






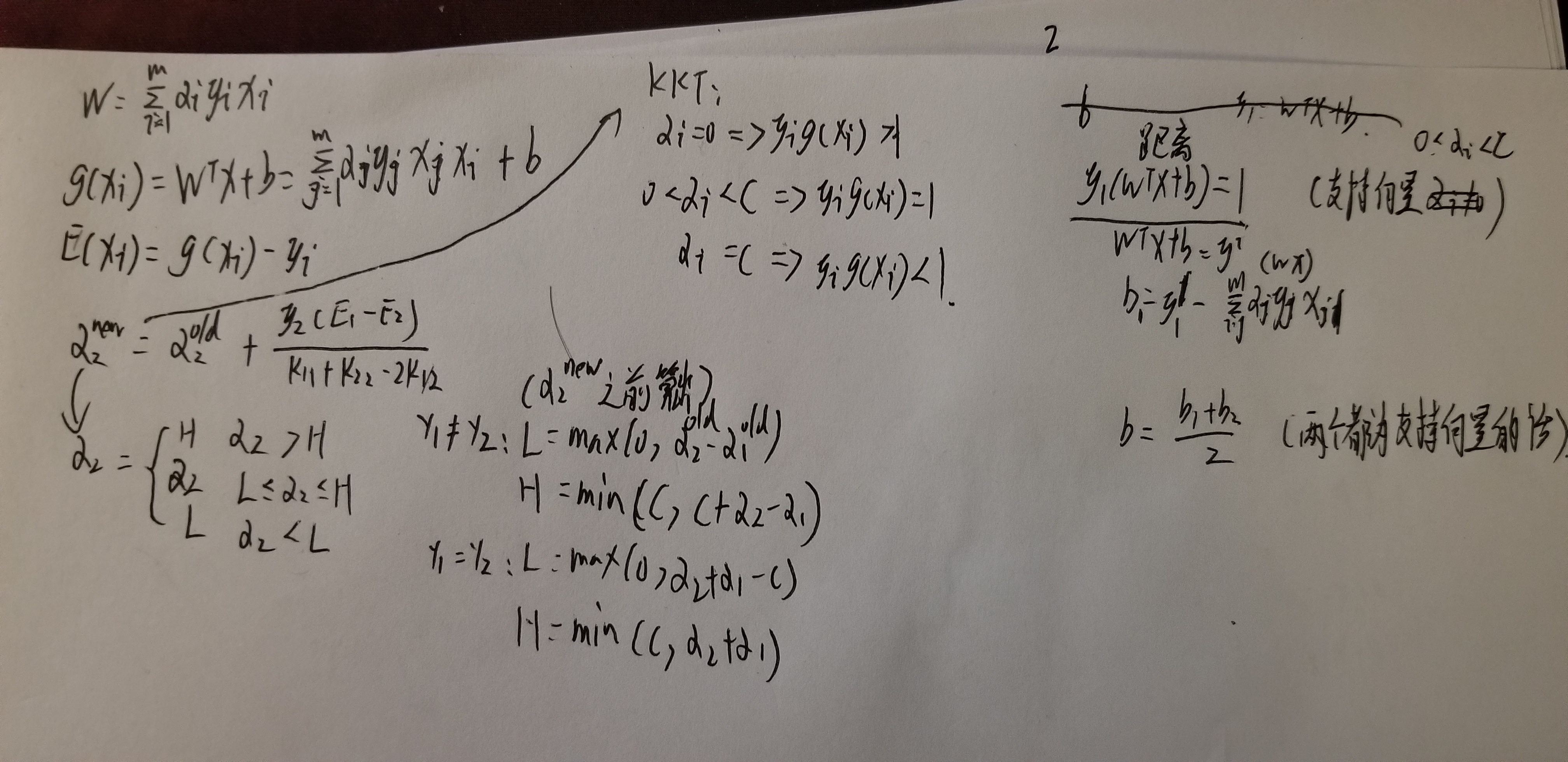
主要公式步骤:
原距离问题的函数: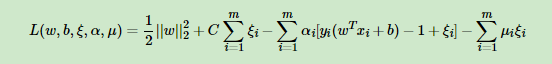
1.将SVM的距离问题转化为拉格朗日函数:
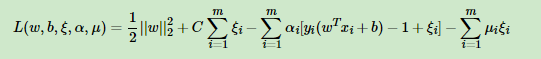
2.原函数问题化成如下问题:

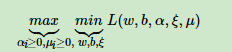
3.对各非拉格朗日参数求偏导来求min值:

4.将上面 令各偏导等于0 的结果带回 拉格朗日函数 消去非拉格朗日参数(w,b,£)
结果为: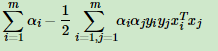
步骤:

5.用SMO算法求α:
KKT条件:
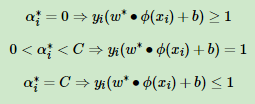
将拉格朗日函数转化为下面函数:
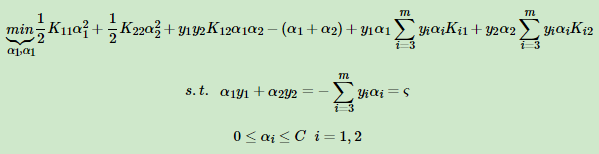
根据 α1y1+α2y2 = k(常数),可以将他们(α1,α2)替换成一个变量,且有一个范围:
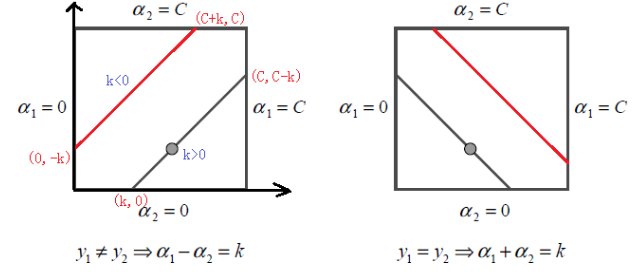
对于左边:

对于右边:
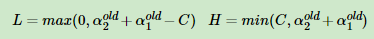
所以最小值区域:
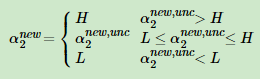
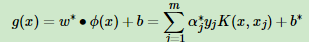

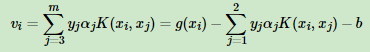
原式:
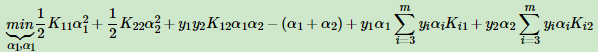
简化为:
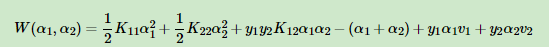
将α1转化为α2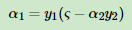
代入上面:
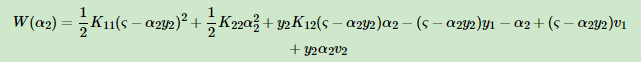
求导: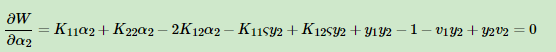

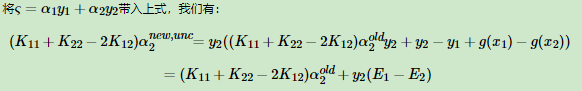
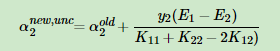
6.将α代入
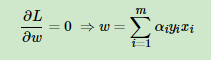
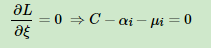 求得w,μ
求得w,μ
7.用0<α<C的样本(支持向量)求出b
变量选择:
第一个变量:
SMO算法称选择第一个变量为外层循环,这个变量需要选择在训练集中违反KKT条件最严重的样本点。对于每个样本点,要满足的KKT条件:
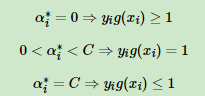
一般来说,我们首先选择违反
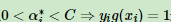 这个条件的点。
这个条件的点。
如果这些支持向量都满足KKT条件,再选择违反
 的点。
的点。
第二个变量的选择


重要参数总结图:















 1805
1805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









