






一、字符编码:
一 了解字符编码的知识储备
1. 计算机基础知识(三幅图)

2. 文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就打开了启动了一个进程,是在内存中的,所以在编辑器编写的内容也都是存放与内存中的,断电后数据丢失
因而需要保存到硬盘上,点击保存按钮,就从内存中把数据刷到了硬盘上。
在这一点上,我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
3. python解释器执行py文件的原理 ,例如python test.py
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名)
第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即执行时,才会识别python的语法,执行文件内代码,执行到name="egon",会开辟内存空间存放字符串"egon")
总结:python解释器于文件本编辑的异同
相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
不同点:文本编辑器将文件内容读入内存后,是为了显示/编辑,而python解释器将文件内容读入内存后,是为了执行(识别python语法)
二 什么是字符编码
计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字
很明显,我们平时在使用计算机时,用的都是人类能读懂的字符(用高级语言编程的结果也无非是在文件内写了一堆字符),如何能让计算机读懂人类的字符?
必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
以下两个场景下涉及到字符编码的问题:
1. 一个python文件中的内容是由一堆字符组成的(python文件未执行时)
2. python中的数据类型字符串是由一串字符组成的(python文件执行时)
三 字符编码的发展史
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符
ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符)
后来为了将拉丁文也编码进了ASCII表,将最高位也占用了
阶段二:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符
为了满足其他国家,各个国家纷纷定制了自己的编码
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
于是产生了unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言
但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)
于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes
需要强调的一点是:
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
- 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
 详解
详解
四.字符编码分类(简单了解)
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号

当然我们编程语言都用英文没问题,ASCII够用,但是在处理数据时,不同的国家有不同的语言,日本人会在自己的程序中加入日文,中国人会加入中文。
而要表示中文,单拿一个字节表表示一个汉子,是不可能表达完的(连小学生都认识两千多个汉字),解决方法只有一个,就是一个字节用>8位2进制代表,位数越多,代表的变化就多,这样,就可以尽可能多的表达出不通的汉字
所以中国人规定了自己的标准gb2312编码,规定了包含中文在内的字符->数字的对应关系。
日本人规定了自己的Shift_JIS编码
韩国人规定了自己的Euc-kr编码(另外,韩国人说,计算机是他们发明的,要求世界统一用韩国编码)
这时候问题出现了,精通18国语言的小周同学谦虚的用8国语言写了一篇文档,那么这篇文档,按照哪国的标准,都会出现乱码(因为此刻的各种标准都只是规定了自己国家的文字在内的字符跟数字的对应关系,如果单纯采用一种国家的编码格式,那么其余国家语言的文字在解析时就会出现乱码)
所以迫切需要一个世界的标准(能包含全世界的语言)于是unicode应运而生(韩国人表示不服,然后没有什么卵用)
ascii用1个字节(8位二进制)代表一个字符
unicode常用2个字节(16位二进制)代表一个字符,生僻字需要用4个字节
例:
字母x,用ascii表示是十进制的120,二进制0111 1000
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
字母x,用unicode表示二进制0000 0000 0111 1000,所以unicode兼容ascii,也兼容万国,是世界的标准
这时候乱码问题消失了,所有的文档我们都使用但是新问题出现了,如果我们的文档通篇都是英文,你用unicode会比ascii耗费多一倍的空间,在存储和传输上十分的低效
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
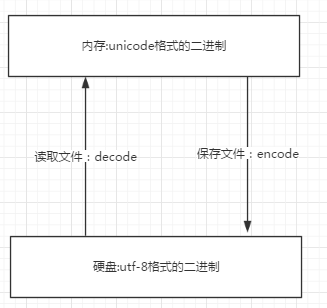
五 字符编码的使用
5.1 文本编辑器一锅端
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode
5.1.2 文本编辑器nodpad++




分析过程?什么是乱码
文件从内存刷到硬盘的操作简称存文件
文件从硬盘读到内存的操作简称读文件
乱码一:存文件时就已经乱码
存文件时,由于文件内有各个国家的文字,我们单以shiftjis去存,
本质上其他国家的文字由于在shiftjis中没有找到对应关系而导致存储失败,用open函数的write可以测试,f=open('a.txt','w',encodig='shift_jis')
f.write('你瞅啥\n何を見て\n') #'你瞅啥'因为在shiftjis中没有找到对应关系而无法保存成功,只存'何を見て\n'可以成功
但当我们用文件编辑器去存的时候,编辑器会帮我们做转换,保证中文也能用shiftjis存储(硬存,必然乱码),这就导致了,存文件阶段就已经发生乱码
此时当我们用shiftjis打开文件时,日文可以正常显示,而中文则乱码了
再或者,存文件时:
f=open('a.txt','wb')
f.write('何を見て\n'.encode('shift_jis'))
f.write('你愁啥\n'.encode('gbk'))
f.write('你愁啥\n'.encode('utf-8'))
f.close()
以任何编码打开文件a.txt都会出现其余两个无法正常显示的问题
乱码二:存文件时不乱码而读文件时乱码
存文件时用utf-8编码,保证兼容万国,不会乱码,而读文件时选择了错误的解码方式,比如gbk,则在读阶段发生乱码,读阶段发生乱码是可以解决的,选对正确的解码方式就ok了,而存文件时乱码,则是一种数据的损坏。
5.1.3 文本编辑器pycharm
以gbk格式保存

以utf-8格式打开(reload)
reload与convert的区别:
pycharm非常强大,提供了自动帮我们convert转换的功能,即将字符按照正确的格式转换
要自己探究字符编码的本质,还是不要用这个
我们选择reload,即按照某种编码重新加载文件

分析过程?
总结:
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
5.1.4 文本编辑器之python解释器
文件test.py以gbk格式保存,内容为:
x='林'
无论是
python2 test.py
还是
python3 test.py
都会报错(因为python2默认ascii,python3默认utf-8)
除非在文件开头指定#coding:gbk
5.2 程序的执行
python test.py (我再强调一遍,执行test.py的第一步,一定是先将文件内容读入到内存中)
阶段一:启动python解释器
阶段二:python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中
此时,python解释器会读取test.py的第一行内容,#coding:utf-8,来决定以什么编码格式来读入内存,这一行就是来设定python解释器这个软件的编码使用的编码格式这个编码,
可以用sys.getdefaultencoding()查看,如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的
python2中默认使用ascii,python3中默认使用utf-8


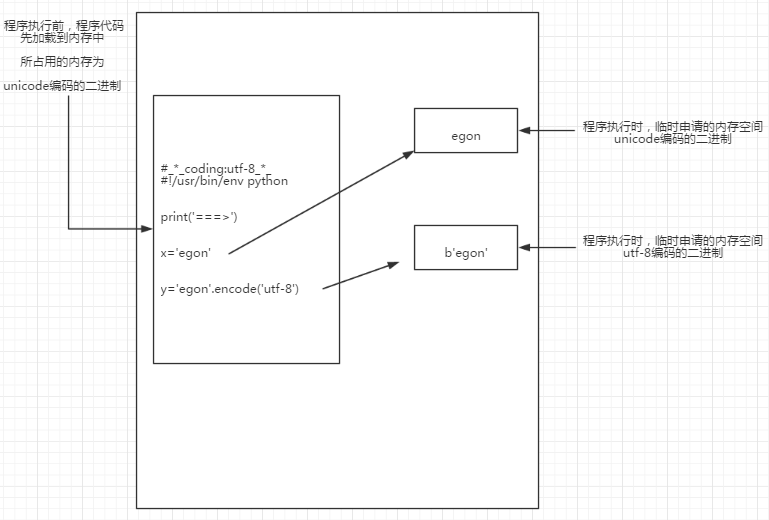
阶段三:读取已经加载到内存的代码(unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如x="egon"
内存的编码使用unicode,不代表内存中全都是unicode编码的二进制,
在程序执行之前,内存中确实都是unicode编码的二进制,比如从文件中读取了一行x="egon",其中的x,等号,引号,地位都一样,都是普通字符而已,都是以unicode编码的二进制形式存放与内存中的
但是程序在执行过程中,会申请内存(与程序代码所存在的内存是俩个空间),可以存放任意编码格式的数据,比如x="egon",会被python解释器识别为字符串,会申请内存空间来存放"hello",然后让x指向该内存地址,此时新申请的该内存地址保存也是unicode编码的egon,如果代码换成x="egon".encode('utf-8'),那么新申请的内存空间里存放的就是utf-8编码的字符串egon了
针对python3如下图
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
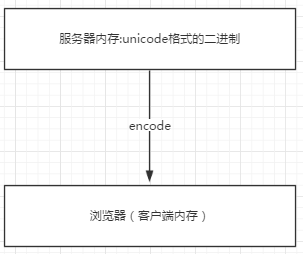
如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的二进制。
5.3 python2与python3的区别
5.3.1 在python2中有两种字符串类型str和unicode
str类型
当python解释器执行到产生字符串的代码时(例如s='林'),会申请新的内存地址,然后将'林'encode成文件开头指定的编码格式,这已经是encode之后的结果了,所以s只能decode
1 #_*_coding:gbk_*_
2 #!/usr/bin/env python
3
4 x='林'
5 # print x.encode('gbk') #报错
6 print x.decode('gbk') #结果:林
所以很重要的一点是:
在python2中,str就是编码后的结果bytes,str=bytes,所以在python2中,unicode字符编码的结果是str/bytes


#coding:utf-8
s='林' #在执行时,'林'会被以conding:utf-8的形式保存到新的内存空间中
print repr(s) #'\xe6\x9e\x97' 三个Bytes,证明确实是utf-8
print type(s) #<type 'str'>
s.decode('utf-8')
# s.encode('utf-8') #报错,s为编码后的结果bytes,所以只能decode
unicode类型
当python解释器执行到产生字符串的代码时(例如s=u'林'),会申请新的内存地址,然后将'林'以unicode的格式存放到新的内存空间中,所以s只能encode,不能decode
s=u'林'
print repr(s) #u'\u6797'
print type(s) #<type 'unicode'>
# s.decode('utf-8') #报错,s为unicode,所以只能encode
s.encode('utf-8')
打印到终端
对于print需要特别说明的是:
当程序执行时,比如
x='林'
print(x) #这一步是将x指向的那块新的内存空间(非代码所在的内存空间)中的内存,打印到终端,而终端仍然是运行于内存中的,所以这打印可以理解为从内存打印到内存,即内存->内存,unicode->unicode
对于unicode格式的数据来说,无论怎么打印,都不会乱码
python3中的字符串与python2中的u'字符串',都是unicode,所以无论如何打印都不会乱码
在pycharm中

在windows终端

但是在python2中存在另外一种非unicode的字符串,此时,print x,会按照终端的编码执行x.decode('终端编码'),变成unicode后,再打印,此时终端编码若与文件开头指定的编码不一致,乱码就产生了
在pycharm中(终端编码为utf-8,文件编码为utf-8,不会乱码)
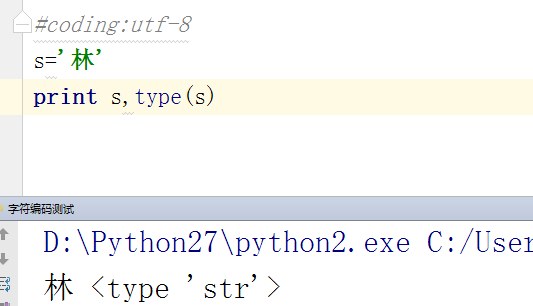
在windows终端(终端编码为gbk,文件编码为utf-8,乱码产生)

思考题:
分别验证在pycharm中和cmd中下述的打印结果
#coding:utf-8
s=u'林' #当程序执行时,'林'会被以unicode形式保存新的内存空间中
#s指向的是unicode,因而可以编码成任意格式,都不会报encode错误
s1=s.encode('utf-8')
s2=s.encode('gbk')
print s1 #打印正常否?
print s2 #打印正常否
print repr(s) #u'\u6797'
print repr(s1) #'\xe6\x9e\x97' 编码一个汉字utf-8用3Bytes
print repr(s2) #'\xc1\xd6' 编码一个汉字gbk用2Bytes
print type(s) #<type 'unicode'>
print type(s1) #<type 'str'>
print type(s2) #<type 'str'>
5.3.2 在python3 中也有两种字符串类型str和bytes
str是unicode
#coding:utf-8
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中,
#s可以直接encode成任意编码格式
s.encode('utf-8')
s.encode('gbk')
print(type(s)) #<class 'str'>
bytes是bytes
#coding:utf-8
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中,
#s可以直接encode成任意编码格式
s1=s.encode('utf-8')
s2=s.encode('gbk')
print(s) #林
print(s1) #b'\xe6\x9e\x97' 在python3中,是什么就打印什么
print(s2) #b'\xc1\xd6' 同上
print(type(s)) #<class 'str'>
print(type(s1)) #<class 'bytes'>
print(type(s2)) #<class 'bytes'>
#coding:utf-8
#在python3中有两中形式的字符串
#1 str-》unicode格式的,相当于python2的字符串加u
#2 bytes
#unicode----->encode(utf-8)------>bytes
#bytes------>decode(gbk)------->unicode
name1="林" #掌握:在python3中字符串都是unicode格式的二进制存放与内存中
#而在python2中字符串都是已经encode后的结果,即bytes
#unicode----->encode(gbk)------>bytes
#bytes------>decode(gbk)------->unicode
x=name1.encode('gbk')
# print(x,type(x))
print(x.decode('gbk'))
#了解
#python2的字符串有两种:
#1 str=bytes
#2 u"林"就相当于python3的字符串
#unicode----->encode(utf-8)------>bytes
#bytes------>decode(gbk)------->unicode
# name=u'林' #name.encode('utf-8')
# print(type(name))
# print(name)
1 以什么编码存的就要以什么编码取出
ps:内存固定使用unicode编码,
我们可以控制的编码是往硬盘存放或者基于网络传输选择编码
2 数据是最先产生于内存中,是unicode格式,要想传输需要转成bytes格式
#unicode----->encode(utf-8)------>bytes
拿到bytes,就可以往文件内存放或者基于网络传输
#bytes------>decode(gbk)------->unicode
3 python3中字符串被识别成unicode
python3中的字符串encode得到bytes
4 了解
python2中的字符串就bytes
python2中在字符串前加u,就是unicode
二、文件处理
#基本操作
__author__ = 'ctz' #只读操作r 文件不存在则报错 #f=open(r"1","r",encoding="utf-8") #r代表后面的是单纯的字符串,避免转义字符 # print(f.read())#一次读完整个文件 # print(f.readline(),end="")#一次读一行文件 # print(f.readline(),end="") # print(f.readline(),end="") # print(f.readlines())#把文件读出一个列表每一个元素就是一行 # f.close() #只写操作w 文件不存在则创建空文件,文件存在则清空 # f=open("2","w",encoding="utf-8") # f.write("hello world ctz\n") # f.writelines(["aaaaa\n","bbbbbb\n"]) # f.close() #只追加模式a 文件不存在则创建,文件存在 则在后面追加 # f=open("2","a",encoding="utf-8") # print(f.readable()) # print(f.writable()) # f.write("aaaaaaaaaaaaaa\n") # f.writelines(["ctzctz\n","tzctzc\n"]) #rb wb ab b模式不考虑字符的编码 可以操作图片 视频之类的复杂文件 #rb # f=open("1.jpg","rb") # print(f.read()) # f=open("1","rb") # print(f.read().decode("utf-8")) #wb # f=open("1.jpg","rb") # data=f.read() # f=open("2.jpg","wb") # f.write(data) # f=open("4.txt","wb") # f.write("aaaaaaa\n".encode("utf-8")) #ab # f=open("1","ab") # f.write("陈太章陈太章\n".encode("utf-8"))
#常用操作
__author__ = 'Administrator'
#文件上下文管理
# with open("1","r",encoding="utf-8") as f_read,open("5","w",encoding="utf-8")\
# as f_write:
# data=f_read.read()
# f_write.write(data)
#循环读文件的每一行
# with open("2","r",encoding="utf-8")as f:
# for line in f:
# print(line,end="")
#文件的修改
#方法一 适用于小文件修改
# import os
# with open("5","r",encoding="utf-8") as f_r,open("6","w",encoding="utf-8") as f_w:
# data=f_r.read()
# f_w.write(data.replace("alex","Alex_sb"))
# os.remove("5")
# os.rename("6","5")
#方法二 适用于大文件
import os
with open("5","r",encoding="utf-8") as f_r,open("6","w",encoding="utf-8") as f_w:
for line in f_r:
f_w.write(line.replace("Alex_sb","sb_Alex_sb"))
os.remove("5")
os.rename("6","5")
#只读方式打开文件,读 #f = open('复习.py','r',encoding='utf-8') #f文件+句柄 能操作文件的一个东西 #for i in f: # print(i,end='') #写方式打开文件 # f = open('复习2.py','w',encoding='utf-8') #可写可读 打开文件的时候文件就为空,写的是任意内容,读的是刚刚写进去的内容 #要想读,先移动光标 #读的光标和写的光标是两回事 # f = open('复习2.py','w+',encoding='utf-8') # f.write('12237yuiayi') # #seek 制定光标的位置在0位置 # f.seek(0) # print(f.read(3)) # f.write('kahkshldkhd') # print('***',f.read()) # f.close() #可读可写 # f = open('复习2.py','r+',encoding='utf-8') # print(f.read()) # f.write('\najshdjkdjk') # f.close() #追加可读 f = open('复习2.py','a+',encoding='utf-8') f.seek(0) print(f.read()) #字符编码 #python2 str --> bytes ascii #python3 str --> unicode #文件处理 #文件处理的方式 #r读 光标文件开头 不会影响文件内容 #w写 光标在文件开头 打开文件的时候文件即被清空 #a追写 光标在文件末尾 不会影响文件内容 #r+可读可写 光标在文件开头 #w+可写可读 光标在文件开头 打开文件的时候文件即被清空 #a+追加可读 光标在文件末尾 #带b 上面的6种模式都可以+b














 2609
2609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









