






一、安装环境:windows10,anaconda3,python3.6
由于框架maskrcnn需要json数据集,在没安装labelme环境和跑深度学习之前,我安装的是anaconda3,其中pyhton是3.7版本的,经网上查阅资料,经过一番查找资料,发现,原来在2019年,TensorFlow还不支持python3.7,所以,迫于无奈,我只能乖乖把python的版本退回到3.6版本,具体步骤也很简单。就是打开anaconda prompt ,然后输入conda install python=3.6,然后等待提示(y/n),输入y,等待十几分钟,就会提示done,这样的话,就表示python3.7已经退回到python3.6了。(经过尝试这种方法在我这里没有行得通,可能跟网速有关,又尝试了另一种方法,有兴趣的可以尝试一下。)索性就把labelme安装到3.6中了。
二、安装过程:
1、管理员身份打开 anaconda prompt
2、输入命令:conda create --name=labelme python=3.6
3、输入命令:activate labelme
4、输入命令:pip install pyqt5,pip install pyside2(自己刚开始没有安装pyside2,运行 \anaconda安装目录\envs\labelme\Scripts\label_json_to_dataset.exe 会出现module "pyside"缺失错误)
5、输入命令:pip install labelme(由于网络原因或者库的地址,经常运行一半出现错误,不要气馁,多执行几次)
6、输入命令:labelme 即可打开labelme。如下:
安装完成后,需要使用再次启动labelme。则需要重新打开anaconda prompt,输入activate labelme,进入labelme环境。再输 入命令: labelme 即可
三、用labelme标注完图片后,会生成json文件
以小猫为例:点击保存会在自己的图片目录下生成json文件
 点点
点点
生成的json文件并不能直接用,我们需要对他进行批处理才能成为maskrcnn需要的数据集,批量转化如下:
abelme标注工具再转化.json文件有一个缺陷,一次只能转换一个.json文件,然而深度学习的项目通常需要大量的数据,那么转换.json文件就是一个比较耗时的工作;因此,对labelme做出了改进,可以实现批量转换.json文件。
在安装Anaconda中找到json_to_dataset.py文件如果未找到可以在计算机中搜索,将该文件代码修改为以下代码:
importargparseimportbase64importjsonimportosimportos.path as ospimportwarningsimportPIL.Imageimportyamlfrom labelme importutilsdefmain():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.")
parser=argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args=parser.parse_args()
json_file=args.json_file
alist=os.listdir(json_file)for i inrange(0,len(alist)):
path=os.path.join(json_file,alist[i])
data=json.load(open(path))
out_dir= osp.basename(path).replace('.', '_')
out_dir=osp.join(osp.dirname(path), out_dir)if notosp.exists(out_dir):
os.mkdir(out_dir)if data['imageData']:
imageData= data['imageData']else:
imagePath= os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath,'rb') as f:
imageData=f.read()
imageData= base64.b64encode(imageData).decode('utf-8')
img=utils.img_b64_to_arr(imageData)
label_name_to_value= {'_background_': 0}for shape in data['shapes']:
label_name= shape['label']if label_name inlabel_name_to_value:
label_value=label_name_to_value[label_name]else:
label_value=len(label_name_to_value)
label_name_to_value[label_name]=label_value#label_values must be dense
label_values, label_names =[], []for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)assert label_values ==list(range(len(label_values)))
lbl= utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions= ['{}: {}'.format(lv, ln)for ln, lv inlabel_name_to_value.items()]
lbl_viz=utils.draw_label(lbl, img, captions)
PIL.Image.fromarray(img).save(osp.join(out_dir,'img.png'))
utils.lblsave(osp.join(out_dir,'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir,'label_viz.png'))
with open(osp.join(out_dir,'label_names.txt'), 'w') as f:for lbl_name inlabel_names:
f.write(lbl_name+ '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info= dict(label_names=label_names)
with open(osp.join(out_dir,'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)print('Saved to: %s' %out_dir)if __name__ == '__main__':
main()
操作命令如下图:
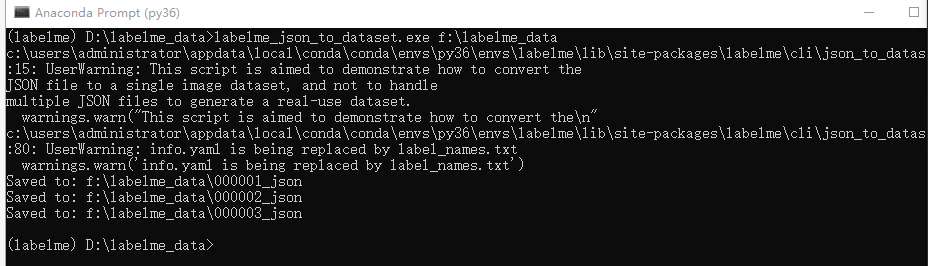
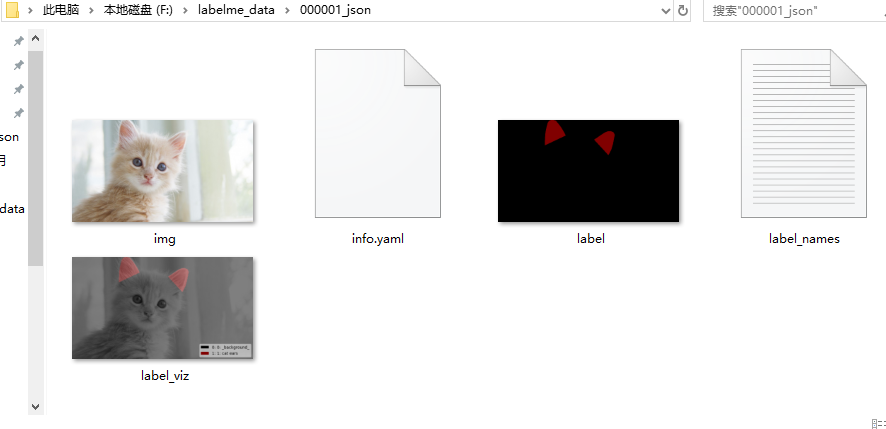
生成效果如下:每张图片生成五个文件 ,这就是我们所需要的














 2174
2174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









