






背景
之前已经写过TensorFlow图与模型的加载与存储了,写的很详细,但是或闻有人没看懂,所以在附上一个关于模型加载与存储的例子,CODE是我偶然看到了,就记下来了.其中模型很巧妙,比之前numpy写一大堆简单多了,这样有利于把主要注意力放在模型的加载与存储上.
解析
创建保存文件的类:saver = tf.train.Saver()
saver = tf.train.Saver() ,即为常见保存模型,图,数据的类,其内部结构在源码中有详细的解释,这个之前的文章已经说过了,这次只讲,我们如何我们具体要用的方法
saver.save() 保存
源码结构
def save(self,
sess,
save_path,
global_step=None,
latest_filename=None,
meta_graph_suffix="meta",
write_meta_graph=True,
write_state=True):
# 实际运用 :
# saver = tf.train.Saver()
# saver.save(sess, checkpoint_dir + 'model55.ckpt', global_step=i+1)
# 注意,实际保存时 model55.ckpt 会被保存为多个文件常用的参数:
1. sess : 要保存的session
2. save_path :保存路径,注意想要保存在代码所在目录下,前面不要加’/’不然会变成根目录
3. global_step :多次迭代时,使用该参数,按照步骤保存
4. 保存文件如下,后面的-50,100,是按照步骤(global_step)保存的
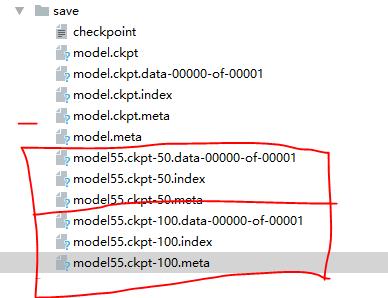
调用
源码结构
def restore(self, sess, save_path):
# sess 即为 当前session
# save_path : 与之前保存时的使用的名字一直
# 如果调取上一个例子存储的模型:此时 save_path = checkpoint_dir + 'model55.ckpt'
# 代码实例 :saver.restore(sess, ckpt.model_checkpoint_path)- saver.restore(),会恢复原来session 中的图,参数,等(也就是相当于直接调用原来训练好的模型),假如你传入的文件夹中存储着多个model.ckpt文件组,那么会默认调用最后存储的ckpt文件组,
- ckpt文件组的排序为:当按照步骤排序时,最后保存的步骤为最新,按照时间排序时,同理
ckpt文件
之前已经在原来的文章中写过,这里有必要再发一次
TensorFlow模型会保存在后缀为.ckpt的文件中。保存后在save这个文件夹中会出现3个文件,因为TensorFlow会将计算图的结构和图上参数取值分开保存。
checkpoint文件保存了一个目录下所有的模型文件列表,这个文件是tf.train.Saver类自动生成且自动维护的。在
checkpoint文件中维护了由一个tf.train.Saver类持久化的所有TensorFlow模型文件的文件名。当某个保存的TensorFlow模型文件被删除时,这个模型所对应的文件名也会从checkpoint文件中删除。checkpoint中内容的格式为CheckpointState
Protocol Buffer.model.ckpt.meta文件保存了TensorFlow计算图的结构,可以理解为神经网络的网络结构
TensorFlow通过元图(MetaGraph)来记录计算图中节点的信息以及运行计算图中节点所需要的元数据。TensorFlow中元图是由MetaGraphDef
Protocol Buffer定义的。MetaGraphDef
中的内容构成了TensorFlow持久化时的第一个文件。保存MetaGraphDef
信息的文件默认以.meta为后缀名,文件model.ckpt.meta中存储的就是元图数据。model.ckpt文件保存了TensorFlow程序中每一个变量的取值,这个文件是通过SSTable格式存储的,可以大致理解为就是一个(key,value)列表。model.ckpt文件中列表的第一行描述了文件的元信息,比如在这个文件中存储的变量列表。列表剩下的每一行保存了一个变量的片段,变量片段的信息是通过SavedSlice
Protocol
Buffer定义的。SavedSlice类型中保存了变量的名称、当前片段的信息以及变量取值。TensorFlow提供了tf.train.NewCheckpointReader类来查看model.ckpt文件中保存的变量信息。如何使用tf.train.NewCheckpointReader类这里不做说明,请自查。
CODE AND RUN
import tensorflow as tf
import numpy as np
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
x = tf.placeholder(tf.float32, shape=[None, 1])
# 拟合 y
y = 4 * x + 4
w = tf.Variable(tf.random_normal([1], -1, 1))
b = tf.Variable(tf.zeros([1]))
y_predict = w * x + b
loss = tf.reduce_mean(tf.square(y - y_predict))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
isTrain = False
train_steps = 100
checkpoint_steps = 50
checkpoint_dir = 'save/'
saver = tf.train.Saver() # defaults to saving all variables - in this case w and b
x_data = np.reshape(np.random.rand(10).astype(np.float32), (10, 1))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
if isTrain:
for i in range(train_steps):
sess.run(train, feed_dict={x: x_data})
if (i + 1) % checkpoint_steps == 0:
saver.save(sess, checkpoint_dir + 'model55.ckpt', global_step=i+1)
print(sess.run(w))
print(sess.run(b))
'''
运行结果
[ 3.87540483]
[ 4.07181311]
最后训练好的模型跑出来的数据
[ 3.994277]
[ 4.00329876]
'''
else:
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
else:
pass
print(sess.run(w))
print(sess.run(b))
'''
[ 3.994277]
[ 4.00329876]
'''最后
更详细的内容,请点击这里















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









