







前言
#坚持不一定会成功,但不坚持一定不会成功
#本期内容:多重线性回归模型
#由于导师最近布置了学习SPSS这款软件的任务,因此想来平台和大家一起交流下学习经验,这期推送内容接上一次高级教程第五章的学习笔记,希望能得到一些指正和帮助~
粉丝及官方意见说明
#针对官方爸爸的意见说的推送缺乏操作过程的数据案例文件澄清如下:1、操作演示的数据全部由我本人随意假设输进去的,重在演示操作;2、本人也只是在学习阶段,希望友友们能谅解哈,手里有数据的宝子当然更好啦,没有咱就自己假设数据练习一下也没多大关系的哈;3、我也会在后续教程中尽量增加一些数据的必要性说明;4、大家有什么好的意见也可以在评论区一起交流吖~
第六章一些学习笔记
- 多重线性回归模型:一个因变量(dependent variable,也称为反应变量或响应变量,response variable),多个自变量(Independent variable,也称为解释变量,explanatory variable);多重线性回归模型的适用条件:1、自变量与因变量之间存在线性关系(一般通过散点图考察,若出现曲线趋势可以用对数变换、倒数变换、平方根变换、平方根反正弦变换等方法);2、各观测间相互独立,任两个观测残差的协方差为零;3、残差服从N(0,d2),其中d越小,模型精度越高;4、残差的离散程度不随所有变量的取值水平改变而改变,即方程齐性。--统计分析高级教程(第三版)P101-102
- SPSS中衡量回归模型效果的指标有:1、复相关系数R【又称多元相关系数,值越大,线性相关关系越密切,若用其评价多重线性回归模型优劣时,即使增加的变量没有统计学意义,R值也会增大,范围(0,1)】;2、决定系数R2【与R值类似,范围[0,1]】;3、调整后的决定系数R2adj【解决了增加无统计学意义的变量R值增加的问题】;4、剩余标准差Sy,1,2..p【反应了模型精度,值越小,模型预测效果越好】;5、赤池信息准则AIC(Akaike’s information criterion)【由两部分组成,一部分反应模型精度,另一部分反应反应模型复杂程度,值越小说明模型既精度又简洁】;6、Cp统计量;7、其他标准【贝叶斯信息准则(Bayes’ information criterion,BIC),施瓦茨信息准则(Schwarz’s information criterion)】。--统计分析高级教程(第三版)P106-108
- SPSS中将模型用于预测的方法:1、手工计算预测值【效率低】;2、存储预测值;3、将模型存储为PMML格式用于预测。--统计分析高级教程(第三版)P110
- SPSS中的五种残差类型:1、未标准化残差(unstandardized residuals);2、标准化残差(standardized residuals),也称Pearson残差,半学生化残差(semi-studentized residuals);3、学生化残差(studentized residuals);4、剔除残差(deleted residuals);4、学生化剔除残差(studentized deleted residuals)。--统计分析高级教程(第三版)P111-112
- SPSS中逐步回归的方法对于小样本的数据应用,结果不稳定,若获得的模型主要用于预测,则可适当多一些自变量,不推荐直接使用逐步回归得到的简化模型进行预测。--统计分析高级教程(第三版)P115
- SPSS中常用的逐步回归方法有:1、进入法【enter】;2、向前法和向后法【forward and backward】;3、逐步回归法【stepwise,比较负责任的方法】;4、删除法【remove】。--统计分析高级教程(第三版)P116
- SPSS中几种强影响点统计量:1、DfBeta;2、标准化DfBeta;3、DfFit;4、标准化DfFit【以上四个值越大,越可能为强影响点,对于第四个,当值大于2时,即可认定为强影响点】;5、协方差比率(covariance ratio);相关强影响点的处理也分为5步。--统计分析高级教程(第三版)P120-121
- 存在多重共线性的模型表现:1、整个模型的检验结果P≤alpha,但各自的偏回归系数检验却P>alpha;2、专业上有意义,但检验结果没有;3、自变量的偏回归系数的取值大小甚至符号明显与实际相违背,难以解释;4、增加或删除一个自变量或案例,自变量偏回归系数发生较大变化。--统计分析高级教程(第三版)P121
- SPSS共线性问题的处理方法有:1、逐步回归法;2、岭回归法;3、主成分回归法【会有信息丢失,但自变量间的共线性问题越大,丢失的信息越少】;对回归模型结果解释还需注意四个问题:1、研究类型;2、背景条件;3、模型中自变量的数据来源;4、进行预测时需要保证自变量的取值范围任在观测的取值范围内,不能随意外延。--统计分析高级教程(第三版)P123
第六章一些操作方法
多重线性回归模型
分析步骤:1、绘制散点图,观察变量间的关联趋势;2、考察数据的分布,进行必要的预处理;3、进行直线回归分析;4、残差分析;5、强影响点的诊断及多重共线性问题的判断。
绘制散点图
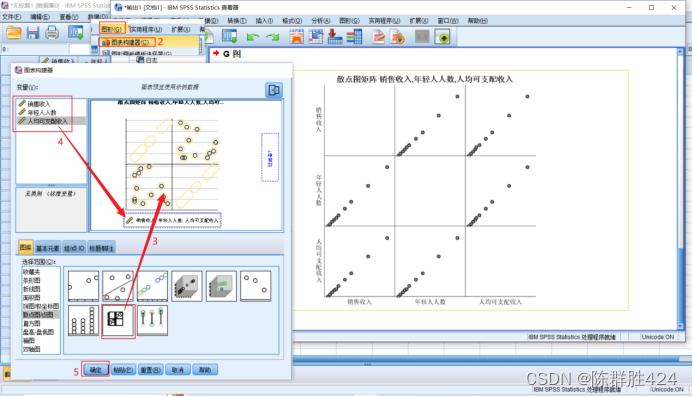
可以看出,基本呈现线性关系
下面进行拟合多重线性回归模型


下面进行回归模型的假设检验
SSR回归平方和(regression sum of square),表示能被自变量解释的模型中的部分变异
SSE误差平方和(error sum of aquare),表示表示不能被自变量解释的模型中的部分变异
平方和SS=SSR+SSE
均方MSR=SSR/p

这里P值小于0.001,说明拒绝原假设【所有自变量的偏回归系数均为零】,所建立的模型有统计学意义
下面进行偏回归系数的假设检验(检验某个自变量与因变量是否存在线性关系)

下面比较模型中多个自变量对模型的重要性,首先将偏回归系数进行标准化

需要注意的是,偏回归系数大,其标准化的系数不一定更大
实际工作中,往往需知道每个自变量的相对重要性,及其重要性在模型中所占的百分比【教材这里是通过R插件实现的,后面会介绍平均增量R方的方法】
模型预测值保存

存储预测值

将模型存储为PMML(predictive model markup language,模型标记语言)格式用于预测


保存残差

如何进行残差分析
1、绘制(非标准化)残差与该自变量的散点图(年轻人人数,人均可支配收入),用来判断自变量与因变量是否存在线性关系,效率高于散点图矩阵


看出基本没什么偏正和偏负,说明线性关系是正确的
2、判断个案Case间是否独立,即任意两个Case间的协方差为0

3、考察残差是否服从正态分布(绘制标准化残差直方图、茎叶图、Q-Q图等)

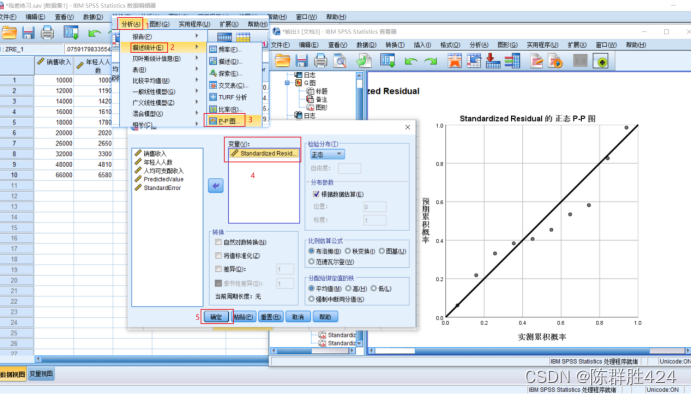
4、考察方差齐性(标准化残差的预测值与标准化残差的散点图)


可以看出无论标准化预测值如何变动,标准化残差的波动范围基本保持稳定
逐步回归


剩余两个变量由于我数据假设的不合理被剔除了
模型的进一步诊断与修正
通过残差诊断强影响点

强影响点统计量

多重共线性的诊断


自动线性建模
操作界面介绍

生成更高精度的预测模型


结束语
#好啦~,以上就是我SPSS第二十四期学习笔记——高级教程第六章的学习情况啦~,希望能与大家交流学习经验,共同进步吖~
#考虑高级教程的难度与深度,主要是内容太多辣,后续依然会尽力更新内容~争取日更!
#也非常感谢大家对我的一路陪伴,宝子们的关注、支持和打赏就是up儿不断更新滴动力,我近期也会坚持学习SPSS,更新相应的学习内容及笔记到平台上,咱们下期高级教程不见不散~














 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









