






 本文介绍了SPSS的基本使用方法,包括软件定义、功能、运行方式和主界面结构。详细讲解了变量处理,如定义、命名规则、类型、长度、标签和缺失值处理。此外,还阐述了数据输入、保存、编辑、排序、分类汇总以及缺失值替代的操作。最后,讨论了变量操作,如生成新变量、加权处理和数据文件的合并与分组。
本文介绍了SPSS的基本使用方法,包括软件定义、功能、运行方式和主界面结构。详细讲解了变量处理,如定义、命名规则、类型、长度、标签和缺失值处理。此外,还阐述了数据输入、保存、编辑、排序、分类汇总以及缺失值替代的操作。最后,讨论了变量操作,如生成新变量、加权处理和数据文件的合并与分组。
一:spss
1:定义:
社会科学统计软件包,这是为了强调其社会科学应用的一面(因为社会科学研究中的许多现象是随机的,要使用统计学和概率论的定理来进行研究
2:基本功能:
数据管理,统计分析,图表分析,输出管理
3:3种运行方式:
批处理方式
完全窗口菜单运行方式(常用)
程序运行方式
4主界面有两个:
一个是spss数据编辑窗口,另一个是spss输出窗口
数据编辑窗口:由标题栏,菜单栏,工具栏,编辑栏,变量名栏,内容区,窗口切换标签页和状态栏组成
结果输出窗口:它是显示和管理spss统计分析结果 ,报表以及图形的窗口, 读者可以将此窗口种的内容以结果文件.spo的形式保存
结果输出部分分成左右两个部分,左边部分是索引输出区,用于显示已有的分析结果标题和内容索引;右边部分是各个分析的具体结果,成为详解输出区
5:spss的帮助系统
在运行spss的任何时候, 单击"help"菜单种的"主题"命令,会弹出帮助主题窗口,在其中选择相关的命令,即可得到所需的各种帮助
二:变量处理:
spss对数据的处理是以变量为前提的
输入数据前首先要定义变量,定义变量既要定义变量名,变量类型,变量长度(小数位数),变量标签(或值标签),变量的格式
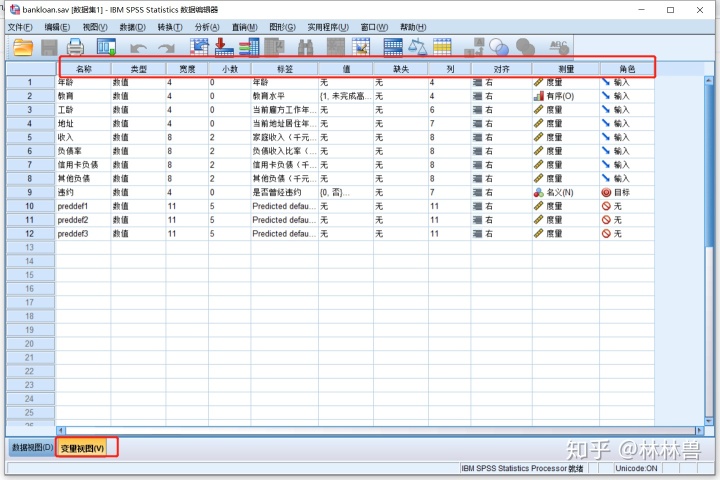
1:变量的定义和命名标准:
窗口中每一行表示一个变量的定义信息,包括名称、类型、宽度、小数、标签、值、缺失、列、对齐、度量标准等。
SPSS默认的变量为Var00001、Var00002等,用户也可以根据自己的需要来命名变量。SPSS变量的命名和一般的编程语言一样, 有一-定的命名规则,具体内容;如下。
● 变量名必须以字母、汉字或字符@开头,其他字符可以是任何字母、数字或_、@、#、$等符号。
● 变量最后一个字符不能是句号。
● 变量名总长度不能超过8个字符(即4个汉字)。
● 不能使用空白字符或其他特殊字符 (如“!”、“?”等)。
● 变量命名必须惟一,不能有两个相同的变量名。
● 在SPSS中不区分大小写。 例如,HXH、 hxh或Hxh对SPSS而言,均为同一变量名称。
● SPSS的保留字 (Reserved Keywords)不能作为变量的名称,如ALL、 AND、WITH、OR等。
2:变量类型:
单击类型响应单元中的按钮,弹出设置变量类型对话框,选择合适的变量类型并的单击"ok",即可定义变量类型
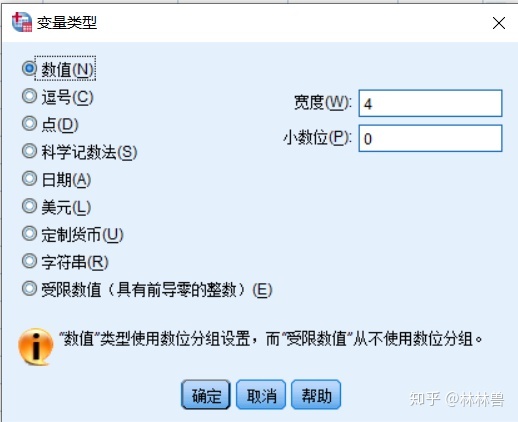
3变量长度:
设置变量的长度,当变量为日期型时无效
小数点位数
设置变量的小数点位数,当变量为日期型时无效
4变量标签:
变量标签是对变量名的进一步表述,便令只能由不超过8个字符组成,而8个字符经常不足以表示变量的含义,而变量标签可长达120个字符,变量标签可显示大小写,需要时可用变量标签对变量名的含义加以解释
5变量值:
变量值标签是对变量的每一个可能取值的进一步描述
6变量缺失值:
离散缺失值 连续缺失值
7变量度量标准:
变量按度量精度可以分为定性变量,定序变量,定距变量和定比变量
如果有多个变量的类型相同,可以先定义一个变量,然后把该变量的定义信息复制给新变量
三:数据的输入和保存
定义了所有变量后,单击"数据视图"标签,即可在出现的数据视图窗口输入数据
数据录入时可以逐行录入,也可以逐列
在录入数据时,应及时保存数据,防止数据的丢失,以便再次使用该数据
用户确定盘符、路径、文件名以及文件格式后单击“Save" 按钮,即可保存为指定类型的数据文件。SPSS支持的常见的数据文件存放格式如下。
SPSS(*. sav)
SPSS/PC+(*. sys)
SPSS Portable(*. por)
Tab delimited(*. dat)
Comma delimited(*. csv)
Fixed ASCII(*. dat)
Excel 2. 1(*. xls)
1-2-3 Rel 3.0(*. wk3)
SYLK(*. slk)
dBASE 4(*. dbf)
SAS v6 for Windows (*. sd2)
1:数据的编辑:
由于各种原因,已经输入的数据有时会需要修改,这就需要进行编辑,可以用方向键会鼠标将黑框移动到要修改的单元, 键入新值
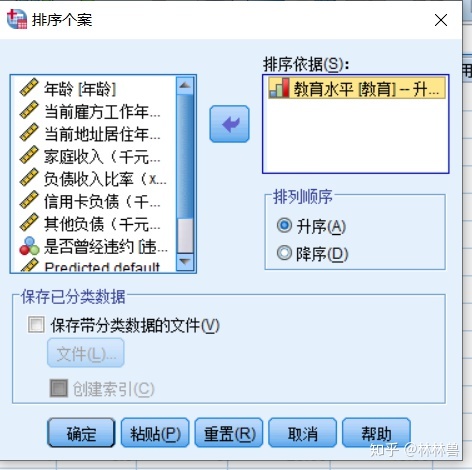
2:数据的排序和行列互换
方法:数据-->排序个案
3:选择个案子集:
数据--->选择个案--->选择 :如果条件满足,全部个案,随机个案样本,等几种方式

4:数据分类汇总:
用户还可以对数据编辑器中的数据按指定变量的数值进行归类分组汇总.
方法: 数据-->汇总--->分组变量:教育水平(教育)-->汇总变量:收入_mean-->确定

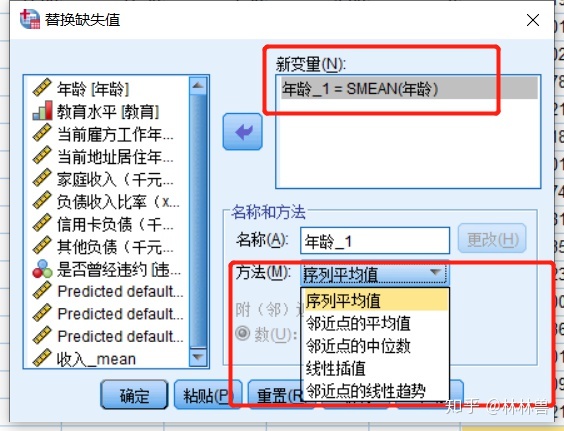
5:缺失值的替代:
对于缺失值,可采取多种手段进行科学替代,这里的缺失值必须是系统或用户指定的缺失值
方法:转换--->替换缺失值-->新变量:年龄--->方法:序列均值(等等方法)
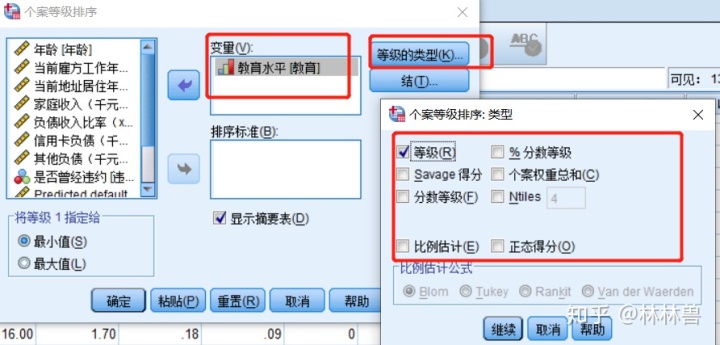
6:数据的个案排序:
方法:转换--->个案排秩-->变量:教育水平--->等级的类型:等级等选项-->确定
四:变量操作:
1:增加一个变量,即增加一个新的列: 方法:编辑栏--->插入变量
2:删除变量:
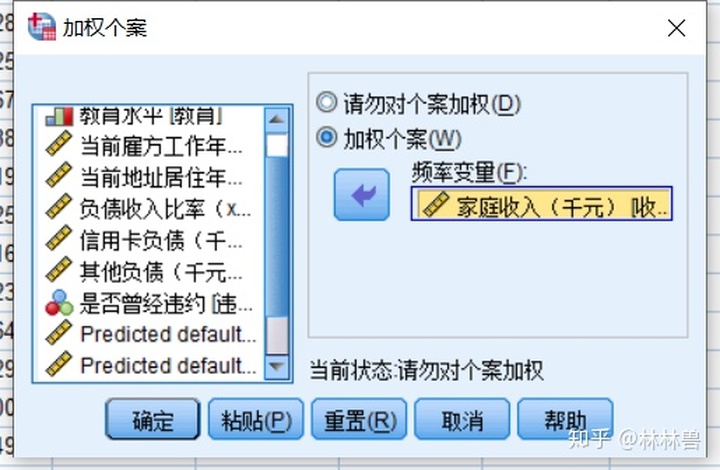
3:指定加权变量:
在实际的统计中,经常需要计算数据的加权平均数,例如,希望了超市中某天售出的商品的平均价格,如果仅以各种商品的单价平均数作为平均价格是不合理的,还应考虑到各种商品的销售量对平均价格的影响.因此,以商品的销售量作为权重计算各种商品单价的加权平均数,才是我们需要求的数据, 在spss处理中就需要将商品销售量作为加权变量
方法:数据--->加权个案--->选择加权个案--->频率变量选择
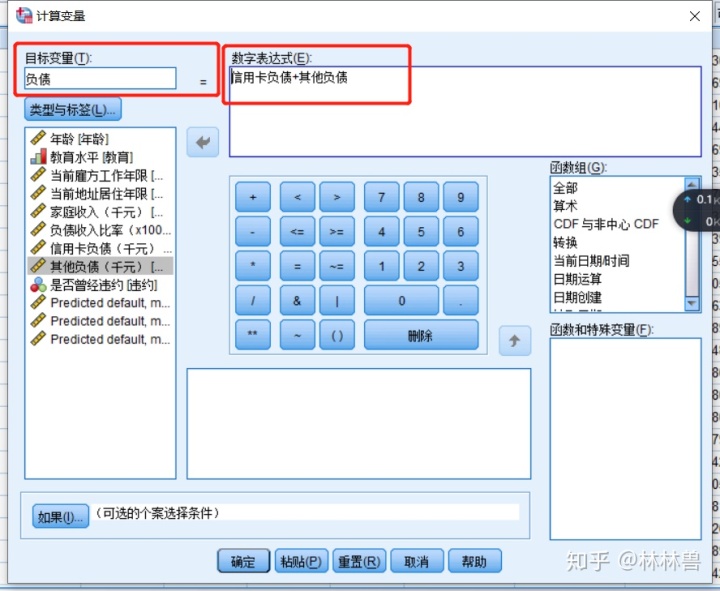
4:生成新变量:
在数据统计中,有时候经常需要通过数据转换来提示变量之间的真实关系
这是需要通过对已经存在的变量进行处理,从而生成新的变量
方法:转换-->计算变量-->目标变量:负债-->数字表达式:信用卡负债+其它负债-->确定
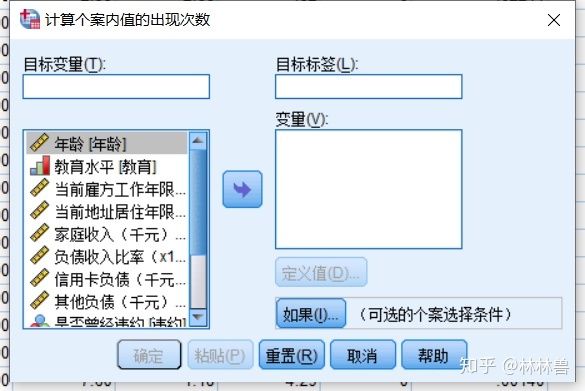
5:产生计数变量:
在统计过程中,往往需要进行一些计数工作,产生计数变量就是实现计数功能,它对所有个案或满足一定条件的个案,计算若干个变量中有几个变量的值落在指定的区间内,并将计数结果放在一个新变量中
方法:转化--->对个案内的值计数-->
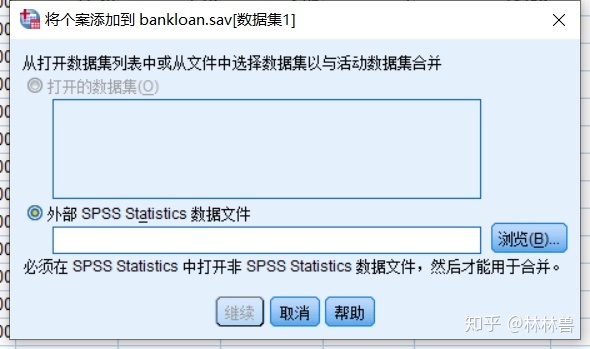
五:数据文件的合并和分组
统计分析的首要任务是将数据输入到计算机中,在数据量较大的时候,经常需要经一份大的数据文件分成几个小部分,分别由几个人输入,然后将若干个小的数据文件合并成一个大的数据文件,数据文件的合并有两种方式:纵向合并和横向合并
1:纵向合并就是将一个spss数据文件的内容追加到数据编辑窗口当前数据的后面,然后合并后的数据重新展示在数据编辑窗口中,
方法:数据-->合并文件-->添加个案
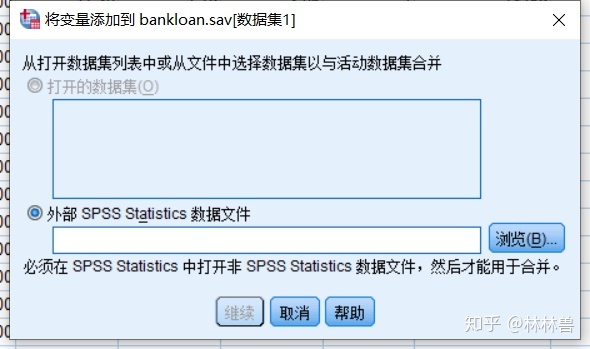
2:横向合并:横向连接,也就是变量值的合并,利用横向合并可以将两个或两个以上的具有相同个案的数据文件连在一起,连接到右边, 实现数据文件的横向链接,必须有一个相同的公共变量
方法: 数据--->合并文件--->添加变量
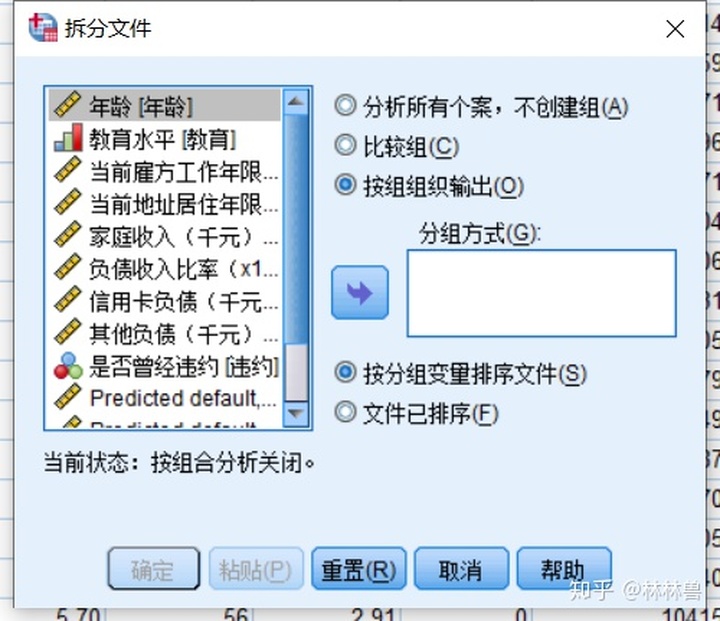
3:数据文件的分组
在统计中,经常需要先按某个变量进行分组,然年后再求各个组的统计分析
例如,想分别了解男生和女生的成绩情况,这时就需要按照性别变量,进行数据文件的分组(这种分析是系统内定义的,在数据管理器中并不一定明确体现,因此可称之为分割)
方法:数据--->拆分文件-->选择按组组织输出---->分组方式:教育水平--->确定

















 1791
1791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









