






1引言
Matlab是一款高性能的数值计算和可视化软件,集成数值分析、矩阵计算、信号运算、信号处理和图形显示于一体,构成了一个方便的、界面友好的用户环境。目前,基于Matlab的语音识别开发平台虽然在可读性、可移植性和可扩充性上优于其它编程语言,且调试功能强大、数据库函数丰富,可使研究人员“站在巨人的肩上”更加直观、方便地进行分析、计算与设计工作,从而大大地节省了时间[1]。但考虑到其执行代码速度低下,不能直接与硬件底层直接接触等缺点,因此提出了采用Matlab和VC++混合编程来搭建语音识别实验平台,并对传统Viterbi算法进行变形,直接使用FPGA的加法器、比较器和逻辑操作来计算观察值序列,以实现一种简单的嵌入式语音模板匹配。
2基于HMM的语音识别
2.1语音识别系统
语音识别系统(SpeechRecognitionSystem,SRS)基本上是一个模式分类的任务,即通过训练,系统能够把输入的语音按一定模式进行分类[2]。实验在Matlab7.0系统上建立了一个简单的基于隐马尔可夫模型(HiddenMarkovModel,HMM)的语音识别过程,如图1。
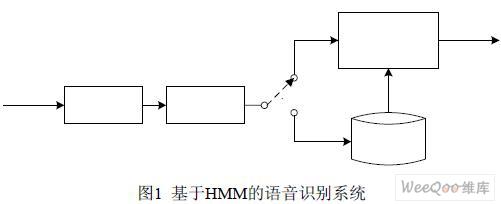
(1)语音输入:在一般实验室环境下进行语音信号采样,采样格式为PCM,采样频率16KHZ,A/D的量化精度8Bit。然后经过去噪、预加重、分帧、加窗等处理过程,去掉语音信号中包含的大量冗余信息,加强语音信号的高频共振峰,便于进行频谱分析。
(2)端点检测:考虑到语音信号的录制是在较为安静的实验室环境下进行,利用过零率Z来检测清音,用短时能量E来检测浊音,两者配合实现可靠的端点检测[3]。
(3)特征提取和量化:对有效语音段进行特征提取,即提取基于Mel刻度的倒频谱矢量(MelFrequencyCepstrumCoefficients,MFCC),它是识别过程中的输入特征值。特征值经矢量量化VectorQuantization,VQ),输出VQ码本类别号,即HMM训练与识别阶段使用的观察值序列o。
(4)模型训练与语音识别:训练阶段,系统采用一系列训练观察值估计HMM参数,

2.2Viterbi算法
由于计算复杂度的限制,对于基于HMM的实时语音识别来说,需要设计一个高效的硬件结构来执行Viterbi译码过程,以加速HMM的识别过程。考虑了FPGA的特点,分别采用对数概率和状态概率的最小路径对传统的Viterbi算法进行变形,其计算P(o|λ)v的过程如下[5]:

通过上面的变形,不仅可以使传统Viterbi算法中的乘法转成加法,降低时间消化,有效地避免数据下溢的问题。而且随着Viterbi计算过程的进行,已计算的状态概率值随之增加,改原来找结束概率的最大值为最小值[6]。因此,只需要计算T时刻的概率Tδ(i),它是大于前参考单词模型的最小值Pv的。
实验将直接使用FPGA的加法器、比较器和逻辑操作来实现上述公式(2)和公式(3),可以显著提高系统效率,系统结构如下图2。
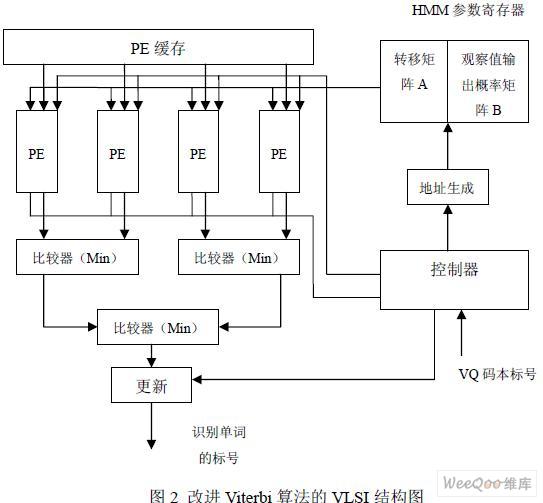
在这一方案中,识别过程直接由FPGA芯片内的逻辑块从观察序列中计算概率得分,其中,观察值序列通过VQ得出。系统包括了两个用来存储转移矩阵A和输出概率矩阵B的存储器,一个处理单元(ProcessingElement,PE)阵列,控制器,地址生成和附加比较逻辑。PE包括有Viterbi算法的核心模块加-比-选单元(Add-Compare-SelectUnit,ACSU),状态累加器,和用来比较(i)Tδ和极值Pv的附加比较器。PE从HMM参数寄存器中取出参考模型,沿最小路径计算其概率,然后与极值Pv进行比较。当(i)Tδ大于Pv时,控制器在下一状态时使PE操作无效;同时,控制器控制存储器缓冲操作,并生成整个计算过程中的控制信号。
3VC++和Matlab混合编程
对于在FPGA上实现语音识别的核心模块——Viterbi算法时,有许多工作需要在实验前完成,如定制硬件源代码、转换浮点数据为定点数据和电路仿真等。为减少这部分工作,采用软硬件协同设计的思想,由软件来执行HMM模型训练和其它识别过程(如MFCC、VQ等)。在实验时,用软件来执行HMM模型训练和语音单词识别。然后,把实验数据(语音数据和HMM模型参数)转换成定点数据格式,由PCI设备驱动程序将实验数据、源代码等下载到硬件,用于FPGA验证平台。
根据上述思想,采用Matlab和VC++混合编制PCI设备驱动程序,利用Matlab系统提供的外部程序调用接口MEX文件来实现其于VC++的混合编程。MEX文件是一种约定格式编写的文件,使用C语言或FOTRAN语言编写,是由Matlab解释器自动调用并执行的动态链接函数(DynamicLinkLibraryFunction),它在Mac下以.mex为后缀名,在Windows下即.dll文件。基于C语言的MEX文件主要由两部分组成,第一部分称为入口子程序,其作用是在Matlab系统与被调用的外部子程序间建立通信联系。第二部分称为计算功能子程序,它包含所有实际需要完成的功能的源代码,由入口子程序调用[7]。
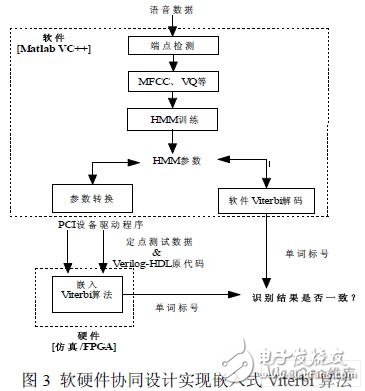
该方法可以在软硬件之间达到一致的识别结果,其方案描述如图3所示。实验中,计算由FPGA硬件完成,该子程序的主要负责FPGA与PCI的数据传递,即PCI设备驱动。通过MEX文件,不仅可在Matlab系统中像调用内建函数一样调用存在的算法,使资源得到充分利用,避免重复程序设计。同时,还可以对硬件直接进行编程,弥补Matlab的不足。
4实验
该语音识别实验采用的硬件平台是包括有AlteraCyclone系列EP1C12的FPGA和PCI9054芯片的PCI开发板。EP1C的FPGA负责硬件Viterbi计算,PCI9054在驱动程序的帮助下负责PC和FPGA间实验数据和结果的传输。
由于FPGA的空间限制,实验选择了4状态的HMM模型和容量64的VQ码本,占用FPGA的LE(逻辑单元)1,125个,存储单元占用约132K位。然后将.sof目标文件下载到PCI卡上的FPGA芯片中运行,在Matlab中调用VC++编写的PCI设备驱动程序,将VQ后的语音数据和HMM模型参数传送给FPGA内的Viterbi译码电路,实验中,通过驱动程序输出模板标号与实际语音的标号及仿真实验导出的标号一致。
在P43.0GHz的PC机和200MHzFPGA验证平台上,对于约100帧的单个语音文件识别而言,软/硬件Viterbi算法的耗时如下表1所示。

由上述实验结果证明了该Viterbi算法的VLSI结构能够准确且快速地实现语音识别的解码过程,满足嵌入式计算精度要求,表明该实现方案是切实可行的。
5结束语
采用Matlab、VC++和FPGA搭建了一个软硬件协同的语音识别实验研究平台,以VC++来弥补Matlab不能与硬件底层进行直接接触的不足。并在传统Viterbi算法基础上,对其采取一定变形,直接使用FPGA的加法器、比较器和逻辑操作建立Viterbi算法的VLSI结构,来计算观察值序列,以实现一种简单的基于HMM语音识别的模板匹配。采用这种软硬件协同的实验研究平台,可在利用前面Matlab的实验成果基础上,逐步实现语音识别各功能模块的嵌入式设计,减少工作量,并易于调试。














 831
831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









