度来观察系统的一致性。我们之前是从“顺序性”维度来研究一致性的,因为它们关注的是多个节点间的数据一致性问题。而如果只从一个客户端出发,我们只需要研究“延迟性”。
分布式数据库中,一个节点很可能同时连接到多个副本中,复制的延迟性会造成它从不同副本读取数据是不一致的。而客户端一致性就是为了定义并解决这个问题而存在的,这其中包含了写跟随读、管道随机访问存储、读到已写入、单增读和单增写。
1、写跟随读(Writes Follow Reads)
WFR 的另一个名字是回话因果(session causal)。可以看到它与因果一致的区别是,它只针对一个客户端。故你可以对比记忆,它是对于一个客户端,如果一次读取到了写入的值 V1,那么这次读取之后写入了 V2。从其他节点看,写入顺序一定是 V1、V2。
WFR 的延迟性问题可以描述为:当写入 V1 时,是允许复制延迟的。但一旦 V1 被读取,就需要认为所有副本中 V1 已经被写入了,从而保证从副本写入 V2 时的正确性。
2、管道随机访问存储(PRAM)/FIFO
管道随机访问存储的名字来源于共享内存访问模型。分布式系统借用了并发内存访问一致性的概念来解释自己的问题。后来,大家觉得这个名字很怪,故改用 FIFO,也就是先进先出,来命名分布式系统中类似的一致性。
它被描述为从一个节点发起的写入操作,其他节点与该节点的执行顺序是一致的。它与顺序一致性最大的区别是,后者是要求所有节点写入都是有一个固定顺序的;而 PRAM 只要求一个节点自己的操作有顺序,不同节点可以没有顺序。
PRAM 可以拆解为以下三种一致性。
-
1、读到已写入(Read Your Write):一个节点写入数据后,在该节点或其他节点上是能读取到这个数据的。
-
2、单增读(Monotonic Read):它强调一个值被读取出来,那么后续任何读取都会读到该值,或该值之后的值。
-
3、单增写(Monotonic Write):如果从一个节点写入两个值,它们的执行顺序是 V1、V2。那么从任何节点观察它们的执行顺序都应该是 V1、V2。
同时满足 RYW、MR 和 MW 的一致性就是 PRAM。PRAM 的实现方式一般是客户端一直连接同一个节点,因为读写同一个节点,故不存在延迟性的问题。
我们可以将 PRAM 与 WFR 进行组合,从而获得更强的因果一致。也就是一个客户端连接同一个节点,同时保持回话因果一致,就能得到一个普通的因果一致。这种模式与 05 讲中介绍的是不一样的,这次我们是采用模型递推的模式去构建一致性,目的是方便模型记忆。但这并不代表因果一致一定是这种模型化的构建方式;相反,在 05 讲中介绍的时间戳模式更为普遍。
我们刚才说到,PRAM 是严格可用的,并不是完全可用,如果要完全可用一般可以牺牲 RYW,只保留 MR 和 MW。这种场景适合写入和读取由不同的客户端发起的场景。
三、最终一致性
最终一致性是非常著名的概念。随着互联网和大型分布式系统的发展,这一概念被广泛地传播。它被表述为副本之间的数据复制完全是异步的,如果数据停止修改,那么副本之间最终会完全一致。而这个最终可能是数毫秒到数天,乃至数月,甚至是“永远”。
最终一致性具有最高的并发度,因为数据写入与读取完全不考虑别的约束条件。如果并发写入修改同一份数据,一般采用之前提到的一些并发冲突解决手段来处理,比如最后写入成功或向量时钟等。
但是,最终一致性在分布式数据库中是完全不可用的。它至少会造成各种偏序(skew)现象,比如写入数据后读取不出来,或者一会儿能读取出来,一会儿又读取不出来。因为数据库系统是底层核心系统,许多应用都构建在它上面,此种不稳定表现在分布式数据库设计中是很难被接受的。故我们经常采用可调节的最终一致性,来实现 AP 类的分布式数据库。
四、可调节一致性
一般的分布式系统的写入和读取都是针对一个节点,而可调节一致性针对最终一致性的缺点,提出我们可以同时读取多个节点。现在我们引入可调节一致性设计的三个变量。
副本数量 N:是分布式集群中总的节点数量,也就是副本总量。
最少并发写入数量 W:当一份数据同步写入该数量的节点后,我们认为该数据是写入成功的。
最少并发读取数量 R:当读取数据时,至少读取该数量的节点,比较后选择最终一份最新的数据。如此我们才认为一次读取操作是成功的。
当分布式系统的并发读写数量满足下面的公式:
W + R > N
这时我们认为该系统的并发度可以满足总是能读取到最新的数据。因为你可以发现,写入节点与读取的节点之间肯定存在重合,所以每次读取都会发现最新写入的一个节点。
一个常见的例子是 N=3、W=2 和 R=2。这个时候,系统容忍一个节点失效。正常情况下三个节点都能提供读写服务,如果其中一个节点失效,读写的最少节点数量依然可以满足。在三个节点同时工作的情况下,最新数据至少在两个节点中,所以从三个里面任意读取两个,其中至少一个节点存在最新的数据。
五、CRDT 算法
上文我们探讨了最终一致性方案,除了使用可调节手段来保持一致性外。我们可以使用 Conflict-Free Replicated Data Type(CRDT)来解决最终一致的数据冲突问题。
CAP 理论提出者 Eric Brewer 撰文回顾 CAP 时也提到,C 和 A 并不是完全互斥,建议大家使用 CRDT 来保障一致性。自此各种分布式系统和应用均开始尝试 CRDT,微软的 CosmosDB 也使用 CRDT 作为多活一致性的解决方案,而众多云厂商也使用 CRDT 来制定 Redis 的多活一致性方案。
由于目前 CRDT 算法仍然处于高速发展的阶段,为了方便你理解,我这里选取携程网内部 Redis 集群一致性方案,它的技术选型相对实用。如果你对 CRDT 有兴趣,可以进一步研究,这里就不对诸如 PN-Counter、G-Set 等做进一步说明了。
由于 Redis 最常用的处理手段是设置字符串数据,故需要使用 CRDT 中的 register 进行处理。携程团队选择了经典的 LWW Regsiter,也就是最后写入胜利的冲突处理方案。















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









