







1.步骤描述:
(1)将数据转换为SVM包的格式
(2)对数据进行简单缩放
(3)考虑RBF核
(4)使用交叉验证来找出最佳参数和
(5)使用最佳参数和训练整个训练集
(6)测试
2.具体操作步骤:
(1)将数据转换为SVM包的格式
1)libSVM的数据格式:
Label 1:value 2:value ….
Label:是类别的标签,比如上1, -1,你可以自己随意定,比如-10,0,15。
Value:就是要训练的数据,从分类的角度来说就是特征值,数据之间用空格隔开。
比如: -15 1:0.708 2:1056 3:-0.3333
2)导入外部数据、格式转换:
matlab中导入外部数据,在此处不描述,参考learn svm step by step 视频等。
第一种方法 使用FormatDataLibsvm.xls
运行FormatDataLibsvm.xls(注意这时会有一个关于“宏已禁宏”的安全警示,点击“选项”,选择“启用此内容”,确定即可);
a、先运行FormatDataLibsvm.xls,然后将数据粘贴到sheet1的topleft单元。
b、 打开data.xls,(注:网上很多的介绍都是直接将数据粘贴到sheet1的topleft单元),要特别注意的是这时候的数据排列顺序应该是:
条件属性a 条件属性b ... 决策属性
7 5 ... 2
4 2 ... 1
c、"工具"-->"宏"-->执行下面有一个选项(FormatDatatoLibsvm)-->执行,要选中这个然后点击“运行” ,这时候数据讲变成:
决策属性 条件属性a 条件属性b ...
2 1:7 2:5 ...
1 1:4 2:2 ...
等数据转换完成后,将该文件保存为.txt文件。这时数据转换的问题就解决了。
第二种方法 .txt格式->svm格式的转换
首先说明的是,这里所提的.txt文本数据是指数据文件带有逗号、空格、顿号、分号等数据分离符号的数据文件。因为其用符号来分离,导致所有数据项都归类为一个属性,无法实现上面2步骤的格式输入,也就无法实现正确结果格式的输出了。
为了解决该问题,转换该过程与上面一过程的最大不同就在于:在打开该.txt文件的时候根据文本数据本身的数据特点将其所包含的逗号、分号、制表符等数据分离的符号去掉;具体的做法是:转换运行FormatDataLibsvm.xls,“文件”->“打开”->选择要打开的data,txt文件,接着在文本导入向导中根据data.txt文件本身的数据特点选择“原始数据类型(分隔符号)”;接着选择分隔符号的类型(目地是使得该数据分成独立的一列列数据,分离成功的话,在数据预览中将可以看到一列列分离独立的数据) :选择“列数据格式”(常规)->完成;
( 本段内容来自:http://blog.csdn.net/kobesdu/article/details/8944851)
(2)对数据进行简单缩放
1)svm-scale.exe的使用(一般在libsvm中的windows文件夹下)
svm-scale 对数据进行缩放的规则:
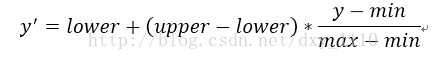
式中,y 为缩放前的数据,y' 为缩放后的数据;lower 为参数中指定的数据下界,upper 为参数中指定的数据上界;min 为全部训练数据中的最小值,max 为全部训练数据中的最大值。
cmd查看显示svm-scale的参数如下:

a.对训练集进行缩放:

上述操作是:设定数据的下限-l为-1,上限-u为1,并将缩放规则保存在range2这个文件中(range2在libsvm的windows目录下,是新生成的),将train.3的数据进行缩放,保存至train3.scale文件中。
b.对测试集进行缩放:

上述操作是:利用缩放训练集的缩放规则来对测试数据进行缩放,保存在test3.scale中。
以上操作,便完成了对训练和测试数据的缩放。都缩放至(-1,+1)。
2)将数据转换至matlab中进行操作。

上述操作是将数据集中的标签和属性分别提取出来,形成分离的矩阵。有此步骤是因为我后面是在matlab中进行模型训练等操作的。
(3)考虑RBF核:
通过-t参数的设置选择RBF核函数。其实就是默认的情况。
核函数介绍参考:http://blog.csdn.net/lqhbupt/article/details/8610443
(4)使用交叉验证来找出最佳参数C和γ(即上述参数中的c和g)
RBF内核有两个参数:C和γ。对于给定问题,我们预先并不知道C和γ如何取值是最好的,因此我们必须做好模型选择(参数搜索)的工作,以便于找准合适的参数(C,γ),使分类器可以准确地预测未知数据(即测试数据)。
k-fold交叉验证将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。
使用交叉验证时,我们建议用“网格搜索”的方法找到合适的C和γ的值。文件libsvm中tools文件夹下的grid.py是对C-SVC的参数c和γ做优选的,原理也是网格遍历。将grid.py用python(http://www.python.org)打开(不能双击,而要右键选择“Edit with IDLE”),修改svmtrain_exe和gnuplot_exe的路径为你存放这两个文件对应的路径即可。
用grid.py进行网格搜索,找到最佳C和γ,如下步骤:

下面的一大段[local].......是自动进行的搜索过程。
最后得出的结果:

最后一行其意义表示:C=512.0;γ=0.03125;交叉验证精度CV Rate = 83.9903%,这就是最优结果。
(5)使用最佳参数和训练整个训练集、测试
对libsvm中windows文件夹下的svm-train.exe进行查看如下:

查看测试时用到的svm-predict.exe如下:

由于在libsvm的matlab文件夹下的相关文件进行了编译,生成了svmtrain.mexw64,svmpredict.mexw64等文件,故这些可以当作函数在matlab中直接调用,操作。此处在matlab中进行训练、建模及测试。
接着上面(2)的matlab中的操作,进行模型建立与测试:
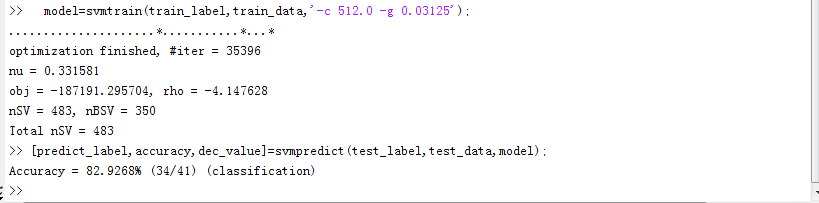
附:用easy.py自动进行分类
文件easy.py对样本文件做了“一条龙服务”,从参数优选,到文件预测。因此,其对grid.py、svm-train、svm-scale和svm-predict都进行了调用(当然还有必须的python和gnuplot)。因此,运行easy.py需要保证这些文件的路径都要正确。需要编辑对路径进行调整。
分类过程如下:
















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









