






本文主要是自己的在线代码笔记。在生物医学本体Ontology构建过程中,我使用Selenium定向爬取生物医学PubMed数据库的内容。
PubMed是一个免费的搜寻引擎,提供生物医学方面的论文搜寻以及摘要。它的数据库来源为MEDLINE(生物医学数据库),其核心主题为医学,但亦包括其他与医学相关的领域,像是护理学或者其他健康学科。它同时也提供对于相关生物医学资讯上相当全面的支援,像是生化学与细胞生物学。
PubMed是因特网上使用最广泛的免费MEDLINE,该搜寻引擎是由美国国立医学图书馆提供,它是基于WEB的生物医学信息检索系统,它是NCBI Entrez整个数据库查询系统中的一个。PubMed界面提供与综合分子生物学数据库的链接,其内容包括:DNA与蛋白质序列,基因图数据,3D蛋白构象,人类孟德尔遗传在线,也包含着与提供期刊全文的出版商网址的链接等。
医学导航链接:http://www.meddir.cn/cate/736.htm
PubMed官网:http://pubmed.cn/
实现代码
实现的代码主要是Selenium通过分析网页DOM结点进行爬取。
爬取的地址是:http://www.medlive.cn/pubmed/
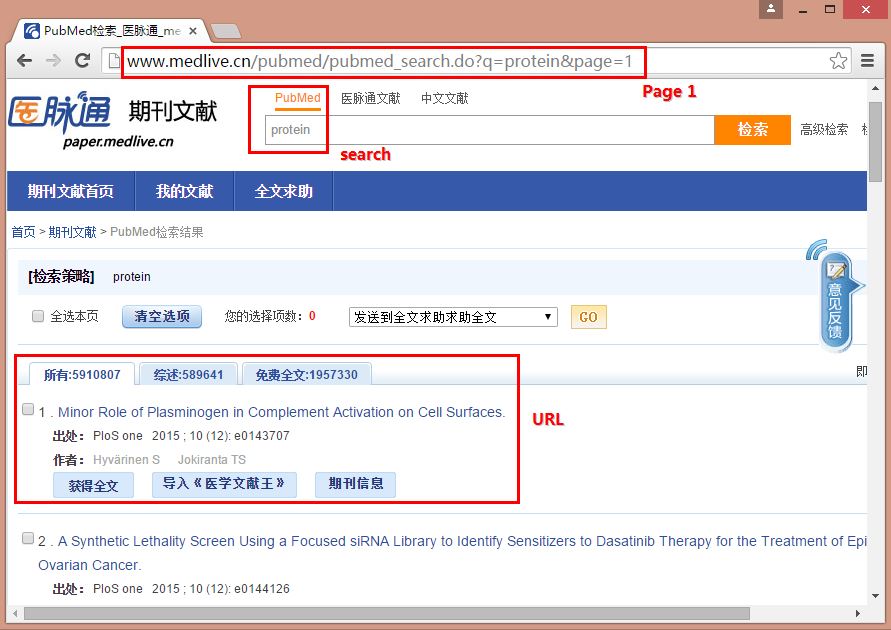
在网址中搜索Protein(蛋白质)后,分析网址可发现设置Page=1~20可爬取前1~20页的URL信息。链接如下:
http://www.medlive.cn/pubmed/pubmed_search.do?q=protein&page=1
1 # coding=utf-8 2 """ 3 Created on 2015-12-05 Ontology Spider 4 @author Eastmount CSDN 5 URL: 6 http://www.meddir.cn/cate/736.htm 7 http://www.medlive.cn/pubmed/ 8 http://paper.medlive.cn/literature/1502224 9 """ 10 11 import time 12 import re 13 import os 14 import shutil 15 import sys 16 import codecs 17 from selenium import webdriver 18 from selenium.webdriver.common.keys import Keys 19 import selenium.webdriver.support.ui as ui 20 from selenium.webdriver.common.action_chains import ActionChains 21 22 #Open PhantomJS 23 driver = webdriver.Firefox() 24 driver2 = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe") 25 wait = ui.WebDriverWait(driver,10) 26 27 ''' 28 Load Ontoloty 29 去到每个生物本体页面下载摘要信息 30 http://paper.medlive.cn/literature/literature_view.php?pmid=26637181 31 http://paper.medlive.cn/literature/1526876 32 ''' 33 def getAbstract(num,title,url): 34 try: 35 fileName = "E:\\PubMedSpider\\" + str(num) + ".txt" 36 #result = open(fileName,"w") 37 #Error: 'ascii' codec can't encode character u'\u223c' 38 result = codecs.open(fileName,'w','utf-8') 39 result.write("[Title]\r\n") 40 result.write(title+"\r\n\r\n") 41 result.write("[Astract]\r\n") 42 driver2.get(url) 43 elem = driver2.find_element_by_xpath("//div[@class='txt']/p") 44 #print elem.text 45 result.write(elem.text+"\r\n") 46 except Exception,e: 47 print 'Error:',e 48 finally: 49 result.close() 50 print 'END\n' 51 52 ''' 53 循环获取搜索页面的URL 54 规律 http://www.medlive.cn/pubmed/pubmed_search.do?q=protein&page=1 55 ''' 56 def getURL(): 57 page = 1 #跳转的页面总数 58 count = 1 #统计所有搜索的生物本体个数 59 while page<=20: 60 url_page = "http://www.medlive.cn/pubmed/pubmed_search.do?q=protein&page="+str(page) 61 print url_page 62 driver.get(url_page) 63 elem_url = driver.find_elements_by_xpath("//div[@id='div_data']/div/div/h3/a") 64 for url in elem_url: 65 num = "%05d" % count 66 title = url.text 67 url_content = url.get_attribute("href") 68 print num 69 print title 70 print url_content 71 #自定义函数获取内容 72 getAbstract(num,title,url_content) 73 count = count + 1 74 else: 75 print "Over Page " + str(page) + "\n\n" 76 page = page + 1 77 else: 78 "Over getUrl()\n" 79 time.sleep(5) 80 81 ''' 82 主函数预先运行 83 ''' 84 if __name__ == '__main__': 85 path = "F:\\MedSpider\\" 86 if os.path.isfile(path): #Delete file 87 os.remove(path) 88 elif os.path.isdir(path): #Delete dir 89 shutil.rmtree(path, True) 90 os.makedirs(path) #Create the file directory 91 getURL() 92 print "Download has finished."
分析HTML
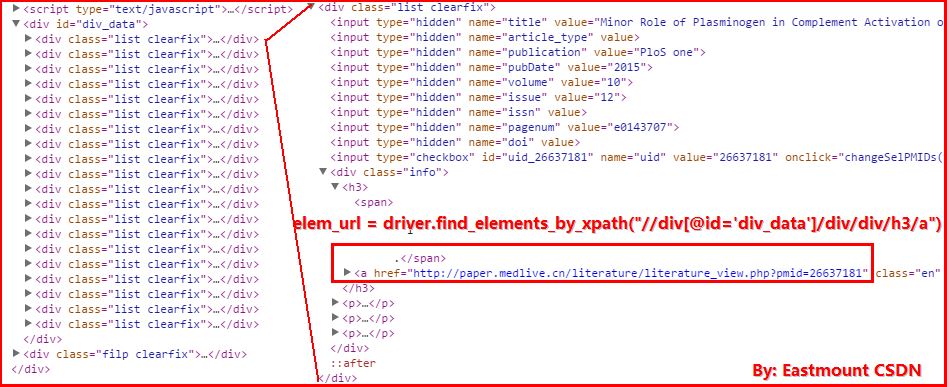
1.获取每页Page中的20个关于Protein(蛋白质)的URL链接和标题。其中getURL()函数中的核心代码获取URL如下:
url = driver.find_elements_by_xpath("//div[@id='div_data']/div/div/h3/a")
url_content = url.get_attribute("href")
getAbstract(num,title,url_content)
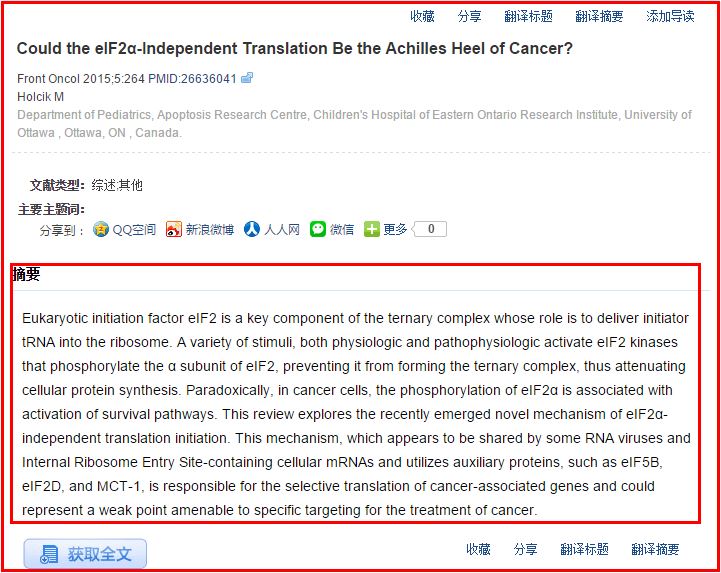
2.再去到具体的生物文章页面获取摘要信息

其中你可能遇到的错误包括:
1.Error: 'ascii' codec can't encode character u'\u223c'
它是文件读写编码错误,我通常会将open(fileName,"w")改为codecs.open(fileName,'w','utf-8') 即可。
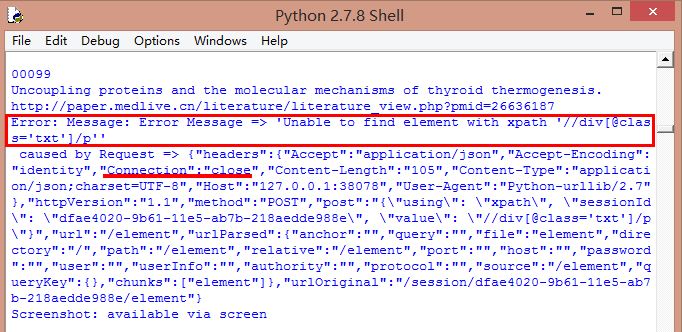
2.第二个错误如下图所示或如下,可能是因为网页加载或Connection返回Close导致
WebDriverException: Message: Error Message => 'URL ' didn't load. Error: 'TypeError: 'null' is not an object
运行结果
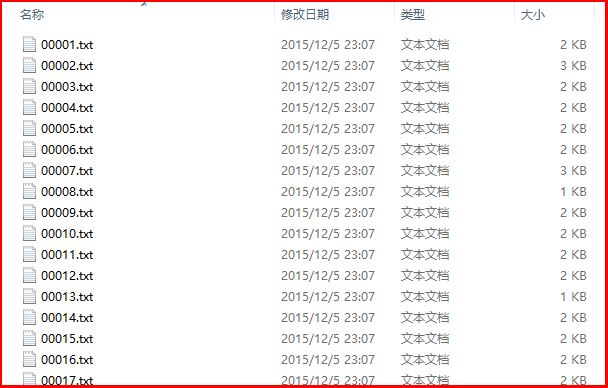
得到的运行结果如下所示:00001.txt~00400.txt共400个txt文件,每个文件包含标题和摘要,该数据集可简单用于生物医学的本体学习、命名实体识别、本体对齐构建等。

(By:Eastmount 2015-12-06 深夜3点半 http://blog.csdn.net/eastmount/)














 5662
5662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









