






清华&百度等联合提出了ReSyncer,可以实现更高稳定性和质量的口型同步,而且还支持创建虚拟表演者所必需的各种有趣属性,包括快速个性化微调、视频驱动的口型同步、说话风格的转换,甚至换脸。
ReSyncer的工作原理可以简单理解为:首先,它接收你要处理的音频。然后,它使用一个特别的程序来分析这个声音,并根据声音的特点生成一个3D面部模型。这部分被称为Style-SyncFormer。接下来,ReSyncer会用生成的3D面部模型和目标视频中的脸部图像相结合,制作出一个嘴唇动作同步、表情丰富的高质量视频。这样,创造出肌肉动态与音频配合得天衣无缝的虚拟人物便成为可能。

上面为ReSyncer生成的假唱/说话风格转换/换脸结果。该方法不仅可以产生高保真的口型视频 但音频可以进一步转移任何目标人的说话风格和身份。
亮点直击
- 提出了ReSyncer框架,该框架通过涉及具有简单重新配置的3D面部网格,展示了基于Style 的生成器在同步视听面部信息方面的强大功能。
- 我们提出了 Style-SyncFormer,它使用简单的 Transformer 块学习风格化的 3D 面部动态,从而实现广义的 3D 面部动画。
- ReSyncer不仅可以实现更高稳定性和质量的口型同步,而且还支持创建虚拟表演者所必需的各种有趣属性,包括快速个性化微调、视频驱动的口型同步、说话风格的转换,甚至换脸。
相关链接
论文地址:http://arxiv.org/abs/2408.03284v1
项目地址:https://guanjz20.github.io/projects/ReSyncer
论文阅读

ReSyncer:基于风格重新布线的统一视听同步面部表演者生成器
摘要
使用给定的音频对口型视频是各种应用的基础,包括创建虚拟主持人或表演者。虽然最近的研究探索了使用不同技术的高保真口型同步,但它们的任务导向模型要么需要长期视频进行特定片段的训练,要么保留可见的伪影。
在本文中,我们提出了一个统一有效的框架 ReSyncer,它可以同步广义的视听面部信息。关键设计是重新审视和重新连接基于风格的生成器,以有效采用由原则性风格注入的 Transformer 预测的 3D 面部动态。通过简单地重新配置噪声和风格空间内的信息插入机制,我们的框架将运动和外观与统一的训练融合在一起。
大量实验表明,ReSyncer 不仅可以根据音频制作高保真的口型同步视频,而且还支持多种适合创建虚拟主持人和表演者的吸引人的属性,包括快速个性化微调、视频驱动的口型同步、说话风格的转换,甚至换脸。
方法
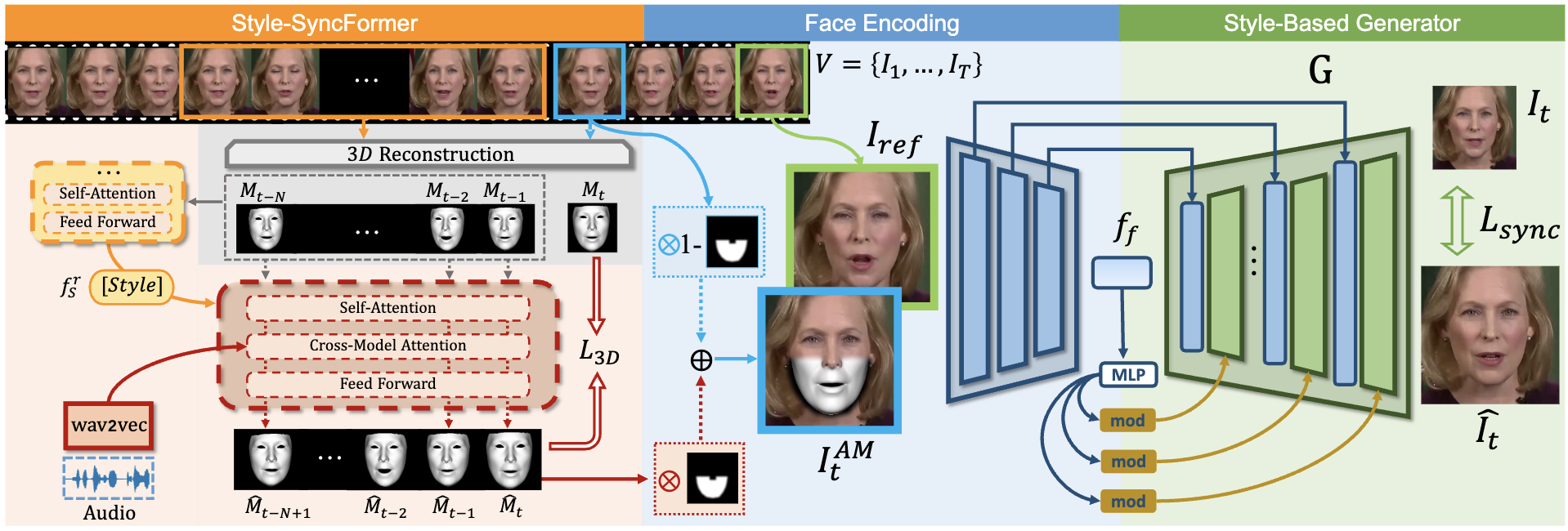
ReSyncer框架主要包括两个阶段:
- 第一阶段是风格注入唇同步变换器(Style-SyncFormer),其负责从音频输入预测3D面部动态;
- 第二阶段是重新配置的基于风格的生成器,用以将3D动态渲染成高保真的面部图像。
具体实现中,Style-SyncFormer利用音频特征,通过简单的Transformer结构预测与说话风格相关的3D面部网格位移。在模型训练过程中,注入的3D面部网格严重影响生成的质量。此外,在基于风格的生成器中,通过简单插入机制与高质量的3D面部信息融合来生成最终图像,从而大幅提升了嘴唇同步的质量和稳定性。
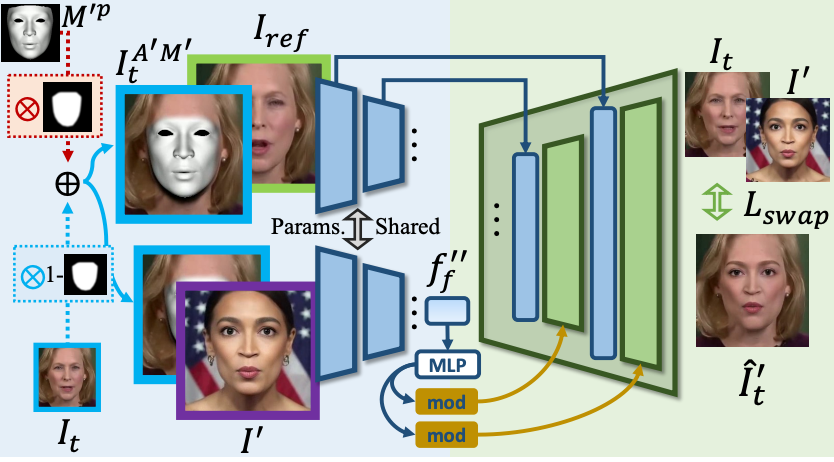
换脸的Pipeline。 通过重新配置输入数据和额外的训练损失,可以同时实现口型同步和换脸。
效果

定性交叉同步结果。 顶行显示驾驶音频的口型同步视频。基于“模板”行的生成结果应具有与第一行“口型同步视频”相同的唇形。
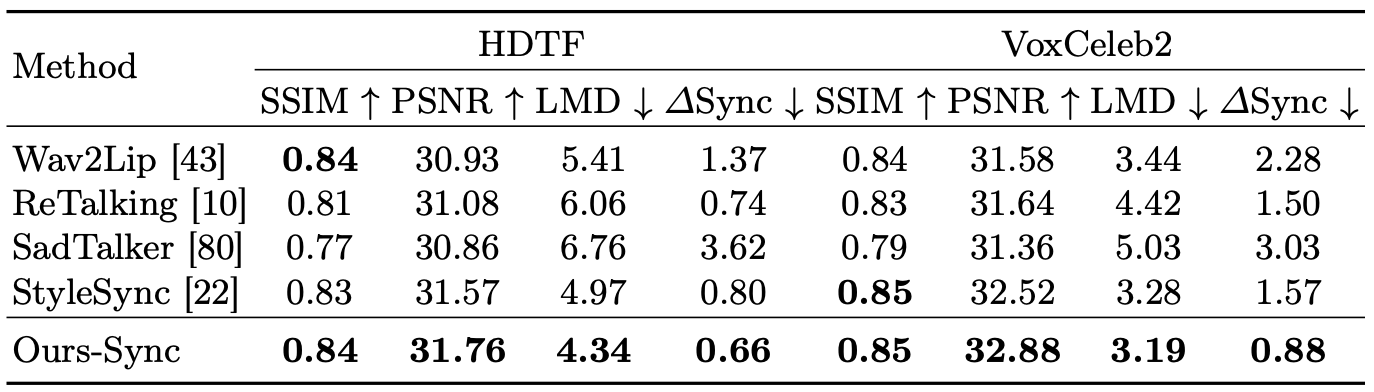
HDTF 和 VoxCeleb2 的定量结果。对于 LMD 和 ∆Sync,越低越好,对于其他则越高越好。
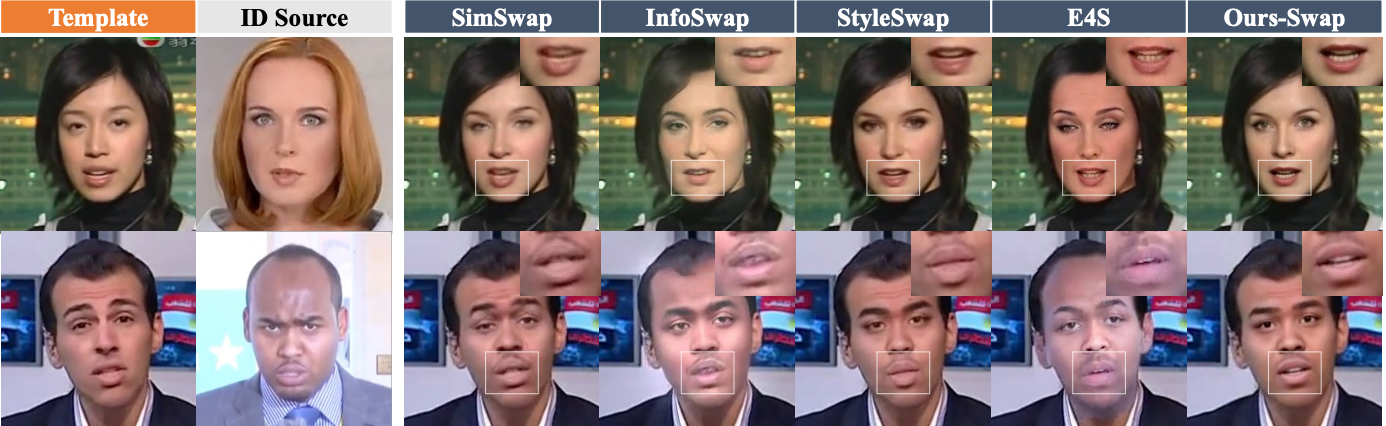
换脸的定性结果。 身份交换的结果应该保留模板的表情和唇动。

换脸口型同步的结果。ID 交换结果由给定的音频驱动。我们将其与口型同步和换脸中的两种 SOTA 方法的组合进行了比较。我们的方法生成的结果以更好的保真度保留了细节,同时保持了与源相似的说话风格。
消融实验

消融实验。(a)3D 面部网格提供详细的空间引导,实现卓越的口型同步。(b)具有面部器官形状的网格也增强了换脸中的身份传输。
结论
本文重点介绍了 ReSyncer 框架的几个重要特性:
- 易于重新配置的特性进一步揭示了广泛研究的结构的潜力,从而可以实现具有网格表示的高质量广义口型同步结果。
- 我们的框架旨在采用外部身份信息,因此我们实现了与现有技术相当的换脸能力,同时将口型同步能力保持在一个统一的模型内。
- 网络支持说话风格转换、视频驱动的面部动画,并可应用于实时直播。这些特性互补地满足了不同情况下虚拟表演者创作的各种需求。















 4386
4386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









