






- LSTM 是 long-short term memory 的简称, 中文叫做 长短期记忆. 是当下最流行的 RNN 形式之一
- RNN 的弊端
RNN没有长久的记忆,比如一个句子太长时开头部分可能会忘记,从而给出错误的答案。
时间远的记忆要进过长途跋涉才能抵达最后一个时间点. 然后我们得到误差, 而且在 反向传递 得到的误差的时候, 他在每一步都会 乘以一个自己的参数 W. 如果这个 W 是一个小于1 的数, 比如0.9. 这个0.9 不断乘以误差, 误差传到初始时间点也会是一个接近于零的数, 所以对于初始时刻, 误差相当于就消失了. 我们把这个问题叫做梯度消失或者梯度弥散 Gradient vanishing. 反之如果 W 是一个大于1 的数, 比如1.1 不断累乘, 则到最后变成了无穷大的数, RNN被这无穷大的数撑死了, 这种情况我们叫做梯度爆炸, Gradient exploding. 这就是普通 RNN 没有办法回忆起久远记忆的原因。 - LSTM网络

在上图中,每一行携带一个完整的向量,从一个节点的输出到另一个节点的输入。粉红的圆圈代表逐点操作,如矢量加法,而黄色的方框是学习神经网络层。行合并表示连接,而行分叉表示复制的内容以及复制到不同位置的内容。 - 核心理念
LSTM的关键是单元状态,即贯穿图顶部的水平线。单元状态有点像传送带。它沿着整个链条直行,只有一些微小的线性相互作用。信息很容易保持不变地沿着它流动。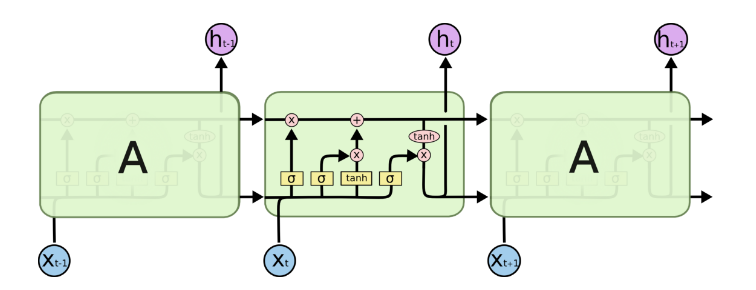
LSTM可以去除或增加单元状态的信息,并被称为门(gates)的结构仔细调控,它们由一个sigmoid神经网络层和一个逐点乘法运算组成。sigmoid输出层的输出介于0和1之间的数字,描述每个组件应该通过多少,0表示不让任何东西通过,1表示可以通过。 - 遗忘门
遗忘门(forget gate)顾名思义,是控制是否遗忘的,在LSTM中即以一定的概率控制是否遗忘上一层的隐藏细胞状态。遗忘门子结构如下图: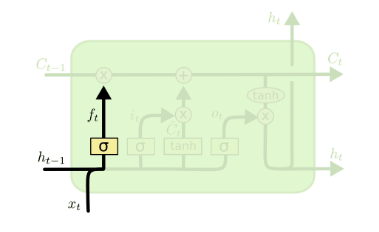
图中输入的有上一序列的隐藏状态h(t−1)和本序列数据x(t),通过一个激活函数,一般是sigmoid,得到遗忘门的输出f(t)。由于sigmoid的输出f(t)在[0,1]之间,因此这里的输出f^{(t)}代表了遗忘上一层隐藏细胞状态的概率。用数学表达式即为:f(t)=σ(Wfh(t−1)+Ufx(t)+bf)f(t)=σ(Wfh(t−1)+Ufx(t)+bf)
其中Wf,Uf,bfWf,Uf,bf为线性关系的系数和偏倚,和RNN中的类似,
Keras(五)LSTM 长短期记忆模型 原理及实例
最新推荐文章于 2023-05-18 14:04:38 发布

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1502
1502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









