



高斯贝叶斯用来处理连续数据,假设数据里每个特征项相关联的数据是连续值并且服从高斯分布,参考这里。
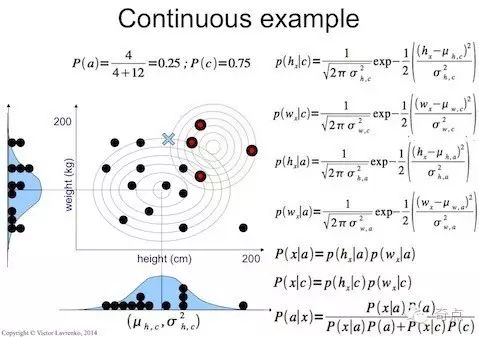
概率公式: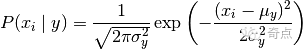
在《白话大数据与机器学习》里使用了sklearn里的GaussionNB来处理连续数据:
训练模型 clf = GaussianNB().fit(x, y)
预测数据 clf.predict(x)
这里我们来实现一下高斯贝叶斯算法,看看该算法具体是如果实现的。
1 准备数据
首先我们需要一些训练数据 这里使用鸢尾花数据。
这里x是一个(150, 4)2维数组,总共150条数据,打印其中的5条数据看一下:
[[5.1, 3.5, 1.4, 0.2],
[4.9, 3.0, 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5.0, 3.6, 1.4, 0.2],
... ...]可以看到每条数据都有4个特征项分别是: 萼片的长度,萼片的宽度,花瓣的长度,花瓣的宽度
y是x里每条数据对应的分类:
[0, 0, 1, 1, 2, …]可以看到x里对应的分类总共有3种[0,1,2]。
2 训练模型
其实是求出了属于每种分类里的数据在每个特征列上的平均值和方差。
计算每种分类里每个特征列的平均值和方差
{0: [[5.1, 3.5, 1.4, 0.2],
[4.9, 3.0, 1.4, 0.2],
... ...],
1: [[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0,2],
... ...],
2: [[5.0, 3.6, 1.4, 0.2],
... ...]}得到平均值结果集
{0: [5.006, 3.418, 1.464, 0.244],
1: [5.936, 2.770, 4.260, 1.326],
2: [6.588, 2.974, 5.552, 2.026]}得到方差结果集
{0: [0.1210, 0.1420, 0.029, 0.011],
1: [0.2611, 0.9650, 0.216, 0.038],
2: [0.3960, 0.1019, 0.298, 0.073]}3 预测数据
其实是求出待预测数据属于哪种分类的概率更大。
待预测的数据
[3.1, 4.4, 2.1, 3.1]计算待预测的数据里面, 每条数据属于某一类的概率是多少,
调用文章开始给出的概率公式计算, μ就是上一步得到的每个特征列均值,σ 2就是上一步得到的每个特征列方差,xi就是待预测数据里的每个特性项值,
这里分别计算出每个特征项的概率,然后把得到的每个特征项的概率相乘就得到了每条数据属于某一类的概率
[[8.512, 0.001, 0.006]]可以看到待预测数据属于分类0,1,2的概率被计算出来了。
完整代码可以访问github进行下载 https://github.com/azheng333/Ml_Algorithm.git。

















 4629
4629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









