






 本文总结了Android平台实时Object Detection App的开发技术,包括使用TensorFlow Lite加载模型,处理传感器朝向,截取并预处理帧数据,以及在手机上显示和运行模型。重点讲解了相机数据的实时显示、帧数据的YUV到RGB转换、图像旋转与缩放,以及模型结果在屏幕上的正确显示方法。
本文总结了Android平台实时Object Detection App的开发技术,包括使用TensorFlow Lite加载模型,处理传感器朝向,截取并预处理帧数据,以及在手机上显示和运行模型。重点讲解了相机数据的实时显示、帧数据的YUV到RGB转换、图像旋转与缩放,以及模型结果在屏幕上的正确显示方法。
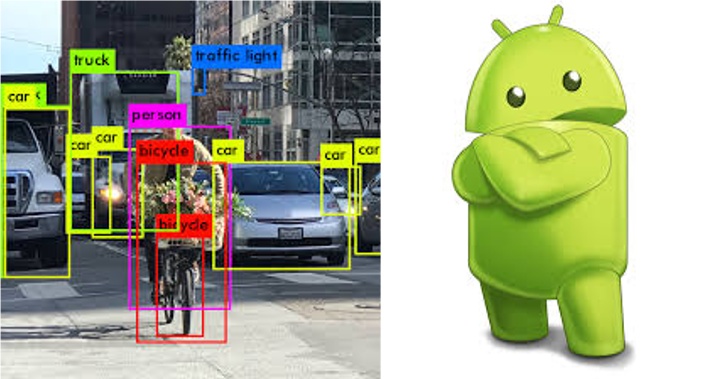
本文主要对Android平台上开发实时Object Detection类App涉及到的一些技术进行总结。
1. 模型
由于要实时检测,所以模型文件必须下载到手机端,在手机端本地运行模型的inference。对于这类需求,Tensorflow已经有了一套成熟的方案:
- 后端模型训练:在服务端训练好tensorflow物体检测模型。训练好之后,将其导出为SavedModel格式的模型文件。SavedModel文件中不仅包括训练所得的模型参数,还包括完成的计算图信息,因此,可以脱离模型源码而独立运行。
- 下载模型到手机:在App内,可以通过网络,将训练好的模型下载到手机内。
- 手机端运行模型:通过TensorFlow Android版TFLite来加载、运行SavedModel模型文件。
2. 模型加载
TFLite模型实例可以提前、创建,然后反复调用来提高效率,而不用每次创建一个新的实例。
3. 传感器朝向问题
相机得到的图像数据,是手机上的图像传感器产生的数据。图像传感器,这个硬件固定在手机上,并且具有一个它自己认为的“正“方向。App的每个界面,也有一个设置的“正”方向,例如:portrait、landscape。不同的“正”方向,直接决定了X、Y轴的朝向,因此,屏幕上同一个点,在不同“正”方向下的坐标是不同的。对于实时显示相机的数据,通过setDisplayOrientation 来告诉传感器我们需要的“正”方向,与传感器默认的正方向差了多少度(90的倍数),然后图片在屏幕上显示时,就会按照我们设置的“正”方向来显示。
需要注意的时,即使通过设置setDisplayOrientation 正确显示出来了图片,但是背后的图像数据的正方向,还是传感器的“正”方向,即:
- 横屏(landscape)并且HOME键在右侧时,朝上,即为传感器的“正”方向。此时,我们需要的图片的“正”张方向,与传感器的“正”方向一致;
- 竖屏(portrait)并且HOME建在下侧时,朝右,即为传感器的“正“方向。此时,我们需要的图片的“正”张方向,与传感器的“正”方向不一致。所以在调用模型之前,需要将图片数据从传感器“正”方向,旋转为我们需要的“正“方向后,再调用模型进行计算。

4. 相机数据的实时显示
可以使用TextureView来显示传感器的数据流。TextureView可以像普通View一样来操作,相比SurfaceView,更方便一些。
5. 截获帧数据
实时物体检测,本质上是对实时图像数据流的某些帧表示的图片来做物体检测。如何获取帧数据就是一个关键的问题了。以Camera API为例(区别于Camera2 API),主要流程为:
- 设置回调,等待
TextureView可用 TextureView可用后,启动相机,设置相关参数。重要的参数包括:预览尺寸PreviewSize(始终是相对于传感器正方向)、 显示旋转度DisplayOrientation(我们需要的正方向与传感器正方向的逆时针偏差:90的倍数) 。最后通过setPreviewTexture来让TextureView来显示图像数据流。- 在相机上,通过
setPreviewCallbackWithBuffer来设置一个每帧数据的回调,从而可以拿到相机的每帧数据(一张图片)。这里可以配合addCallbackBuffer一起使用,来控制何时需要回调、何时不需要:需要下一帧时,先调用addCallbackBuffer,下一帧的数据就可以从回调的参数中拿到;拿到一帧数据后,如果想再获取一帧,则需要再调用一次addCallbackBuffer。如果不调用,则不会触发回调。基于这样的机制,我们可以先拿到一帧数据,花费一点时间处理完这帧的检测后,再拿一帧新的数据。在处理当前帧的数据时,不需要系统返回帧数据,(返回了也处理不过来,耗费资源)如此一来,相当于提高的效率。
6. 帧数据预处理
在onPreviewFrame回调中返回的byte数组,即为当前的一帧数据。
值得注意的是,返回的数据格式并不是物体检测模型需要的RGB格式,而是YUV格式。所以,首先需要将其转为RGB格式。
前面提到,返回的帧数据,是以传感器“正”方向为准的,因此,需要将其旋转为实际的“正”方向。另外,模型接受的输入图片的尺寸可能与当前数据不一致,则需要缩放。旋转、缩放操作,可以通过Matrix矩阵来实现。对于一个设备,Matrix矩阵是固定的,考虑效率,可以预先生成这个转换矩阵,之后重用即可。
经过以上处理后,即可得到可用于模型输入的RGB数据。
7. 调用模型
模型计算,一般是比较耗时的操作,所以不能放到UI线程中操作,防止阻塞UI线程造成App卡顿。可以用handlerThread创建一个带消息循环的后台线程,在后台线程中调用模型。
8. 模型结果预处理
后台线程调用模型,即可得到预测结果:物体边框、类别等信息。这里,不能直接使用边框的坐标信息在界面中显示边框。前面提到,图像传感器的原始数据在作为模型的输入之前,经过了一个Matrix矩阵的处理,实现了旋转、缩放。因此,需要对返回的坐标信息执行一个以上Matrix矩阵的逆变换 ,将其还原为针对原始传感器数据(RGB数据)的坐标值。
实际传感器数据的宽、高,与手机界面上显示的图片的宽、高也不同,因此,需要再将其变换(旋转+缩放),以便在屏幕上能正确显示。示意图如下:
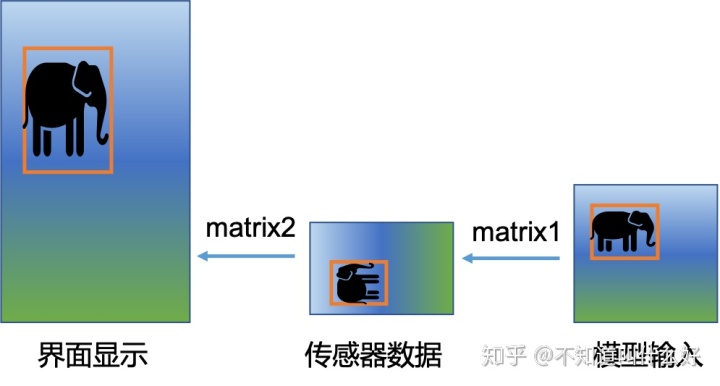
经过两步Maxtrix变换处理后,即可得到显示用的坐标信息。
9. 模型结果显示
可以自定义一个View,在draw方法中用canvasAPI将结果画出来。这里需要注意的是执行逻辑在不同线程之间的切换。
模型调用、结果预处理等逻辑,是在后台线程handlerThread里面运行的。可以在后台线程中计算好结果,将结果保存到一个公共变量中,然后调用View的 postInvalidate方法,触发View在UI线程中调用draw来绘制结果。
10. 总结
基于以上内容,即可开发出一个简单的物体检测App。除了TFLite,PyTorch也推出了移动版SDK,使用流程大致与TFLite类似。因此,如果模型是PyTorch版,也可以在手机上跑的起来。















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









